` and `` in the embed code below:
```html
```
The embed code above can also be found in the [Cloudflare dashboard](https://dash.cloudflare.com/?to=/:account/stream).
### Next steps
* [Secure your stream](https://developers.cloudflare.com/stream/viewing-videos/securing-your-stream/)
* [View live viewer counts](https://developers.cloudflare.com/stream/getting-analytics/live-viewer-count/)
## Accessibility considerations
To make your video content more accessible, include [captions](https://developers.cloudflare.com/stream/edit-videos/adding-captions/) and [high-quality audio recording](https://www.w3.org/WAI/media/av/av-content/).
.cloudflarestream.com//webRTC/publish"
},
"webRTCPlayback": {
"url": "https://customer-.cloudflarestream.com//webRTC/play"
},
...
}
```
## Step 2: Go live using WHIP
Every live input has a unique URL that one creator can be stream to. This URL should *only* be shared with the creator — anyone with this URL has the ability to stream live video to this live input.
Copy the URL from the `webRTC` key in the API response (see above), or directly from the [Cloudflare Dashboard](https://dash.cloudflare.com/?to=/:account/stream/inputs).
Paste this URL into the example code.
```javascript
// Add a {JSON.stringify(results)}
Product description goes here.
$0.00
0 in stock
{session.user?.name || 'No name set'}
{session.user?.email}
User ID: {session.user?.id}
Hi ${name},
Your message was received.
`, }); // If the message was sent successfully, return a 200 response if (sendResend.data) { return new Response( JSON.stringify({ message: `Message successfully sent!`, }), { status: 200, statusText: "OK", }, ); // If there was an error sending the message, return a 500 response } else { return new Response( JSON.stringify({ message: `Message failed to send: ${sendResend.error}`, }), { status: 500, statusText: `Internal Server Error: ${sendResend.error}`, }, ); } }; ``` Note Make sure to change the 'to' property in 'resend.emails.send' function, if you set up your own domain in step 2. If you skipped that step, keep the value ' ```
In the URL path used in this example, the `src` attribute is for images with the usual "1x" density. `/cdn-cgi/image/` is a special path for resizing images. This is followed by `width=960` which resizes the image to have a width of 960 pixels. `/assets/product.jpg` is a URL to the source image on the server.
The `srcset` attribute adds another, high-DPI image. The browser will automatically select between the images in the `src` and `srcset`. In this case, specifying `width=1920` (two times 960 pixels) and adding `2x` at the end, informs the browser that this is a double-density image. It will be displayed at the same size as a 960 pixel image, but with double the number of pixels which will make it look twice as sharp on high-DPI displays.
Note that it does not make sense to scale images up for use in `srcset`. That would only increase file sizes without improving visual quality. The source images you should use with `srcset` must be high resolution, so that they are only scaled down for `1x` displays, and displayed as-is or also scaled down for `2x` displays.
### `srcset` for responsive images
When you want to display an image that takes a certain percentage of the window or screen width, the image should have dimensions that are appropriate for a visitor’s screen size. Screen sizes vary a lot, typically from 320 pixels to 3840 pixels, so there is not a single image size that fits all cases. With `
```
In the URL path used in this example, the `src` attribute is for images with the usual "1x" density. `/cdn-cgi/image/` is a special path for resizing images. This is followed by `width=960` which resizes the image to have a width of 960 pixels. `/assets/product.jpg` is a URL to the source image on the server.
The `srcset` attribute adds another, high-DPI image. The browser will automatically select between the images in the `src` and `srcset`. In this case, specifying `width=1920` (two times 960 pixels) and adding `2x` at the end, informs the browser that this is a double-density image. It will be displayed at the same size as a 960 pixel image, but with double the number of pixels which will make it look twice as sharp on high-DPI displays.
Note that it does not make sense to scale images up for use in `srcset`. That would only increase file sizes without improving visual quality. The source images you should use with `srcset` must be high resolution, so that they are only scaled down for `1x` displays, and displayed as-is or also scaled down for `2x` displays.
### `srcset` for responsive images
When you want to display an image that takes a certain percentage of the window or screen width, the image should have dimensions that are appropriate for a visitor’s screen size. Screen sizes vary a lot, typically from 320 pixels to 3840 pixels, so there is not a single image size that fits all cases. With ` ```
In the previous case, the number followed by `x` described *screen* density. In this case the number followed by `w` describes the *image* size. There is no need to specify screen density here (`2x`, etc.), because the browser automatically takes it into account and picks a higher-resolution image when necessary.
If the image is not displayed at full width of the screen (or browser window), you have two options:
* If the image is displayed at full width of a fixed-width column, use the first technique that uses one specific image size.
* If it takes a specific percentage of the screen, or stretches to full width only sometimes (using CSS media queries), then add the `sizes` attribute as described below.
#### The `sizes` attribute
If the image takes 50% of the screen (or window) width:
```html
```
In the previous case, the number followed by `x` described *screen* density. In this case the number followed by `w` describes the *image* size. There is no need to specify screen density here (`2x`, etc.), because the browser automatically takes it into account and picks a higher-resolution image when necessary.
If the image is not displayed at full width of the screen (or browser window), you have two options:
* If the image is displayed at full width of a fixed-width column, use the first technique that uses one specific image size.
* If it takes a specific percentage of the screen, or stretches to full width only sometimes (using CSS media queries), then add the `sizes` attribute as described below.
#### The `sizes` attribute
If the image takes 50% of the screen (or window) width:
```html
 ```
### Eager loading
If you have images that are in the viewport, eager loading, instead of lazy loading, is recommended. Eager loading loads the asset at the initial page load, regardless of its location on the page.
Example of modifying the `loading` attribute of your `
```
```
### Eager loading
If you have images that are in the viewport, eager loading, instead of lazy loading, is recommended. Eager loading loads the asset at the initial page load, regardless of its location on the page.
Example of modifying the `loading` attribute of your `
```
This is the regular content everyone sees.
`; return new Response(html, { headers: { "Content-Type": "text/html; charset=utf-8" } }); } } satisfies ExportedHandlerProject Name: ${projectResponse.result.name}
`; content += `Project ID: ${projectResponse.result.id}
`; content += `Pages Subdomain: ${projectResponse.result.subdomain}
`; content += `Domains: ${projectResponse.result.domains}
`; content += `Latest preview: ${projectResponse.result.canonical_deployment.url}
`; content += `Deployment: ${deployment.id}
`; } let html = `.cloudflarestream.com//views
```
Below is a response for a live video with several active viewers:
```json
{ "liveViewers": 113 }
```
.cloudflarestream.com/ea95132c15732412d22c1476fa83f27a/manifest/video.m3u8",
"dash": "https://customer-.cloudflarestream.com/ea95132c15732412d22c1476fa83f27a/manifest/video.mpd"
},
"preview": "https://customer-.cloudflarestream.com/ea95132c15732412d22c1476fa83f27a/watch",
"readyToStream": true,
"requireSignedURLs": true,
"size": 4190963,
"status": {
"state": "ready",
"pctComplete": "100.000000",
"errorReasonCode": "",
"errorReasonText": ""
},
"thumbnail": "https://customer-.cloudflarestream.com/ea95132c15732412d22c1476fa83f27a/thumbnails/thumbnail.jpg",
"thumbnailTimestampPct": 0.529241,
"creator": "some-creator-id",
"uid": "ea95132c15732412d22c1476fa83f27a",
"liveInput": "fc0a8dc887b16759bfd9ad922230a014",
"uploaded": "2014-01-02T02:20:00Z",
"watermark": {
"uid": "ea95132c15732412d22c1476fa83f27a",
"size": 29472,
"height": 600,
"width": 400,
"created": "2014-01-02T02:20:00Z",
"downloadedFrom": "https://company.com/logo.png",
"name": "Marketing Videos",
"opacity": 0.75,
"padding": 0.1,
"scale": 0.1,
"position": "center"
}
}
],
"total": "35586",
"range": "1000"
}
```
## tus
Add the Creator ID via the `Upload-Creator` header. For more information, refer to [Resumable and large files (tus)](https://developers.cloudflare.com/stream/uploading-videos/resumable-uploads/#set-creator-property).
## Query by Creator ID with GraphQL
After you set the creator property, you can use the [GraphQL API](https://developers.cloudflare.com/analytics/graphql-api/) to filter by a specific creator. Refer to [Fetching bulk analytics](https://developers.cloudflare.com/stream/getting-analytics/fetching-bulk-analytics) for more information about available metrics and filters.
.cloudflarestream.com//manifest/video.m3u8?dvrEnabled=true
```
Custom players using a DVR-capable HLS manifest may need additional configuration to surface helpful controls or information. Refer to your player library for additional information.
## Video ID or Input ID
Stream Live allows loading the Player or HLS manifest by Video ID or Live Input ID. Refer to [Watch a live stream](https://developers.cloudflare.com/stream/stream-live/watch-live-stream/) for how to retrieve these URLs and compare these options. There are additional considerations when using DVR mode:
**Recommended:** Use DVR Mode on a Video ID URL:
* When the player loads, it will start playing the active broadcast if it is still live or play the recording if the broadcast has concluded.
DVR Mode on a Live Input ID URL:
* When the player loads, it will start playing the currently live broadcast if there is one (refer to [Live Input Status](https://developers.cloudflare.com/stream/stream-live/watch-live-stream/#live-input-status)).
* If the viewer is still watching *after the broadcast ends,* they can continue to watch. However, if the player or manifest is then reloaded, it will show the latest broadcast or "Stream has not yet started" (`HTTP 204`). Past broadcasts are not available by Live Input ID.
## Known Limitations
* When using DVR Mode and a player/manifest created using a Live Input ID, the player may stall when trying to switch quality levels if a viewer is still watching after a broadcast has concluded.
* Performance may be degraded for DVR-enabled broadcasts longer than three hours. Manifests are limited to a maxiumum of 7,200 segments. Segment length is determined by the keyframe interval, also called GOP size.
* DVR Mode relies on Version 8 of the HLS manifest specification. Stream uses HLS Version 6 in all other contexts. HLS v8 offers extremely broad compatibility but may not work with certain old player libraries or older devices.
* DVR Mode is not available for DASH manifests.
.cloudflarestream.com//manifest/video.m3u8?duration=5m
```
* `duration` string duration of the preview, up to 5 minutes as either a number of seconds ("30s") or minutes ("3m")
When the preview manifest is delivered, inspect the headers for two properties:
* `preview-start-seconds` float seconds into the start of the live stream or recording that the preview manifest starts. Useful in applications that allow a user to select a range from the preview because the clip will need to reference its offset from the *broadcast* start time, not the *preview* start time.
* `stream-media-id` string the video ID of the live stream or recording. Useful in applications that render the player using an *input* ID because the clip URL should reference the *video* ID.
This manifest can be played and seeked using any HLS-compatible player.
### Reading headers
Reading headers when loading a manifest requires adjusting how players handle the response. For example, if using [HLS.js](https://github.com/video-dev/hls.js) and the default loader, override the `pLoader` (playlist loader) class:
```js
let currentPreviewStart;
let currentPreviewVideoID;
// Override the pLoader (playlist loader) to read the manifest headers:
class pLoader extends Hls.DefaultConfig.loader {
constructor(config) {
super(config);
var load = this.load.bind(this);
this.load = function (context, config, callbacks) {
if (context.type == 'manifest') {
var onSuccess = callbacks.onSuccess;
// copy the existing onSuccess handler to fire it later.
callbacks.onSuccess = function (response, stats, context, networkDetails) {
// The fourth argument here is undocumented in HLS.js but contains
// the response object for the manifest fetch, which gives us headers:
currentPreviewStart =
parseFloat(networkDetails.getResponseHeader('preview-start-seconds'));
// Save the start time of the preview manifest
currentPreviewVideoID =
networkDetails.getResponseHeader('stream-media-id');
// Save the video ID in case the preview was loaded with an input ID
onSuccess(response, stats, context);
// And fire the exisint success handler.
};
}
load(context, config, callbacks);
};
}
}
// Specify the new loader class when setting up HLS
const hls = new Hls({
pLoader: pLoader,
});
```
## Clip manifest
To play a clip of a live stream or recording, request a clip manifest with a duration and a start time, relative to the start of the live stream.
```txt
https://customer-.cloudflarestream.com//manifest/clip.m3u8?time=600s&duration=30s
```
* `time` string start time of the clip in seconds, from the start of the live stream or recording
* `duration` string duration of the clip in seconds, up to 60 seconds max
This manifest can be played and seeked using any HLS-compatible player.
## Clip MP4 download
An MP4 of the clip can also be generated dynamically to be saved and shared on other platforms.
```txt
https://customer-.cloudflarestream.com//clip.mp4?time=600s&duration=30s&filename=clip.mp4
```
* `time` string start time of the clip in seconds, from the start of the live stream or recording (example: "500s")
* `duration` string duration of the clip in seconds, up to 60 seconds max (example: "60s")
* `filename` string *(optional)* a filename for the clip
.cloudflarestream.com//iframe
```
A full embed code can be generated in Dash or with the API.
**HLS Manifest URL format:**
```plaintext
https://customer-.cloudflarestream.com//manifest/video.m3u8
```
You can also retrieve the embed code or manifest URLs from Dash or the API.
## Use the dashboard
To get the Stream built-in player embed code or HLS Manifest URL for a custom player:
1. Log in to your [Cloudflare dashboard](https://dash.cloudflare.com) and select your account.
2. Select **Stream** > **Live Inputs**.
3. Select a live input from the list.
4. Locate the **Embed** and **HLS Manifest URL** beneath the video.
5. Determine which option to use and then select **Click to copy** beneath your choice.
The embed code or manifest URL retrieved in Dash will reference the Live Input ID.
## Use the API
To retrieve the player code or manifest URLs via the API, fetch the Live Input's list of videos:
```bash
curl -X GET \
-H "Authorization: Bearer " \
https://api.cloudflare.com/client/v4/accounts//stream/live_inputs//videos
```
A live input will have multiple videos associated with it, one for each broadcast. If there is an active broadcast, the first video in the response will have a `live-inprogress` status. Other videos in the response represent recordings which can be played on-demand.
Each video in the response, including the active broadcast if there is one, contains the HLS and DASH URLs and a link to the Stream player. Noteworthy properties include:
* `preview` -- Link to the Stream player to watch
* `playback`.`hls` -- HLS Manifest
* `playback`.`dash` -- DASH Manifest
In the example below, the state of the live video is `live-inprogress` and the state for previously recorded video is `ready`.
```json
{
"result": [
{
"uid": "6b9e68b07dfee8cc2d116e4c51d6a957",
"thumbnail": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/thumbnails/thumbnail.jpg",
"status": {
"state": "live-inprogress",
"errorReasonCode": "",
"errorReasonText": ""
},
"meta": {
"name": "Stream Live Test 23 Sep 21 05:44 UTC"
},
"created": "2021-09-23T05:44:30.453838Z",
"modified": "2021-09-23T05:44:30.453838Z",
"size": 0,
"preview": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/watch",
...
"playback": {
"hls": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/manifest/video.m3u8",
"dash": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/manifest/video.mpd"
},
...
},
{
"uid": "6b9e68b07dfee8cc2d116e4c51d6a957",
"thumbnail": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/thumbnails/thumbnail.jpg",
"thumbnailTimestampPct": 0,
"readyToStream": true,
"status": {
"state": "ready",
"pctComplete": "100.000000",
"errorReasonCode": "",
"errorReasonText": ""
},
"meta": {
"name": "CFTV Staging 22 Sep 21 22:12 UTC"
},
"created": "2021-09-22T22:12:53.587306Z",
"modified": "2021-09-23T00:14:05.591333Z",
"size": 0,
"preview": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/watch",
...
"playback": {
"hls": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/manifest/video.m3u8",
"dash": "https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/manifest/video.mpd"
},
}
],
}
```
These will reference the Video ID.
## Live input status
You can check whether a live input is currently streaming and what its active video ID is by making a request to its `lifecycle` endpoint. The Stream player does this automatically to show a note when the input is idle. Custom players may require additional support.
```bash
curl -X GET \
-H "Authorization: Bearer " \
https://customer-.cloudflarestream.com//lifecycle
```
In the example below, the response indicates the `ID` is for an input with an active `videoUID`. The `live` status value indicates the input is actively streaming.
```json
{
"isInput": true,
"videoUID": "55b9b5ce48c3968c6b514c458959d6a",
"live": true
}
```
```json
{
"isInput": true,
"videoUID": null,
"live": false
}
```
When viewing a live stream via the live input ID, the `requireSignedURLs` and `allowedOrigins` options in the live input recording settings are used. These settings are independent of the video-level settings.
## Live stream recording playback
After a live stream ends, a recording is automatically generated and available within 60 seconds. To ensure successful video viewing and playback, keep the following in mind:
* If a live stream ends while a viewer is watching, viewers using the Stream player should wait 60 seconds and then reload the player to view the recording of the live stream.
* After a live stream ends, you can check the status of the recording via the API. When the video state is `ready`, you can use one of the manifest URLs to stream the recording.
While the recording of the live stream is generating, the video may report as `not-found` or `not-started`.
If you are not using the Stream player for live stream recordings, refer to [Record and replay live streams](https://developers.cloudflare.com/stream/stream-live/replay-recordings/) for more information on how to replay a live stream recording.
.cloudflarestream.com//downloads/default.mp4",
"percentComplete": 75.0
}
},
"success": true,
"errors": [],
"messages": []
}
```
## Get download links
You can view all available downloads for a video by making a `GET` HTTP request to the downloads API. The response for creating and fetching downloads are the same.
```bash
curl -X GET \
-H "Authorization: Bearer " \
https://api.cloudflare.com/client/v4/accounts//stream//downloads
```
```json
{
"result": {
"default": {
"status": "ready",
"url": "https://customer-.cloudflarestream.com//downloads/default.mp4",
"percentComplete": 100.0
}
},
"success": true,
"errors": [],
"messages": []
}
```
## Customize download file name
You can customize the name of downloadable files by adding the `filename` query string parameter at the end of the URL.
In the example below, adding `?filename=MY_VIDEO.mp4` to the URL will change the file name to `MY_VIDEO.mp4`.
`https://customer-.cloudflarestream.com//downloads/default.mp4?filename=MY_VIDEO.mp4`
The `filename` can be a maximum of 120 characters long and composed of `abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789-_` characters. The extension (.mp4) is appended automatically.
## Retrieve downloads
The generated MP4 download files can be retrieved via the link in the download API response.
```sh
curl -L https://customer-.cloudflarestream.com//downloads/default.mp4 > download.mp4
```
## Secure video downloads
If your video is public, the MP4 will also be publicly accessible. If your video is private and requires a signed URL for viewing, the MP4 will not be publicly accessible. To access the MP4 for a private video, you can generate a signed URL just as you would for regular viewing with an additional flag called `downloadable` set to `true`.
Download links will not work for videos which already require signed URLs if the `downloadable` flag is not present in the token.
For more details about using signed URLs with videos, refer to [Securing your Stream](https://developers.cloudflare.com/stream/viewing-videos/securing-your-stream/).
**Example token payload**
```json
{
"sub": ,
"kid": ,
"exp": 1537460365,
"nbf": 1537453165,
"downloadable": true,
"accessRules": [
{
"type": "ip.geoip.country",
"action": "allow",
"country": [
"GB"
]
},
{
"type": "any",
"action": "block"
}
]
}
```
## Billing for MP4 downloads
MP4 downloads are billed in the same way as streaming of the video. You will be billed for the duration of the video each time the MP4 for the video is downloaded. For example, if you have a 10 minute video that is downloaded 100 times during the month, the downloads will count as 1000 minutes of minutes served.
You will not incur any additional cost for storage when you enable MP4s.
.cloudflarestream.com/eyJhbGciOiJSUzI1NiIsImtpZCI6ImNkYzkzNTk4MmY4MDc1ZjJlZjk2MTA2ZDg1ZmNkODM4In0.eyJraWQiOiJjZGM5MzU5ODJmODA3NWYyZWY5NjEwNmQ4NWZjZDgzOCIsImV4cCI6IjE2MjE4ODk2NTciLCJuYmYiOiIxNjIxODgyNDU3In0.iHGMvwOh2-SuqUG7kp2GeLXyKvMavP-I2rYCni9odNwms7imW429bM2tKs3G9INms8gSc7fzm8hNEYWOhGHWRBaaCs3U9H4DRWaFOvn0sJWLBitGuF_YaZM5O6fqJPTAwhgFKdikyk9zVzHrIJ0PfBL0NsTgwDxLkJjEAEULQJpiQU1DNm0w5ctasdbw77YtDwdZ01g924Dm6jIsWolW0Ic0AevCLyVdg501Ki9hSF7kYST0egcll47jmoMMni7ujQCJI1XEAOas32DdjnMvU8vXrYbaHk1m1oXlm319rDYghOHed9kr293KM7ivtZNlhYceSzOpyAmqNFS7mearyQ/manifest/video.m3u8`
### Customizing default restrictions
If you call the `/token` endpoint without any body, it will return a token that expires in one hour. Let's say you want to let a user watch a particular video for the next 12 hours. Here's how you'd do it with a Cloudflare Worker:
```javascript
export default {
async fetch(request, env, ctx) {
const signed_url_restrictions = {
//limit viewing for the next 12 hours
exp: Math.floor(Date.now() / 1000) + 12 * 60 * 60,
};
const init = {
method: "POST",
headers: {
Authorization: "Bearer ",
"content-type": "application/json;charset=UTF-8",
},
body: JSON.stringify(signed_url_restrictions),
};
const signedurl_service_response = await fetch(
"https://api.cloudflare.com/client/v4/accounts/{account_id}/stream/{video_uid}/token",
init,
);
return new Response(
JSON.stringify(await signedurl_service_response.json()),
{ status: 200 },
);
},
};
```
The returned token will expire after 12 hours.
Let's take this a step further and add 2 additional restrictions:
* Allow the signed URL token to be used for MP4 downloads (assuming the video has downloads enabled)
* Block users from US and Mexico from viewing or downloading the video
To achieve this, we can specify additional restrictions in the `signed_url_restrictions` object in our sample code:
```javascript
export default {
async fetch(request, env, ctx) {
const signed_url_restrictions = {
//limit viewing for the next 2 hours
exp: Math.floor(Date.now() / 1000) + 12 * 60 * 60,
downloadable: true,
accessRules: [
{ type: "ip.geoip.country", country: ["US", "MX"], action: "block" },
],
};
const init = {
method: "POST",
headers: {
Authorization: "Bearer ",
"content-type": "application/json;charset=UTF-8",
},
body: JSON.stringify(signed_url_restrictions),
};
const signedurl_service_response = await fetch(
"https://api.cloudflare.com/client/v4/accounts/{account_id}/stream/{video_uid}/token",
init,
);
return new Response(
JSON.stringify(await signedurl_service_response.json()),
{ status: 200 },
);
},
};
```
## Option 2: Using a signing key to create signed tokens
If you are generating a high-volume of tokens, using [Live WebRTC](https://developers.cloudflare.com/stream/webrtc-beta/), or need to customize the access rules, generate new tokens using a signing key so you do not need to call the Stream API each time.
### Step 1: Call the `/stream/key` endpoint *once* to obtain a key
```bash
curl --request POST \
"https://api.cloudflare.com/client/v4/accounts/{account_id}/stream/keys" \
--header "Authorization: Bearer "
```
The response will return `pem` and `jwk` values.
```json
{
"result": {
"id": "8f926b2b01f383510025a78a4dcbf6a",
"pem": "LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFcEFJQkFBS0NBUUVBemtHbXhCekFGMnBIMURiWmgyVGoyS3ZudlBVTkZmUWtNeXNCbzJlZzVqemRKTmRhCmtwMEphUHhoNkZxOTYveTBVd0lBNjdYeFdHb3kxcW1CRGhpdTVqekdtYW13NVgrYkR3TEdTVldGMEx3QnloMDYKN01Rb0xySHA3MDEycXBVNCtLODUyT1hMRVVlWVBrOHYzRlpTQ2VnMVdLRW5URC9oSmhVUTFsTmNKTWN3MXZUbQpHa2o0empBUTRBSFAvdHFERHFaZ3lMc1Vma2NsRDY3SVRkZktVZGtFU3lvVDVTcnFibHNFelBYcm9qaFlLWGk3CjFjak1yVDlFS0JCenhZSVEyOVRaZitnZU5ya0t4a2xMZTJzTUFML0VWZkFjdGkrc2ZqMkkyeEZKZmQ4aklmL2UKdHBCSVJZVDEza2FLdHUyYmk0R2IrV1BLK0toQjdTNnFGODlmTHdJREFRQUJBb0lCQUYzeXFuNytwNEtpM3ZmcgpTZmN4ZmRVV0xGYTEraEZyWk1mSHlaWEFJSnB1MDc0eHQ2ZzdqbXM3Tm0rTFVhSDV0N3R0bUxURTZacy91RXR0CjV3SmdQTjVUaFpTOXBmMUxPL3BBNWNmR2hFN1pMQ2wvV2ZVNXZpSFMyVDh1dGlRcUYwcXpLZkxCYk5kQW1MaWQKQWl4blJ6UUxDSzJIcmlvOW1KVHJtSUUvZENPdG80RUhYdHpZWjByOVordHRxMkZrd3pzZUdaK0tvd09JaWtvTgp2NWFOMVpmRGhEVG0wdG1Vd0tLbjBWcmZqalhRdFdjbFYxTWdRejhwM2xScWhISmJSK29PL1NMSXZqUE16dGxOCm5GV1ZEdTRmRHZsSjMyazJzSllNL2tRVUltT3V5alY3RTBBcm5vR2lBREdGZXFxK1UwajluNUFpNTJ6aTBmNloKdFdvwdju39xOFJWQkwxL2tvWFVmYk00S04ydVFadUdjaUdGNjlCRDJ1S3o1eGdvTwowVTBZNmlFNG9Cek5GUW5hWS9kayt5U1dsQWp2MkgraFBrTGpvZlRGSGlNTmUycUVNaUFaeTZ5cmRkSDY4VjdIClRNRllUQlZQaHIxT0dxZlRmc00vRktmZVhWY1FvMTI1RjBJQm5iWjNSYzRua1pNS0hzczUyWE1DZ1lFQTFQRVkKbGIybDU4blVianRZOFl6Uk1vQVo5aHJXMlhwM3JaZjE0Q0VUQ1dsVXFZdCtRN0NyN3dMQUVjbjdrbFk1RGF3QgpuTXJsZXl3S0crTUEvU0hlN3dQQkpNeDlVUGV4Q3YyRW8xT1loMTk3SGQzSk9zUythWWljemJsYmJqU0RqWXVjCkdSNzIrb1FlMzJjTXhjczJNRlBWcHVibjhjalBQbnZKd0k5aUpGVUNnWUVBMjM3UmNKSEdCTjVFM2FXLzd3ekcKbVBuUm1JSUczeW9UU0U3OFBtbHo2bXE5eTVvcSs5aFpaNE1Fdy9RbWFPMDF5U0xRdEY4QmY2TFN2RFh4QWtkdwpWMm5ra0svWWNhWDd3RHo0eWxwS0cxWTg3TzIwWWtkUXlxdjMybG1lN1JuVDhwcVBDQTRUWDloOWFVaXh6THNoCkplcGkvZFhRWFBWeFoxYXV4YldGL3VzQ2dZRUFxWnhVVWNsYVlYS2dzeUN3YXM0WVAxcEwwM3h6VDR5OTBOYXUKY05USFhnSzQvY2J2VHFsbGVaNCtNSzBxcGRmcDM5cjIrZFdlemVvNUx4YzBUV3Z5TDMxVkZhT1AyYk5CSUpqbwpVbE9ldFkwMitvWVM1NjJZWVdVQVNOandXNnFXY21NV2RlZjFIM3VuUDVqTVVxdlhRTTAxNjVnV2ZiN09YRjJyClNLYXNySFVDZ1lCYmRvL1orN1M3dEZSaDZlamJib2h3WGNDRVd4eXhXT2ZMcHdXNXdXT3dlWWZwWTh4cm5pNzQKdGRObHRoRXM4SHhTaTJudEh3TklLSEVlYmJ4eUh1UG5pQjhaWHBwNEJRNTYxczhjR1Z1ZSszbmVFUzBOTDcxZApQL1ZxUWpySFJrd3V5ckRFV2VCeEhUL0FvVEtEeSt3OTQ2SFM5V1dPTGJvbXQrd3g0NytNdWc9PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=",
"jwk": "eyJ1c2UiOiJzaWciLCJrdHkiOiJSU0EiLCJraWQiOiI4ZjkyNmIyYjAxZjM4MzUxNzAwMjVhNzhhNGRjYmY2YSIsImFsZyI6IlJTMjU2IiwibiI6InprR214QnpBRjJwSDFEYlpoMlRqMkt2bnZQVU5GZlFrTXlzQm8yZWc1anpkSk5kYWtwMEphUHhoNkZxOTZfeTBVd0lBNjdYeFdHb3kxcW1CRGhpdTVqekdtYW13NVgtYkR3TEdTVldGMEx3QnloMDY3TVFvTHJIcDcwMTJxcFU0LUs4NTJPWExFVWVZUGs4djNGWlNDZWcxV0tFblREX2hKaFVRMWxOY0pNY3cxdlRtR2tqNHpqQVE0QUhQX3RxRERxWmd5THNVZmtjbEQ2N0lUZGZLVWRrRVN5b1Q1U3JxYmxzRXpQWHJvamhZS1hpNzFjak1yVDlFS0JCenhZSVEyOVRaZi1nZU5ya0t4a2xMZTJzTUFMX0VWZkFjdGktc2ZqMkkyeEZKZmQ4aklmX2V0cEJJUllUMTNrYUt0dTJiaTRHYi1XUEstS2hCN1M2cUY4OWZMdyIsImUiOiJBUUFCIiwiZCI6IlhmS3FmdjZuZ3FMZTktdEo5ekY5MVJZc1ZyWDZFV3RreDhmSmxjQWdtbTdUdmpHM3FEdU9henMyYjR0Um9mbTN1MjJZdE1UcG16LTRTMjNuQW1BODNsT0ZsTDJsX1VzNy1rRGx4OGFFVHRrc0tYOVo5VG0tSWRMWlB5NjJKQ29YU3JNcDhzRnMxMENZdUowQ0xHZEhOQXNJcllldUtqMllsT3VZZ1Q5MEk2MmpnUWRlM05oblN2MW42MjJyWVdURE94NFpuNHFqQTRpS1NnMl9sbzNWbDhPRU5PYlMyWlRBb3FmUld0LU9OZEMxWnlWWFV5QkRQeW5lVkdxRWNsdEg2Zzc5SXNpLU04ek8yVTJjVlpVTzdoOE8tVW5mYVRhd2xnei1SQlFpWTY3S05Yc1RRQ3VlZ2FJQU1ZVjZxcjVUU1Ai2odx5iT0xSX3BtMWFpdktyUSIsInAiOiI5X1o5ZUpGTWI5X3E4UlZCTDFfa29YVWZiTTRLTjJ1UVp1R2NpR0Y2OUJEMnVLejV4Z29PMFUwWTZpRTRvQnpORlFuYVlfZGsteVNXbEFqdjJILWhQa0xqb2ZURkhpTU5lMnFFTWlBWnk2eXJkZEg2OFY3SFRNRllUQlZQaHIxT0dxZlRmc01fRktmZVhWY1FvMTI1RjBJQm5iWjNSYzRua1pNS0hzczUyWE0iLCJxIjoiMVBFWWxiMmw1OG5VYmp0WThZelJNb0FaOWhyVzJYcDNyWmYxNENFVENXbFVxWXQtUTdDcjd3TEFFY243a2xZNURhd0JuTXJsZXl3S0ctTUFfU0hlN3dQQkpNeDlVUGV4Q3YyRW8xT1loMTk3SGQzSk9zUy1hWWljemJsYmJqU0RqWXVjR1I3Mi1vUWUzMmNNeGNzMk1GUFZwdWJuOGNqUFBudkp3STlpSkZVIiwiZHAiOiIyMzdSY0pIR0JONUUzYVdfN3d6R21QblJtSUlHM3lvVFNFNzhQbWx6Nm1xOXk1b3EtOWhaWjRNRXdfUW1hTzAxeVNMUXRGOEJmNkxTdkRYeEFrZHdWMm5ra0tfWWNhWDd3RHo0eWxwS0cxWTg3TzIwWWtkUXlxdjMybG1lN1JuVDhwcVBDQTRUWDloOWFVaXh6THNoSmVwaV9kWFFYUFZ4WjFhdXhiV0ZfdXMiLCJkcSI6InFaeFVVY2xhWVhLZ3N5Q3dhczRZUDFwTDAzeHpUNHk5ME5hdWNOVEhYZ0s0X2NidlRxbGxlWjQtTUswcXBkZnAzOXIyLWRXZXplbzVMeGMwVFd2eUwzMVZGYU9QMmJOQklKam9VbE9ldFkwMi1vWVM1NjJZWVdVQVNOandXNnFXY21NV2RlZjFIM3VuUDVqTVVxdlhRTTAxNjVnV2ZiN09YRjJyU0thc3JIVSIsInFpIjoiVzNhUDJmdTB1N1JVWWVubzIyNkljRjNBaEZzY3NWam55NmNGdWNGanNIbUg2V1BNYTU0dS1MWFRaYllSTFBCOFVvdHA3UjhEU0NoeEhtMjhjaDdqNTRnZkdWNmFlQVVPZXRiUEhCbGJudnQ1M2hFdERTLTlYVF8xYWtJNngwWk1Mc3F3eEZuZ2NSMF93S0V5Zzh2c1BlT2gwdlZsamkyNkpyZnNNZU9fakxvIn0=",
"created": "2021-06-15T21:06:54.763937286Z"
},
"success": true,
"errors": [],
"messages": []
}
```
Save these values as they won't be shown again. You will use these values later to generate the tokens. The pem and jwk fields are base64-encoded, you must decode them before using them (an example of this is shown in step 2).
### Step 2: Generate tokens using the key
Once you generate the key in step 1, you can use the `pem` or `jwk` values to generate self-signing URLs on your own. Using this method, you do not need to call the Stream API each time you are creating a new token.
Here's an example Cloudflare Worker script which generates tokens that expire in 60 minutes and only work for users accessing the video from UK. In lines 2 and 3, you will configure the `id` and `jwk` values from step 1:
```javascript
// Global variables
const jwkKey = "{PRIVATE-KEY-IN-JWK-FORMAT}";
const keyID = "";
const videoUID = "";
// expiresTimeInS is the expired time in second of the video
const expiresTimeInS = 3600;
// Main function
async function streamSignedUrl() {
const encoder = new TextEncoder();
const expiresIn = Math.floor(Date.now() / 1000) + expiresTimeInS;
const headers = {
alg: "RS256",
kid: keyID,
};
const data = {
sub: videoUID,
kid: keyID,
exp: expiresIn,
accessRules: [
{
type: "ip.geoip.country",
action: "allow",
country: ["GB"],
},
{
type: "any",
action: "block",
},
],
};
const token = `${objectToBase64url(headers)}.${objectToBase64url(data)}`;
const jwk = JSON.parse(atob(jwkKey));
const key = await crypto.subtle.importKey(
"jwk",
jwk,
{
name: "RSASSA-PKCS1-v1_5",
hash: "SHA-256",
},
false,
["sign"],
);
const signature = await crypto.subtle.sign(
{ name: "RSASSA-PKCS1-v1_5" },
key,
encoder.encode(token),
);
const signedToken = `${token}.${arrayBufferToBase64Url(signature)}`;
return signedToken;
}
// Utilities functions
function arrayBufferToBase64Url(buffer) {
return btoa(String.fromCharCode(...new Uint8Array(buffer)))
.replace(/=/g, "")
.replace(/\+/g, "-")
.replace(/\//g, "_");
}
function objectToBase64url(payload) {
return arrayBufferToBase64Url(
new TextEncoder().encode(JSON.stringify(payload)),
);
}
```
### Step 3: Rendering the video
If you are using the Stream Player, insert the token returned by the Worker in Step 2 in place of the video id:
```html
```
If you are using your own player, replace the video id in the manifest url with the `token` value:
`https://customer-.cloudflarestream.com/eyJhbGciOiJSUzI1NiIsImtpZCI6ImNkYzkzNTk4MmY4MDc1ZjJlZjk2MTA2ZDg1ZmNkODM4In0.eyJraWQiOiJjZGM5MzU5ODJmODA3NWYyZWY5NjEwNmQ4NWZjZDgzOCIsImV4cCI6IjE2MjE4ODk2NTciLCJuYmYiOiIxNjIxODgyNDU3In0.iHGMvwOh2-SuqUG7kp2GeLXyKvMavP-I2rYCni9odNwms7imW429bM2tKs3G9INms8gSc7fzm8hNEYWOhGHWRBaaCs3U9H4DRWaFOvn0sJWLBitGuF_YaZM5O6fqJPTAwhgFKdikyk9zVzHrIJ0PfBL0NsTgwDxLkJjEAEULQJpiQU1DNm0w5ctasdbw77YtDwdZ01g924Dm6jIsWolW0Ic0AevCLyVdg501Ki9hSF7kYST0egcll47jmoMMni7ujQCJI1XEAOas32DdjnMvU8vXrYbaHk1m1oXlm319rDYghOHed9kr293KM7ivtZNlhYceSzOpyAmqNFS7mearyQ/manifest/video.m3u8`
### Revoking keys
You can create up to 1,000 keys and rotate them at your convenience. Once revoked all tokens created with that key will be invalidated.
```bash
curl --request DELETE \
"https://api.cloudflare.com/client/v4/accounts/{account_id}/stream/keys/{key_id}" \
--header "Authorization: Bearer "
# Response:
{
"result": "Revoked",
"success": true,
"errors": [],
"messages": []
}
```
## Supported Restrictions
| Property Name | Description | |
| - | - | - |
| exp | Expiration. A unix epoch timestamp after which the token will stop working. Cannot be greater than 24 hours in the future from when the token is signed | |
| nbf | *Not Before* value. A unix epoch timestamp before which the token will not work | |
| downloadable | if true, the token can be used to download the mp4 (assuming the video has downloads enabled) | |
| accessRules | An array that specifies one or more ip and geo restrictions. accessRules are evaluated first-to-last. If a Rule matches, the associated action is applied and no further rules are evaluated. A token may have at most 5 members in the accessRules array. | |
### accessRules Schema
Each accessRule must include 2 required properties:
* `type`: supported values are `any`, `ip.src` and `ip.geoip.country`
* `action`: support values are `allow` and `block`
Depending on the rule type, accessRules support 2 additional properties:
* `country`: an array of 2-letter country codes in [ISO 3166-1 Alpha 2](https://www.iso.org/obp/ui/#search) format.
* `ip`: an array of ip ranges. It is recommended to include both IPv4 and IPv6 variants in a rule if possible. Having only a single variant in a rule means that rule will ignore the other variant. For example, an IPv4-based rule will never be applicable to a viewer connecting from an IPv6 address. CIDRs should be preferred over specific IP addresses. Some devices, such as mobile, may change their IP over the course of a view. Video Access Control are evaluated continuously while a video is being viewed. As a result, overly strict IP rules may disrupt playback.
***Example 1: Block views from a specific country***
```txt
...
"accessRules": [
{
"type": "ip.geoip.country",
"action": "block",
"country": ["US", "DE", "MX"],
},
]
```
The first rule matches on country, US, DE, and MX here. When that rule matches, the block action will have the token considered invalid. If the first rule doesn't match, there are no further rules to evaluate. The behavior in this situation is to consider the token valid.
***Example 2: Allow only views from specific country or IPs***
```txt
...
"accessRules": [
{
"type": "ip.geoip.country",
"country": ["US", "MX"],
"action": "allow",
},
{
"type": "ip.src",
"ip": ["93.184.216.0/24", "2400:cb00::/32"],
"action": "allow",
},
{
"type": "any",
"action": "block",
},
]
```
The first rule matches on country, US and MX here. When that rule matches, the allow action will have the token considered valid. If it doesn't match we continue evaluating rules
The second rule is an IP rule matching on CIDRs, 93.184.216.0/24 and 2400:cb00::/32. When that rule matches, the allow action will consider the rule valid.
If the first two rules don't match, the final rule of any will match all remaining requests and block those views.
## Security considerations
### Hotlinking Protection
By default, Stream embed codes can be used on any domain. If needed, you can limit the domains a video can be embedded on from the Stream dashboard.
In the dashboard, you will see a text box by each video labeled `Enter allowed origin domains separated by commas`. If you click on it, you can list the domains that the Stream embed code should be able to be used on. \`
* `*.badtortilla.com` covers `a.badtortilla.com`, `a.b.badtortilla.com` and does not cover `badtortilla.com`
* `example.com` does not cover [www.example.com](http://www.example.com) or any subdomain of example.com
* `localhost` requires a port if it is not being served over HTTP on port 80 or over HTTPS on port 443
* There is no path support - `example.com` covers `example.com/\*`
You can also control embed limitation programmatically using the Stream API. `uid` in the example below refers to the video id.
```bash
curl https://api.cloudflare.com/client/v4/accounts/{account_id}/stream/{video_uid} \
--header "Authorization: Bearer " \
--data "{\"uid\": \"\", \"allowedOrigins\": [\"example.com\"]}"
```
### Allowed Origins
The Allowed Origins feature lets you specify which origins are allowed for playback. This feature works even if you are using your own video player. When using your own video player, Allowed Origins restricts which domain the HLS/DASH manifests and the video segments can be requested from.
### Signed URLs
Combining signed URLs with embedding restrictions allows you to strongly control how your videos are viewed. This lets you serve only trusted users while preventing the signed URL from being hosted on an unknown site.
` with your unique customer code, in the URLs below:
```txt
https://customer-.cloudflarestream.com//manifest/video.m3u8
```
```txt
https://customer-.cloudflarestream.com//manifest/video.mpd
```
#### LL-HLS playback Beta
If a Live Inputs is enabled for the Low-Latency HLS beta, add the query string `?protocol=llhls` to the HLS manifest URL to test the low latency manifest in a custom player. Refer to [Start a Live Stream](https://developers.cloudflare.com/stream/stream-live/start-stream-live/#use-the-api) to enable this option.
```txt
https://customer-.cloudflarestream.com//manifest/video.m3u8?protocol=llhls
```
### Dashboard
1. Log into the [Stream Dashboard](https://dash.cloudflare.com/?to=/:account/stream).
2. From the list of videos, locate your video and select it.
3. From the **Settings** tab, locate the **HLS Manifest URL** and **Dash Manifest URL**.
4. Select **Click to copy** under the option you want to use.
### API
Refer to the [Stream video details API documentation](https://developers.cloudflare.com/api/resources/stream/methods/get/) to learn how to fetch the manifest URLs using the Cloudflare API.
## Customize manifests by specifying available client bandwidth
Each HLS and DASH manifest provides multiple resolutions of your video or live stream. Your player contains adaptive bitrate logic to estimate the viewer's available bandwidth, and select the optimal resolution to play. Each player has different logic that makes this decision, and most have configuration options to allow you to customize or override either bandwidth or resolution.
If your player lacks such configuration options or you need to override them, you can add the `clientBandwidthHint` query param to the request to fetch the manifest file. This should be used only as a last resort — we recommend first using customization options provided by your player. Remember that while you may be developing your website or app on a fast Internet connection, and be tempted to use this setting to force high quality playback, many of your viewers are likely connecting over slower mobile networks.
* `clientBandwidthHint` float
* Return only the video representation closest to the provided bandwidth value (in Mbps). This can be used to enforce a specific quality level. If you specify a value that would cause an invalid or empty manifest to be served, the hint is ignored.
Refer to the example below to display only the video representation with a bitrate closest to 1.8 Mbps.
```txt
https://customer-f33zs165nr7gyfy4.cloudflarestream.com/6b9e68b07dfee8cc2d116e4c51d6a957/manifest/video.m3u8?clientBandwidthHint=1.8
```
## Play live video in native apps with less than 1 second latency
If you need ultra low latency, and your users view live video in native apps, you can stream live video with [**glass-to-glass latency of less than 1 second**](https://blog.cloudflare.com/magic-hdmi-cable/), by using SRT or RTMPS for playback.
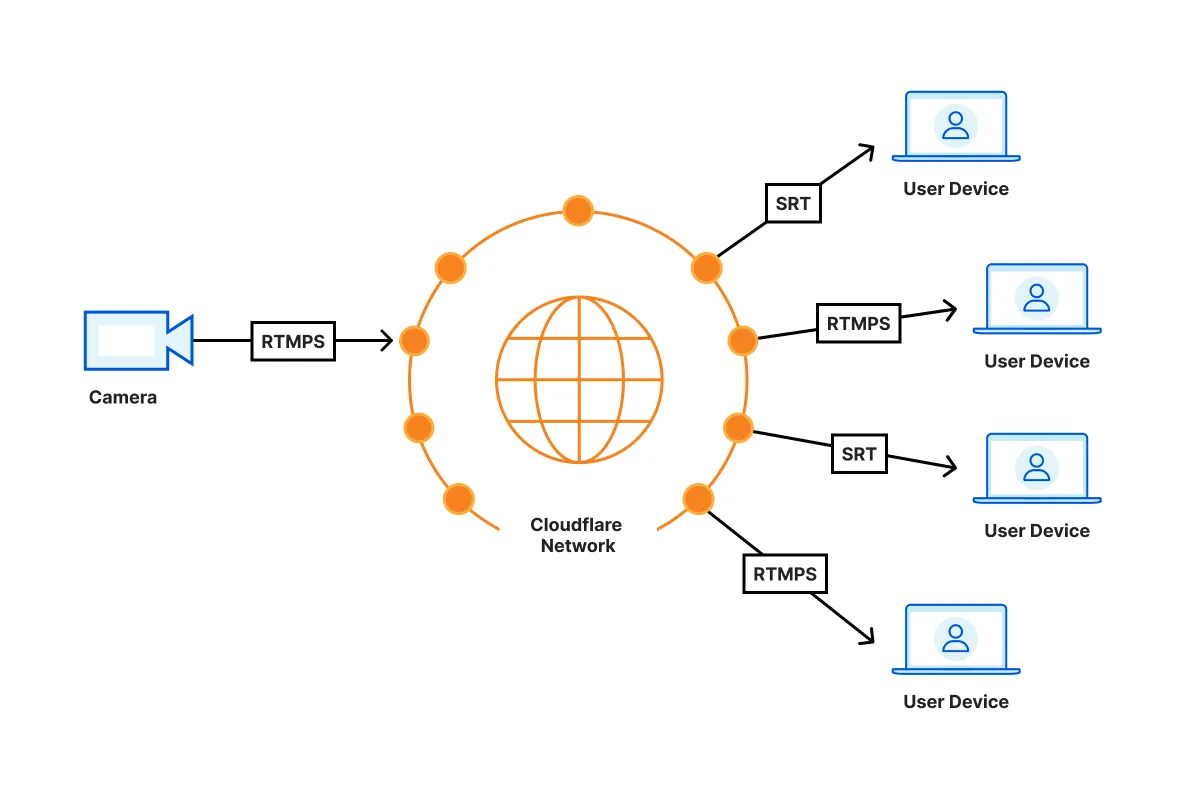
SRT and RTMPS playback is built into [ffmpeg](https://ffmpeg.org/). You will need to integrate ffmpeg with your own video player — neither [AVPlayer (iOS)](https://developers.cloudflare.com/stream/viewing-videos/using-own-player/ios/) nor [ExoPlayer (Android)](https://developers.cloudflare.com/stream/viewing-videos/using-own-player/android/) natively support SRT or RTMPS playback.
Note
Stream only supports the SRT caller mode, which is responsible for broadcasting a live stream after a connection is established.
We recommend using [ffmpeg-kit](https://github.com/arthenica/ffmpeg-kit) as a cross-platform wrapper for ffmpeg.
### Examples
* [RTMPS Playback with ffplay](https://developers.cloudflare.com/stream/examples/rtmps_playback/)
* [SRT playback with ffplay](https://developers.cloudflare.com/stream/examples/srt_playback/)
` with the your unique customer code, which can be found in the [Stream Dashboard](https://dash.cloudflare.com/?to=/:account/stream).
```html
```
Stream player is also available as a [React](https://www.npmjs.com/package/@cloudflare/stream-react) or [Angular](https://www.npmjs.com/package/@cloudflare/stream-angular) component.
## Player Size
### Fixed Dimensions
Changing the `height` and `width` attributes on the `iframe` will change the pixel value dimensions of the iframe displayed on the host page.
```html
```
### Responsive
To make an iframe responsive, it needs styles to enforce an aspect ratio by setting the `iframe` to `position: absolute;` and having it fill a container that uses a calculated `padding-top` percentage.
```html
```
## Basic Options
Player options are configured with querystring parameters in the iframe's `src` attribute. For example:
`https://customer-.cloudflarestream.com//iframe?autoplay=true&muted=true`
* `autoplay` default: `false`
* If the autoplay flag is included as a querystring parameter, the player will attempt to autoplay the video. If you don't want the video to autoplay, don't include the autoplay flag at all (instead of setting it to `autoplay=false`.) Note that mobile browsers generally do not support this attribute, the user must tap the screen to begin video playback. Please consider mobile users or users with Internet usage limits as some users don't have unlimited Internet access before using this attribute.
Warning
Some browsers now prevent videos with audio from playing automatically. You may set `muted` to `true` to allow your videos to autoplay. For more information, refer to [New ` Waiting
Waiting
Waiting
`;
async function handleRequest(request) {
const url = new URL(request.url);
let apiUrl = url.searchParams.get("apiurl");
if (apiUrl == null) {
apiUrl = API_URL;
}
// Rewrite request to point to API URL. This also makes the request mutable
// so you can add the correct Origin header to make the API server think
// that this request is not cross-site.
request = new Request(apiUrl, request);
request.headers.set("Origin", new URL(apiUrl).origin);
let response = await fetch(request);
// Recreate the response so you can modify the headers
response = new Response(response.body, response);
// Set CORS headers
response.headers.set("Access-Control-Allow-Origin", url.origin);
// Append to/Add Vary header so browser will cache response correctly
response.headers.append("Vary", "Origin");
return response;
}
async function handleOptions(request) {
if (
request.headers.get("Origin") !== null &&
request.headers.get("Access-Control-Request-Method") !== null &&
request.headers.get("Access-Control-Request-Headers") !== null
) {
// Handle CORS preflight requests.
return new Response(null, {
headers: {
...corsHeaders,
"Access-Control-Allow-Headers": request.headers.get(
"Access-Control-Request-Headers",
),
},
});
} else {
// Handle standard OPTIONS request.
return new Response(null, {
headers: {
Allow: "GET, HEAD, POST, OPTIONS",
},
});
}
}
const url = new URL(request.url);
if (url.pathname.startsWith(PROXY_ENDPOINT)) {
if (request.method === "OPTIONS") {
// Handle CORS preflight requests
return handleOptions(request);
} else if (
request.method === "GET" ||
request.method === "HEAD" ||
request.method === "POST"
) {
// Handle requests to the API server
return handleRequest(request);
} else {
return new Response(null, {
status: 405,
statusText: "Method Not Allowed",
});
}
} else {
return rawHtmlResponse(DEMO_PAGE);
}
},
};
```
* TypeScript
```ts
export default {
async fetch(request): PromiseWaiting
Waiting
Waiting
`;
async function handleRequest(request) {
const url = new URL(request.url);
let apiUrl = url.searchParams.get("apiurl");
if (apiUrl == null) {
apiUrl = API_URL;
}
// Rewrite request to point to API URL. This also makes the request mutable
// so you can add the correct Origin header to make the API server think
// that this request is not cross-site.
request = new Request(apiUrl, request);
request.headers.set("Origin", new URL(apiUrl).origin);
let response = await fetch(request);
// Recreate the response so you can modify the headers
response = new Response(response.body, response);
// Set CORS headers
response.headers.set("Access-Control-Allow-Origin", url.origin);
// Append to/Add Vary header so browser will cache response correctly
response.headers.append("Vary", "Origin");
return response;
}
async function handleOptions(request) {
if (
request.headers.get("Origin") !== null &&
request.headers.get("Access-Control-Request-Method") !== null &&
request.headers.get("Access-Control-Request-Headers") !== null
) {
// Handle CORS preflight requests.
return new Response(null, {
headers: {
...corsHeaders,
"Access-Control-Allow-Headers": request.headers.get(
"Access-Control-Request-Headers",
),
},
});
} else {
// Handle standard OPTIONS request.
return new Response(null, {
headers: {
Allow: "GET, HEAD, POST, OPTIONS",
},
});
}
}
const url = new URL(request.url);
if (url.pathname.startsWith(PROXY_ENDPOINT)) {
if (request.method === "OPTIONS") {
// Handle CORS preflight requests
return handleOptions(request);
} else if (
request.method === "GET" ||
request.method === "HEAD" ||
request.method === "POST"
) {
// Handle requests to the API server
return handleRequest(request);
} else {
return new Response(null, {
status: 405,
statusText: "Method Not Allowed",
});
}
} else {
return rawHtmlResponse(DEMO_PAGE);
}
},
} satisfies ExportedHandler;
```
* Hono
```ts
import { Hono } from "hono";
import { cors } from "hono/cors";
// The URL for the remote third party API you want to fetch from
// but does not implement CORS
const API_URL = "https://examples.cloudflareworkers.com/demos/demoapi";
// The endpoint you want the CORS reverse proxy to be on
const PROXY_ENDPOINT = "/corsproxy/";
const app = new Hono();
// Demo page handler
app.get("*", async (c) => {
// Only handle non-proxy requests with this handler
if (c.req.path.startsWith(PROXY_ENDPOINT)) {
return next();
}
// Create the demo page HTML
const DEMO_PAGE = `
Waiting
Waiting
Waiting
`;
return c.html(DEMO_PAGE);
});
// CORS proxy routes
app.on(["GET", "HEAD", "POST", "OPTIONS"], PROXY_ENDPOINT + "*", async (c) => {
const url = new URL(c.req.url);
// Handle OPTIONS preflight requests
if (c.req.method === "OPTIONS") {
const origin = c.req.header("Origin");
const requestMethod = c.req.header("Access-Control-Request-Method");
const requestHeaders = c.req.header("Access-Control-Request-Headers");
if (origin && requestMethod && requestHeaders) {
// Handle CORS preflight requests
return new Response(null, {
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET,HEAD,POST,OPTIONS",
"Access-Control-Max-Age": "86400",
"Access-Control-Allow-Headers": requestHeaders,
},
});
} else {
// Handle standard OPTIONS request
return new Response(null, {
headers: {
Allow: "GET, HEAD, POST, OPTIONS",
},
});
}
}
// Handle actual requests
let apiUrl = url.searchParams.get("apiurl") || API_URL;
// Rewrite request to point to API URL
const modifiedRequest = new Request(apiUrl, c.req.raw);
modifiedRequest.headers.set("Origin", new URL(apiUrl).origin);
let response = await fetch(modifiedRequest);
// Recreate the response so we can modify the headers
response = new Response(response.body, response);
// Set CORS headers
response.headers.set("Access-Control-Allow-Origin", url.origin);
// Append to/Add Vary header so browser will cache response correctly
response.headers.append("Vary", "Origin");
return response;
});
// Handle method not allowed for proxy endpoint
app.all(PROXY_ENDPOINT + "*", (c) => {
return new Response(null, {
status: 405,
statusText: "Method Not Allowed",
});
});
export default app;
```
* Python
```py
from pyodide.ffi import to_js as _to_js
from js import Response, URL, fetch, Object, Request
def to_js(x):
return _to_js(x, dict_converter=Object.fromEntries)
async def on_fetch(request):
cors_headers = {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "GET,HEAD,POST,OPTIONS",
"Access-Control-Max-Age": "86400",
}
api_url = "https://examples.cloudflareworkers.com/demos/demoapi"
proxy_endpoint = "/corsproxy/"
def raw_html_response(html):
return Response.new(html, headers=to_js({"content-type": "text/html;charset=UTF-8"}))
demo_page = f'''
Waiting
Waiting
Waiting
'''
async def handle_request(request):
url = URL.new(request.url)
api_url2 = url.searchParams["apiurl"]
if not api_url2:
api_url2 = api_url
request = Request.new(api_url2, request)
request.headers["Origin"] = (URL.new(api_url2)).origin
print(request.headers)
response = await fetch(request)
response = Response.new(response.body, response)
response.headers["Access-Control-Allow-Origin"] = url.origin
response.headers["Vary"] = "Origin"
return response
async def handle_options(request):
if "Origin" in request.headers and "Access-Control-Request-Method" in request.headers and "Access-Control-Request-Headers" in request.headers:
return Response.new(None, headers=to_js({
**cors_headers,
"Access-Control-Allow-Headers": request.headers["Access-Control-Request-Headers"]
}))
return Response.new(None, headers=to_js({"Allow": "GET, HEAD, POST, OPTIONS"}))
url = URL.new(request.url)
if url.pathname.startswith(proxy_endpoint):
if request.method == "OPTIONS":
return handle_options(request)
if request.method in ("GET", "HEAD", "POST"):
return handle_request(request)
return Response.new(None, status=405, statusText="Method Not Allowed")
return raw_html_response(demo_page)
```
* Rust
```rs
use std::{borrow::Cow, collections::HashMap};
use worker::*;
fn raw*html_response(html: &str) -> ResultWaiting
Waiting
Waiting
"#
);
if req.url()?.path().starts_with(proxy_endpoint) {
match req.method() {
Method::Options => return handle_options(req, &cors_headers),
Method::Get | Method::Head | Method::Post => return handle_request(req, api_url).await,
_ => return Response::error("Method Not Allowed", 405),
}
}
raw_html_response(&demo_page)
}
```
```plaintext
```
This is a demo using Workers geolocation data.
`; html_content += `You are located at: ${latitude},${longitude}.`; html_content += `Based off sensor data from ${content.data.city.name}:
`; html_content += `The AQI level is: ${content.data.aqi}.
`; html_content += `The N02 level is: ${content.data.iaqi.no2?.v}.
`; html_content += `The O3 level is: ${content.data.iaqi.o3?.v}.
`; html_content += `The temperature is: ${content.data.iaqi.t?.v}°C.
`; let html = `This is a demo using Workers geolocation data.
`; html_content += `You are located at: ${latitude},${longitude}.`; html_content += `Based off sensor data from ${content.data.city.name}:
`; html_content += `The AQI level is: ${content.data.aqi}.
`; html_content += `The N02 level is: ${content.data.iaqi.no2?.v}.
`; html_content += `The O3 level is: ${content.data.iaqi.o3?.v}.
`; html_content += `The temperature is: ${content.data.iaqi.t?.v}°C.
`; let html = `This is a demo using Workers geolocation data.
You are located at: ${latitude},${longitude}.
Based off sensor data from ${content.data.city.name}:
The AQI level is: ${content.data.aqi}.
The N02 level is: ${content.data.iaqi.no2?.v}.
The O3 level is: ${content.data.iaqi.o3?.v}.
The temperature is: ${content.data.iaqi.t?.v}°C.
`; // Complete HTML document const htmlDocument = html`This is a demo using Workers geolocation data.
" html_content += f"You are located at: {latitude},{longitude}." html_content += f"Based off sensor data from {content['data']['city']['name']}:
" html_content += f"The AQI level is: {content['data']['aqi']}.
" html_content += f"The N02 level is: {content['data']['iaqi']['no2']['v']}.
" html_content += f"The O3 level is: {content['data']['iaqi']['o3']['v']}.
" html_content += f"The temperature is: {content['data']['iaqi']['t']['v']}°C.
" html = f"""" + timezone + "
" + timezone + "
${timezone}
Colo: " + request.cf.colo + "
"; html_content += "Country: " + request.cf.country + "
"; html_content += "City: " + request.cf.city + "
"; html_content += "Continent: " + request.cf.continent + "
"; html_content += "Latitude: " + request.cf.latitude + "
"; html_content += "Longitude: " + request.cf.longitude + "
"; html_content += "PostalCode: " + request.cf.postalCode + "
"; html_content += "MetroCode: " + request.cf.metroCode + "
"; html_content += "Region: " + request.cf.region + "
"; html_content += "RegionCode: " + request.cf.regionCode + "
"; html_content += "Timezone: " + request.cf.timezone + "
"; let html = `You now have access to geolocation data about where your user is visiting from.
${html_content} `; return new Response(html, { headers: { "content-type": "text/html;charset=UTF-8", }, }); }, }; ``` * TypeScript ```ts export default { async fetch(request): PromiseColo: " + request.cf.colo + "
"; html_content += "Country: " + request.cf.country + "
"; html_content += "City: " + request.cf.city + "
"; html_content += "Continent: " + request.cf.continent + "
"; html_content += "Latitude: " + request.cf.latitude + "
"; html_content += "Longitude: " + request.cf.longitude + "
"; html_content += "PostalCode: " + request.cf.postalCode + "
"; html_content += "MetroCode: " + request.cf.metroCode + "
"; html_content += "Region: " + request.cf.region + "
"; html_content += "RegionCode: " + request.cf.regionCode + "
"; html_content += "Timezone: " + request.cf.timezone + "
"; let html = `You now have access to geolocation data about where your user is visiting from.
${html_content} `; return new Response(html, { headers: { "content-type": "text/html;charset=UTF-8", }, }); }, } satisfies ExportedHandler; ``` * Python ```py from workers import Response async def on_fetch(request): html_content = "" html_style = "body{padding:6em font-family: sans-serif;} h1{color:#f6821f;}" html_content += "Colo: " + request.cf.colo + "
" html_content += "Country: " + request.cf.country + "
" html_content += "City: " + request.cf.city + "
" html_content += "Continent: " + request.cf.continent + "
" html_content += "Latitude: " + request.cf.latitude + "
" html_content += "Longitude: " + request.cf.longitude + "
" html_content += "PostalCode: " + request.cf.postalCode + "
" html_content += "Region: " + request.cf.region + "
" html_content += "RegionCode: " + request.cf.regionCode + "
" html_content += "Timezone: " + request.cf.timezone + "
" html = f"""You now have access to geolocation data about where your user is visiting from.
{html_content} """ headers = {"content-type": "text/html;charset=UTF-8"} return Response(html, headers=headers) ``` * Hono ```ts import { Hono } from "hono"; import { html } from "hono/html"; // Define the RequestWithCf interface to add Cloudflare-specific properties interface RequestWithCf extends Request { cf: { // Cloudflare-specific properties for geolocation colo: string; country: string; city: string; continent: string; latitude: string; longitude: string; postalCode: string; metroCode: string; region: string; regionCode: string; timezone: string; // Add other CF properties as needed }; } const app = new Hono(); app.get("*", (c) => { // Cast the raw request to include Cloudflare-specific properties const request = c.req.raw; // Define styles const html_style = "body{padding:6em; font-family: sans-serif;} h1{color:#f6821f;}"; // Create content with geolocation data let html_content = html`Colo: ${request.cf.colo}
Country: ${request.cf.country}
City: ${request.cf.city}
Continent: ${request.cf.continent}
Latitude: ${request.cf.latitude}
Longitude: ${request.cf.longitude}
PostalCode: ${request.cf.postalCode}
MetroCode: ${request.cf.metroCode}
Region: ${request.cf.region}
RegionCode: ${request.cf.regionCode}
Timezone: ${request.cf.timezone}
`; // Compose the full HTML const htmlContent = html`You now have access to geolocation data about where your user is visiting from.
${html_content} `; // Return the HTML response return c.html(htmlContent); }); export default app; ```This markup was generated by a Cloudflare Worker.
`; return new Response(html, { headers: { "content-type": "text/html;charset=UTF-8", }, }); }, }; ``` [Run Worker in Playground](https://workers.cloudflare.com/playground#LYVwNgLglgDghgJwgegGYHsHALQBM4RwDcABAEbogB2+CAngLzbPYZb6HbW5QDGU2AAwBmABwAmAIwBOQQDZJgyQFYAXCxZtgHOFxp8BIiTPmKVAWABQAYXRUIAU3vYAIlADOMdO6jQ7qki08AmISKjhgBwYAIigaBwAPADoAK3do0lQoMCcIqNj45LToq1t7JwhsABU6GAcAuBgYMD4CKDtkFLgANzh3XgRYCABqYHRccAcrK0SvJBJcB1Q4cAgSAG9LEhI+uipeQIcIXgALAAoEBwBHEAd3CABKDa3tkl47e5ITiGAwEgYSAADAA8AEIXAB5axVACaAAUAKJfH5gAB8L22wIouDo6Ner2BJ0kqIAEg4wGB0CQAOqYMC4YHIIl4-EkYEwVFVE4eEjARAAaxAMBIAHc+iQAOZOBwIAgOXDkOg7EjWSkgXCoMCIBw0zD8mVJRkcjFs5DY3GAoiWE2XCAgBBUMIOEUkABKdy8VHcDjO31+ABpnqyvg44IsEO4Aptg9tou9ys4ILUHNEAtFHAkUH6wERTohvRAGABVKoAMWwomi-pN2wAvtX8bWHla69Xa0QrBpmFodHoePwhGIpLIFEplKU7I5nG5PN5fO0qAEgjpSOFIjFIoQdBlAtlcuvomRKWQSjZJxVqsmGk0Wrw2h00nZppZ1tE+XEAPpjCY5VMFRZFOktadl2PYhH2BiDsYI5mMozBAA) * TypeScript ```ts export default { async fetch(request): PromiseThis markup was generated by a Cloudflare Worker.
`; return new Response(html, { headers: { "content-type": "text/html;charset=UTF-8", }, }); }, } satisfies ExportedHandler; ``` * Python ```py from workers import Response def on_fetch(request): html = """This markup was generated by a Cloudflare Worker.
""" headers = {"content-type": "text/html;charset=UTF-8"} return Response(html, headers=headers) ``` * Rust ```rs use worker::*; #[event(fetch)] async fn fetch(_req: Request, _env: Env, _ctx: Context) -> ResultThis markup was generated by a Cloudflare Worker.
"#; Response::from_html(html) } ``` * Hono ```ts import { Hono } from "hono"; import { html } from "hono/html"; const app = new Hono(); app.get("*", (c) => { const doc = html`This markup was generated by a Cloudflare Worker with Hono.
`; return c.html(doc); }); export default app; ```
// wrangler.jsonc
{
"name": "app-name-goes-here", // name of the app
"main": "src/index.ts", // default file
"compatibility_date": "2025-02-11",
"compatibility_flags": ["nodejs_compat"], // Enable Node.js compatibility
"observability": {
// Enable logging by default
"enabled": true,
}
}
import { DurableObject } from "cloudflare:workers";
interface Env {
WEBSOCKET_HIBERNATION_SERVER: DurableObject;
}
// Durable Object
export class WebSocketHibernationServer extends DurableObject {
async fetch(request) {
// Creates two ends of a WebSocket connection.
const webSocketPair = new WebSocketPair();
const [client, server] = Object.values(webSocketPair);
// Calling `acceptWebSocket()` informs the runtime that this WebSocket is to begin terminating
// request within the Durable Object. It has the effect of "accepting" the connection,
// and allowing the WebSocket to send and receive messages.
// Unlike `ws.accept()`, `state.acceptWebSocket(ws)` informs the Workers Runtime that the WebSocket
// is "hibernatable", so the runtime does not need to pin this Durable Object to memory while
// the connection is open. During periods of inactivity, the Durable Object can be evicted
// from memory, but the WebSocket connection will remain open. If at some later point the
// WebSocket receives a message, the runtime will recreate the Durable Object
// (run the `constructor`) and deliver the message to the appropriate handler.
this.ctx.acceptWebSocket(server);
return new Response(null, {
status: 101,
webSocket: client,
});
},
async webSocketMessage(ws: WebSocket, message: string | ArrayBuffer): void | Promise {
// Upon receiving a message from the client, reply with the same message,
// but will prefix the message with "[Durable Object]: " and return the
// total number of connections.
ws.send(
`[Durable Object] message: ${message}, connections: ${this.ctx.getWebSockets().length}`,
);
},
async webSocketClose(ws: WebSocket, code: number, reason: string, wasClean: boolean) void | Promise {
// If the client closes the connection, the runtime will invoke the webSocketClose() handler.
ws.close(code, "Durable Object is closing WebSocket");
},
async webSocketError(ws: WebSocket, error: unknown): void | Promise {
console.error("WebSocket error:", error);
ws.close(1011, "WebSocket error");
}
}
import { DurableObject } from "cloudflare:workers";
interface Env {
ALARM_EXAMPLE: DurableObject;
}
export default {
async fetch(request, env) {
let url = new URL(request.url);
let userId = url.searchParams.get("userId") || crypto.randomUUID();
let id = env.ALARM_EXAMPLE.idFromName(userId);
return await env.ALARM_EXAMPLE.get(id).fetch(request);
},
};
const SECONDS = 1000;
export class AlarmExample extends DurableObject {
constructor(ctx, env) {
this.ctx = ctx;
this.storage = ctx.storage;
}
async fetch(request) {
// If there is no alarm currently set, set one for 10 seconds from now
let currentAlarm = await this.storage.getAlarm();
if (currentAlarm == null) {
this.storage.setAlarm(Date.now() + 10 \_ SECONDS);
}
}
async alarm(alarmInfo) {
// The alarm handler will be invoked whenever an alarm fires.
// You can use this to do work, read from the Storage API, make HTTP calls
// and set future alarms to run using this.storage.setAlarm() from within this handler.
if (alarmInfo?.retryCount != 0) {
console.log("This alarm event has been attempted ${alarmInfo?.retryCount} times before.");
}
// Set a new alarm for 10 seconds from now before exiting the handler
this.storage.setAlarm(Date.now() + 10 \_ SECONDS);
}
}
// src/index.ts
import { Hono } from 'hono'
import { cors } from 'hono/cors'
interface Env {
AUTH_TOKENS: KVNamespace;
}
const app = new Hono<{ Bindings: Env }>()
// Add CORS middleware
app.use('\*', cors())
app.get('/', async (c) => {
try {
// Get token from header or cookie
const token = c.req.header('Authorization')?.slice(7) ||
c.req.header('Cookie')?.match(/auth_token=([^;]+)/)?.[1];
if (!token) {
return c.json({
authenticated: false,
message: 'No authentication token provided'
}, 403)
}
// Check token in KV
const userData = await c.env.AUTH_TOKENS.get(token)
if (!userData) {
return c.json({
authenticated: false,
message: 'Invalid or expired token'
}, 403)
}
return c.json({
authenticated: true,
message: 'Authentication successful',
data: JSON.parse(userData)
})
} catch (error) {
console.error('Authentication error:', error)
return c.json({
authenticated: false,
message: 'Internal server error'
}, 500)
}
})
export default app
// src/producer.ts
interface Env {
REQUEST_QUEUE: Queue;
UPSTREAM_API_URL: string;
UPSTREAM_API_KEY: string;
}
export default {
async fetch(request: Request, env: Env) {
const info = {
timestamp: new Date().toISOString(),
method: request.method,
url: request.url,
headers: Object.fromEntries(request.headers),
};
await env.REQUEST_QUEUE.send(info);
return Response.json({
message: 'Request logged',
requestId: crypto.randomUUID()
});
},
async queue(batch: MessageBatch, env: Env) {
const requests = batch.messages.map(msg => msg.body);
const response = await fetch(env.UPSTREAM_API_URL, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${env.UPSTREAM_API_KEY}`
},
body: JSON.stringify({
timestamp: new Date().toISOString(),
batchSize: requests.length,
requests
})
});
if (!response.ok) {
throw new Error(`Upstream API error: ${response.status}`);
}
}
};
// Postgres.js 3.4.5 or later is recommended
import postgres from "postgres";
export interface Env {
// If you set another name in the Wrangler config file as the value for 'binding',
// replace "HYPERDRIVE" with the variable name you defined.
HYPERDRIVE: Hyperdrive;
}
export default {
async fetch(request, env, ctx): Promise {
console.log(JSON.stringify(env));
// Create a database client that connects to your database via Hyperdrive.
//
// Hyperdrive generates a unique connection string you can pass to
// supported drivers, including node-postgres, Postgres.js, and the many
// ORMs and query builders that use these drivers.
const sql = postgres(env.HYPERDRIVE.connectionString)
try {
// Test query
const results = await sql`SELECT * FROM pg_tables`;
// Clean up the client, ensuring we don't kill the worker before that is
// completed.
ctx.waitUntil(sql.end());
// Return result rows as JSON
return Response.json(results);
} catch (e) {
console.error(e);
return Response.json(
{ error: e instanceof Error ? e.message : e },
{ status: 500 },
);
}
},
} satisfies ExportedHandler;
import { WorkflowEntrypoint, WorkflowStep, WorkflowEvent } from 'cloudflare:workers';
type Env = {
// Add your bindings here, e.g. Workers KV, D1, Workers AI, etc.
MY_WORKFLOW: Workflow;
};
// User-defined params passed to your workflow
type Params = {
email: string;
metadata: Record;
};
export class MyWorkflow extends WorkflowEntrypoint {
async run(event: WorkflowEvent, step: WorkflowStep) {
// Can access bindings on `this.env`
// Can access params on `event.payload`
const files = await step.do('my first step', async () => {
// Fetch a list of files from $SOME_SERVICE
return {
files: [
'doc_7392_rev3.pdf',
'report_x29_final.pdf',
'memo_2024_05_12.pdf',
'file_089_update.pdf',
'proj_alpha_v2.pdf',
'data_analysis_q2.pdf',
'notes_meeting_52.pdf',
'summary_fy24_draft.pdf',
],
};
});
const apiResponse = await step.do('some other step', async () => {
let resp = await fetch('https://api.cloudflare.com/client/v4/ips');
return await resp.json();
});
await step.sleep('wait on something', '1 minute');
await step.do(
'make a call to write that could maybe, just might, fail',
// Define a retry strategy
{
retries: {
limit: 5,
delay: '5 second',
backoff: 'exponential',
},
timeout: '15 minutes',
},
async () => {
// Do stuff here, with access to the state from our previous steps
if (Math.random() > 0.5) {
throw new Error('API call to $STORAGE_SYSTEM failed');
}
},
);
}
}
export default {
async fetch(req: Request, env: Env): Promise {
let url = new URL(req.url);
if (url.pathname.startsWith('/favicon')) {
return Response.json({}, { status: 404 });
}
// Get the status of an existing instance, if provided
let id = url.searchParams.get('instanceId');
if (id) {
let instance = await env.MY_WORKFLOW.get(id);
return Response.json({
status: await instance.status(),
});
}
const data = await req.json()
// Spawn a new instance and return the ID and status
let instance = await env.MY_WORKFLOW.create({
// Define an ID for the Workflow instance
id: crypto.randomUUID(),
// Pass data to the Workflow instance
// Available on the WorkflowEvent
params: data,
});
return Response.json({
id: instance.id,
details: await instance.status(),
});
},
};
interface Env {
USER_EVENTS: AnalyticsEngineDataset;
}
export default {
async fetch(req: Request, env: Env): Promise {
let url = new URL(req.url);
let path = url.pathname;
let userId = url.searchParams.get("userId");
// Write a datapoint for this visit, associating the data with
// the userId as our Analytics Engine 'index'
env.USER_EVENTS.writeDataPoint({
// Write metrics data: counters, gauges or latency statistics
doubles: [],
// Write text labels - URLs, app names, event_names, etc
blobs: [path],
// Provide an index that groups your data correctly.
indexes: [userId],
});
return Response.json({
hello: "world",
});
,
};
import puppeteer from "@cloudflare/puppeteer";
interface Env {
BROWSER_RENDERING: Fetcher;
}
export default {
async fetch(request, env): Promise {
const { searchParams } = new URL(request.url);
let url = searchParams.get("url");
if (url) {
url = new URL(url).toString(); // normalize
const browser = await puppeteer.launch(env.MYBROWSER);
const page = await browser.newPage();
await page.goto(url);
// Parse the page content
const content = await page.content();
// Find text within the page content
const text = await page.$eval("body", (el) => el.textContent);
// Do something with the text
// e.g. log it to the console, write it to KV, or store it in a database.
console.log(text);
// Ensure we close the browser session
await browser.close();
return Response.json({
bodyText: text,
})
} else {
return Response.json({
error: "Please add an ?url=https://example.com/ parameter"
}, { status: 400 })
}
},
} satisfies ExportedHandler;
// src/index.ts
interface Env {
ASSETS: Fetcher;
}
export default {
fetch(request, env) {
const url = new URL(request.url);
if (url.pathname.startsWith("/api/")) {
return Response.json({
name: "Cloudflare",
});
}
return env.ASSETS.fetch(request);
},
} satisfies ExportedHandler;
Build an AI Agent on Cloudflare Workers, using the agents, and the state management and syncing APIs built into the agents.
// src/index.ts
import { Agent, AgentNamespace, Connection, ConnectionContext, getAgentByName, routeAgentRequest, WSMessage } from 'agents';
import { OpenAI } from "openai";
interface Env {
AIAgent: AgentNamespace;
OPENAI_API_KEY: string;
}
export class AIAgent extends Agent {
// Handle HTTP requests with your Agent
async onRequest(request) {
// Connect with AI capabilities
const ai = new OpenAI({
apiKey: this.env.OPENAI_API_KEY,
});
// Process and understand
const response = await ai.chat.completions.create({
model: "gpt-4",
messages: [{ role: "user", content: await request.text() }],
});
return new Response(response.choices[0].message.content);
}
async processTask(task) {
await this.understand(task);
await this.act();
await this.reflect();
}
// Handle WebSockets
async onConnect(connection: Connection) {
await this.initiate(connection);
connection.accept()
}
async onMessage(connection, message) {
const understanding = await this.comprehend(message);
await this.respond(connection, understanding);
}
async evolve(newInsight) {
this.setState({
...this.state,
insights: [...(this.state.insights || []), newInsight],
understanding: this.state.understanding + 1,
});
}
onStateUpdate(state, source) {
console.log("Understanding deepened:", {
newState: state,
origin: source,
});
}
// Scheduling APIs
// An Agent can schedule tasks to be run in the future by calling this.schedule(when, callback, data), where when can be a delay, a Date, or a cron string; callback the function name to call, and data is an object of data to pass to the function.
//
// Scheduled tasks can do anything a request or message from a user can: make requests, query databases, send emails, read+write state: scheduled tasks can invoke any regular method on your Agent.
async scheduleExamples() {
// schedule a task to run in 10 seconds
let task = await this.schedule(10, "someTask", { message: "hello" });
// schedule a task to run at a specific date
let task = await this.schedule(new Date("2025-01-01"), "someTask", {});
// schedule a task to run every 10 seconds
let { id } = await this.schedule("*/10 * * * *", "someTask", { message: "hello" });
// schedule a task to run every 10 seconds, but only on Mondays
let task = await this.schedule("0 0 * * 1", "someTask", { message: "hello" });
// cancel a scheduled task
this.cancelSchedule(task.id);
// Get a specific schedule by ID
// Returns undefined if the task does not exist
let task = await this.getSchedule(task.id)
// Get all scheduled tasks
// Returns an array of Schedule objects
let tasks = this.getSchedules();
// Cancel a task by its ID
// Returns true if the task was cancelled, false if it did not exist
await this.cancelSchedule(task.id);
// Filter for specific tasks
// e.g. all tasks starting in the next hour
let tasks = this.getSchedules({
timeRange: {
start: new Date(Date.now()),
end: new Date(Date.now() + 60 * 60 * 1000),
}
});
}
async someTask(data) {
await this.callReasoningModel(data.message);
}
// Use the this.sql API within the Agent to access the underlying SQLite database
async callReasoningModel(prompt: Prompt) {
interface Prompt {
userId: string;
user: string;
system: string;
metadata: Record;
}
interface History {
timestamp: Date;
entry: string;
}
let result = this.sql`SELECT * FROM history WHERE user = ${prompt.userId} ORDER BY timestamp DESC LIMIT 1000`;
let context = [];
for await (const row of result) {
context.push(row.entry);
}
const client = new OpenAI({
apiKey: this.env.OPENAI_API_KEY,
});
// Combine user history with the current prompt
const systemPrompt = prompt.system || 'You are a helpful assistant.';
const userPrompt = `${prompt.user}\n\nUser history:\n${context.join('\n')}`;
try {
const completion = await client.chat.completions.create({
model: this.env.MODEL || 'o3-mini',
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt },
],
temperature: 0.7,
max_tokens: 1000,
});
// Store the response in history
this
.sql`INSERT INTO history (timestamp, user, entry) VALUES (${new Date()}, ${prompt.userId}, ${completion.choices[0].message.content})`;
return completion.choices[0].message.content;
} catch (error) {
console.error('Error calling reasoning model:', error);
throw error;
}
}
// Use the SQL API with a type parameter
async queryUser(userId: string) {
type User = {
id: string;
name: string;
email: string;
};
// Supply the type paramter to the query when calling this.sql
// This assumes the results returns one or more User rows with "id", "name", and "email" columns
// You do not need to specify an array type (`User[]` or `Array`) as `this.sql` will always return an array of the specified type.
const user = await this.sql`SELECT * FROM users WHERE id = ${userId}`;
return user
}
// Run and orchestrate Workflows from Agents
async runWorkflow(data) {
let instance = await env.MY_WORKFLOW.create({
id: data.id,
params: data,
})
// Schedule another task that checks the Workflow status every 5 minutes...
await this.schedule("*/5 * * * *", "checkWorkflowStatus", { id: instance.id });
}
}
export default {
async fetch(request, env, ctx): Promise {
// Routed addressing
// Automatically routes HTTP requests and/or WebSocket connections to /agents/:agent/:name
// Best for: connecting React apps directly to Agents using useAgent from @cloudflare/agents/react
return (await routeAgentRequest(request, env)) || Response.json({ msg: 'no agent here' }, { status: 404 });
// Named addressing
// Best for: convenience method for creating or retrieving an agent by name/ID.
let namedAgent = getAgentByName(env.AIAgent, 'agent-456');
// Pass the incoming request straight to your Agent
let namedResp = (await namedAgent).fetch(request);
return namedResp;
// Durable Objects-style addressing
// Best for: controlling ID generation, associating IDs with your existing systems,
// and customizing when/how an Agent is created or invoked
const id = env.AIAgent.newUniqueId();
const agent = env.AIAgent.get(id);
// Pass the incoming request straight to your Agent
let resp = await agent.fetch(request);
// return Response.json({ hello: 'visit https://developers.cloudflare.com/agents for more' });
},
} satisfies ExportedHandler;
// client.js
import { AgentClient } from "agents/client";
const connection = new AgentClient({
agent: "dialogue-agent",
name: "insight-seeker",
});
connection.addEventListener("message", (event) => {
console.log("Received:", event.data);
});
connection.send(
JSON.stringify({
type: "inquiry",
content: "What patterns do you see?",
})
);
// app.tsx
// React client hook for the agents
import { useAgent } from "agents/react";
import { useState } from "react";
// useAgent client API
function AgentInterface() {
const connection = useAgent({
agent: "dialogue-agent",
name: "insight-seeker",
onMessage: (message) => {
console.log("Understanding received:", message.data);
},
onOpen: () => console.log("Connection established"),
onClose: () => console.log("Connection closed"),
});
const inquire = () => {
connection.send(
JSON.stringify({
type: "inquiry",
content: "What insights have you gathered?",
})
);
};
return (
);
}
// State synchronization
function StateInterface() {
const [state, setState] = useState({ counter: 0 });
const agent = useAgent({
agent: "thinking-agent",
onStateUpdate: (newState) => setState(newState),
});
const increment = () => {
agent.setState({ counter: state.counter + 1 });
};
return (
Count: {state.counter}
);
}
{
"durable_objects": {
"bindings": [
{
"binding": "AIAgent",
"class_name": "AIAgent"
}
]
},
"migrations": [
{
"tag": "v1",
// Mandatory for the Agent to store state
"new_sqlite_classes": ["AIAgent"]
}
]
}
- Imports the `Agent` class from the `agents` package
- Extends the `Agent` class and implements the methods exposed by the `Agent`, including `onRequest` for HTTP requests, or `onConnect` and `onMessage` for WebSockets.
- Uses the `this.schedule` scheduling API to schedule future tasks.
- Uses the `this.setState` API within the Agent for syncing state, and uses type parameters to ensure the state is typed.
- Uses the `this.sql` as a lower-level query API.
- For frontend applications, uses the optional `useAgent` hook to connect to the Agent via WebSockets
import { OpenAI } from "openai";
interface Env {
OPENAI_API_KEY: string;
}
// Define your JSON schema for a calendar event
const CalendarEventSchema = {
type: 'object',
properties: {
name: { type: 'string' },
date: { type: 'string' },
participants: { type: 'array', items: { type: 'string' } },
},
required: ['name', 'date', 'participants']
};
export default {
async fetch(request: Request, env: Env) {
const client = new OpenAI({
apiKey: env.OPENAI_API_KEY,
// Optional: use AI Gateway to bring logs, evals & caching to your AI requests
// https://developers.cloudflare.com/ai-gateway/providers/openai/
// baseUrl: "https://gateway.ai.cloudflare.com/v1/{account_id}/{gateway_id}/openai"
});
const response = await client.chat.completions.create({
model: 'gpt-4o-2024-08-06',
messages: [
{ role: 'system', content: 'Extract the event information.' },
{ role: 'user', content: 'Alice and Bob are going to a science fair on Friday.' },
],
// Use the `response_format` option to request a structured JSON output
response_format: {
// Set json_schema and provide ra schema, or json_object and parse it yourself
type: 'json_schema',
schema: CalendarEventSchema, // provide a schema
},
});
// This will be of type CalendarEventSchema
const event = response.choices[0].message.parsed;
return Response.json({
"calendar_event": event,
})
}
}
https://example.com/hello fetch request to https://notexample.com/hello.") --> B(Is notexample.com https://notexample.com/ https://notexample.com/hello example.com zone.)
C -- Yes --> E(Do you own notexample.com?)
C -- No --> F(Purge https://notexample.com/hello example.com zone.)
E -- Yes --> G(Purge https://notexample.com/hello notexample.com zone.)
E -- No --> H(Sorry, you can not purge the asset. notexample.com can purge it.)
```
### Purge assets stored with the Cache API
Assets stored in the cache through [Cache API](https://developers.cloudflare.com/workers/runtime-apis/cache/) operations can be purged in a couple of ways:
* Call `cache.delete` within a Worker to invalidate the cache for the asset with a matching request variable.
* Assets purged in this way are only purged locally to the data center the Worker runtime was executed.
* To purge an asset globally, use the standard [cache purge options](https://developers.cloudflare.com/cache/how-to/purge-cache/). Based on cache API implementation, not all cache purge endpoints function for purging assets stored by the Cache API.
* All assets on a zone can be purged by using the [Purge Everything](https://developers.cloudflare.com/cache/how-to/purge-cache/purge-everything/) cache operation. This purge will remove all assets associated with a Cloudflare zone from cache in all data centers regardless of the method set.
* [Cache Tags](https://developers.cloudflare.com/cache/how-to/purge-cache/purge-by-tags/#add-cache-tag-http-response-headers) can be added to requests dynamically in a Worker by calling `response.headers.append()` and appending `Cache-Tag` values dynamically to that request. Once set, those tags can be used to selectively purge assets from cache without invalidating all cached assets on a zone.
* Currently, it is not possible to purge a URL stored through Cache API that uses a custom cache key set by a Worker. Instead, use a [custom key created via Cache Rules](https://developers.cloudflare.com/cache/how-to/cache-rules/settings/#cache-key). Alternatively, purge your assets using purge everything, purge by tag, purge by host or purge by prefix.
## Edge versus browser caching
The browser cache is controlled through the `Cache-Control` header sent in the response to the client (the `Response` instance return from the handler). Workers can customize browser cache behavior by setting this header on the response.
Other means to control Cloudflare’s cache that are not mentioned in this documentation include: Page Rules and Cloudflare cache settings. Refer to the [How to customize Cloudflare’s cache](https://developers.cloudflare.com/cache/concepts/customize-cache/) if you wish to avoid writing JavaScript with still some granularity of control.
What should I use: the Cache API or fetch for caching objects on Cloudflare?
For requests where Workers are behaving as middleware (that is, Workers are sending a subrequest via `fetch`) it is recommended to use `fetch`. This is because preexisting settings are in place that optimize caching while preventing unintended dynamic caching. For projects where there is no backend (that is, the entire project is on Workers as in [Workers Sites](https://developers.cloudflare.com/workers/configuration/sites/start-from-scratch)) the Cache API is the only option to customize caching.
The asset will be cached under the hostname specified within the Worker's subrequest — not the Worker's own hostname. Therefore, in order to purge the cached asset, the purge will have to be performed for the hostname included in the Worker subrequest.
### `fetch`
In the context of Workers, a [`fetch`](https://developers.cloudflare.com/workers/runtime-apis/fetch/) provided by the runtime communicates with the Cloudflare cache. First, `fetch` checks to see if the URL matches a different zone. If it does, it reads through that zone’s cache (or Worker). Otherwise, it reads through its own zone’s cache, even if the URL is for a non-Cloudflare site. Cache settings on `fetch` automatically apply caching rules based on your Cloudflare settings. `fetch` does not allow you to modify or inspect objects before they reach the cache, but does allow you to modify how it will cache.
When a response fills the cache, the response header contains `CF-Cache-Status: HIT`. You can tell an object is attempting to cache if one sees the `CF-Cache-Status` at all.
This [template](https://developers.cloudflare.com/workers/examples/cache-using-fetch/) shows ways to customize Cloudflare cache behavior on a given request using fetch.
### Cache API
The [Cache API](https://developers.cloudflare.com/workers/runtime-apis/cache/) can be thought of as an ephemeral key-value store, whereby the `Request` object (or more specifically, the request URL) is the key, and the `Response` is the value.
There are two types of cache namespaces available to the Cloudflare Cache:
* **`caches.default`** – You can access the default cache (the same cache shared with `fetch` requests) by accessing `caches.default`. This is useful when needing to override content that is already cached, after receiving the response.
* **`caches.open()`** – You can access a namespaced cache (separate from the cache shared with `fetch` requests) using `let cache = await caches.open(CACHE_NAME)`. Note that [`caches.open`](https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage/open) is an async function, unlike `caches.default`.
When to use the Cache API:
* When you want to programmatically save and/or delete responses from a cache. For example, say an origin is responding with a `Cache-Control: max-age:0` header and cannot be changed. Instead, you can clone the `Response`, adjust the header to the `max-age=3600` value, and then use the Cache API to save the modified `Response` for an hour.
* When you want to programmatically access a Response from a cache without relying on a `fetch` request. For example, you can check to see if you have already cached a `Response` for the `https://example.com/slow-response` endpoint. If so, you can avoid the slow request.
This [template](https://developers.cloudflare.com/workers/examples/cache-api/) shows ways to use the cache API. For limits of the cache API, refer to [Limits](https://developers.cloudflare.com/workers/platform/limits/#cache-api-limits).
Tiered caching and the Cache API
Cache API within Workers does not support tiered caching. Tiered Cache concentrates connections to origin servers so they come from a small number of data centers rather than the full set of network locations. Cache API is local to a data center, this means that `cache.match` does a lookup, `cache.put` stores a response, and `cache.delete` removes a stored response only in the cache of the data center that the Worker handling the request is in. Because these methods apply only to local cache, they will not work with tiered cache.
## Related resources
* [Cache API](https://developers.cloudflare.com/workers/runtime-apis/cache/)
* [Customize cache behavior with Workers](https://developers.cloudflare.com/cache/interaction-cloudflare-products/workers/)
Loading...
``` * JavaScript ```js import { WorkerEntrypoint } from "cloudflare:workers"; export default class extends WorkerEntrypoint { async fetch(request) { const url = new URL(request.url); if (url.pathname === "/api/oauth/callback") { const code = url.searchParams.get("code"); const sessionId = await exchangeAuthorizationCodeForAccessAndRefreshTokensAndPersistToDatabaseAndGetSessionId( code, ); if (sessionId) { return new Response(null, { headers: { "Set-Cookie": `sessionId=${sessionId}; HttpOnly; SameSite=Strict; Secure; Path=/; Max-Age=86400`, }, }); } else { return Response.json( { error: "Invalid OAuth code. Please try again." }, { status: 400 }, ); } } return new Response(null, { status: 404 }); } } ``` * TypeScript ```ts import { WorkerEntrypoint } from "cloudflare:workers"; export default class extends WorkerEntrypoint { async fetch(request: Request) { const url = new URL(request.url); if (url.pathname === "/api/oauth/callback") { const code = url.searchParams.get("code"); const sessionId = await exchangeAuthorizationCodeForAccessAndRefreshTokensAndPersistToDatabaseAndGetSessionId(code); if (sessionId) { return new Response(null, { headers: { "Set-Cookie": `sessionId=${sessionId}; HttpOnly; SameSite=Strict; Secure; Path=/; Max-Age=86400`, }, }); } else { return Response.json( { error: "Invalid OAuth code. Please try again." }, { status: 400 } ); } } return new Response(null, { status: 404 }); } } ``` ## Advanced routing control For more explicit control over SPA routing behavior, you can use `run_worker_first` with an array of route patterns. This approach disables the automatic `Sec-Fetch-Mode: navigate` detection and gives you explicit control over which requests should be handled by your Worker script vs served as static assets. Note Advanced routing control is supported in: * [Wrangler](https://developers.cloudflare.com/workers/wrangler/install-and-update/) v4.20.0 and above * [Cloudflare Vite plugin](https://developers.cloudflare.com/workers/vite-plugin/get-started/) v1.7.0 and above - wrangler.jsonc ```jsonc { "name": "my-worker", "compatibility_date": "2025-07-16", "main": "./src/index.ts", "assets": { "directory": "./dist/", "not_found_handling": "single-page-application", "binding": "ASSETS", "run_worker_first": ["/api/*", "!/api/docs/*"] } } ``` - wrangler.toml ```toml name = "my-worker" compatibility_date = "2025-07-16" main = "./src/index.ts" [assets] directory = "./dist/" not_found_handling = "single-page-application" binding = "ASSETS" run_worker_first = [ "/api/*", "!/api/docs/*" ] ``` This configuration provides explicit routing control without relying on browser navigation headers, making it ideal for complex SPAs that need fine-grained routing behavior. Your Worker script can then handle the matched routes and (optionally using [the assets binding](https://developers.cloudflare.com/workers/static-assets/binding/#binding)) and serve dynamic content. **For example:** * JavaScript ```js export default { async fetch(request, env) { const url = new URL(request.url); if (url.pathname === "/api/name") { return new Response(JSON.stringify({ name: "Cloudflare" }), { headers: { "Content-Type": "application/json" }, }); } return new Response(null, { status: 404 }); }, }; ``` * TypeScript ```ts export default { async fetch(request, env): PromiseLoading...
``` * JavaScript ```js import { WorkerEntrypoint } from "cloudflare:workers"; export default class extends WorkerEntrypoint { async fetch(request) { const url = new URL(request.url); if (url.pathname === "/api/oauth/callback") { const code = url.searchParams.get("code"); const sessionId = await exchangeAuthorizationCodeForAccessAndRefreshTokensAndPersistToDatabaseAndGetSessionId( code, ); if (sessionId) { return new Response(null, { headers: { "Set-Cookie": `sessionId=${sessionId}; HttpOnly; SameSite=Strict; Secure; Path=/; Max-Age=86400`, }, }); } else { return Response.json( { error: "Invalid OAuth code. Please try again." }, { status: 400 }, ); } } return new Response(null, { status: 404 }); } } ``` * TypeScript ```ts import { WorkerEntrypoint } from "cloudflare:workers"; export default class extends WorkerEntrypoint { async fetch(request: Request) { const url = new URL(request.url); if (url.pathname === "/api/oauth/callback") { const code = url.searchParams.get("code"); const sessionId = await exchangeAuthorizationCodeForAccessAndRefreshTokensAndPersistToDatabaseAndGetSessionId(code); if (sessionId) { return new Response(null, { headers: { "Set-Cookie": `sessionId=${sessionId}; HttpOnly; SameSite=Strict; Secure; Path=/; Max-Age=86400`, }, }); } else { return Response.json( { error: "Invalid OAuth code. Please try again." }, { status: 400 } ); } } return new Response(null, { status: 404 }); } } ``` ## Local Development If you are using a Vite-powered SPA framework, you might be interested in using our [Vite plugin](https://developers.cloudflare.com/workers/vite-plugin/) which offers a Vite-native developer experience. ### Reference In most cases, configuring `assets.not_found_handling` to `404-page` will provide the desired behavior. If you are building your own framework, or have specialized needs, the following diagram can provide insight into exactly how the routing decisions are made. Full routing decision diagram ```mermaid flowchart Request@{ shape: stadium, label: "Incoming request" } Request-->RunWorkerFirst RunWorkerFirst@{ shape: diamond, label: "Run Worker script first?" } RunWorkerFirst-->|Request matches run_worker_first path|WorkerScriptInvoked RunWorkerFirst-->|Request matches run_worker_first negative path|AssetServing RunWorkerFirst-->|No matches|RequestMatchesAsset RequestMatchesAsset@{ shape: diamond, label: "Request matches asset?" } RequestMatchesAsset-->|Yes|AssetServing RequestMatchesAsset-->|No|WorkerScriptPresent WorkerScriptPresent@{ shape: diamond, label: "Worker script present?" } WorkerScriptPresent-->|No|AssetServing WorkerScriptPresent-->|Yes|RequestNavigation RequestNavigation@{ shape: diamond, label: "Request is navigation request?" } RequestNavigation-->|No|WorkerScriptInvoked WorkerScriptInvoked@{ shape: rect, label: "Worker script invoked" } WorkerScriptInvoked-.->|Asset binding|AssetServing RequestNavigation-->|Yes|AssetServing subgraph Asset serving AssetServing@{ shape: diamond, label: "Request matches asset?" } AssetServing-->|Yes|AssetServed AssetServed@{ shape: stadium, label: "**200 OK**Get started by creating your first note
Configure post-processing of recording transcriptions with AI models.
Settings changes are auto-saved locally.
 ```
In this example, `sizes` says that for screens smaller than 640 pixels the image is displayed at full viewport width; on all larger screens the image stays at 640px. Note that one of the options in `srcset` is 1280 pixels, because an image displayed at 640 CSS pixels may need twice as many image pixels on a high-dpi (`2x`) display.
## WebP images
`srcset` is useful for pixel-based formats such as PNG, JPEG, and WebP. It is unnecessary for vector-based SVG images.
HTML also [supports the `
```
In this example, `sizes` says that for screens smaller than 640 pixels the image is displayed at full viewport width; on all larger screens the image stays at 640px. Note that one of the options in `srcset` is 1280 pixels, because an image displayed at 640 CSS pixels may need twice as many image pixels on a high-dpi (`2x`) display.
## WebP images
`srcset` is useful for pixel-based formats such as PNG, JPEG, and WebP. It is unnecessary for vector-based SVG images.
HTML also [supports the `