cloud worldTo be A geek2025-08-22T09:53:04.902Zhttps://cloudsjhan.github.io/cloud sjhanHexo基于 Flink CDC 构建 MySQL 到 Databend 的 实时数据同步https://cloudsjhan.github.io/2025/08/22/基于-Flink-CDC-构建-MySQL-到-Databend-的-实时数据同步/2025-08-22T09:52:20.000Z2025-08-22T09:53:04.902Z
CREATE TABLE products (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512)); ALTER TABLE products AUTO_INCREMENT = 10;
INSERT INTO products VALUES (default,"scooter","Small 2-wheel scooter"), (default,"car battery","12V car battery"), (default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"), (default,"hammer","12oz carpenter's hammer"), (default,"hammer","14oz carpenter's hammer"), (default,"hammer","16oz carpenter's hammer"), (default,"rocks","box of assorted rocks"), (default,"jacket","water resistent black wind breaker"), (default,"cloud","test for databend"), (default,"spare tire","24 inch spare tire");
Databend 中建表
1
CREATE TABLE bend_products (id INT NOT NULL, name VARCHAR(255) NOT NULL, description VARCHAR(512) );
INSERT INTO products VALUES (default,"scooter","Small 2-wheel scooter"), (default,"car battery","12V car battery"), (default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"), (default,"hammer","12oz carpenter's hammer"), (default,"hammer","14oz carpenter's hammer"), (default,"hammer","16oz carpenter's hammer"), (default,"rocks","box of assorted rocks"), (default,"jacket","water resistent black wind breaker"), (default,"cloud","test for databend"), (default,"spare tire","24 inch spare tire");
这些数据会立即同步到 Databend 当中。
假如此时 MySQL 中更新了一条数据:
那么 id=10 的数据在 databend 中也会被立即更新:
环境清理
操作结束后,在 docker-compose.yml 文件所在的目录下执行如下命令停止所有容器:
1
docker-compose down
在 Flink 所在目录 flink-1.16.0 下执行如下命令停止 Flink 集群:
1
./bin/stop-cluster.sh
结论
以上就是基于 Flink CDC 构建 MySQL 到 Databend 的 实时数据同步的全部过程。
mysql flink connector is over 2.4.1
flin version is 1.17.1
]]>
<p class="description"></p>
<p><img src="https://" alt="" style="width:100%"></p>
Deep Dive into SeaTunnel Databend Sink Connector CDC Implementationhttps://cloudsjhan.github.io/2025/08/18/Deep-Dive-into-SeaTunnel-Databend-Sink-Connector-CDC-Implementation/2025-08-18T02:58:57.000Z2025-08-18T03:00:11.735Z
Deep Dive into SeaTunnel Databend Sink Connector CDC Implementation
Background
Databend is an AI-native data warehouse optimized for analytical workloads with a columnar storage architecture, serving as an open-source alternative to Snowflake. When handling CDC (Change Data Capture) scenarios, executing individual UPDATE and DELETE operations severely impacts performance and fails to leverage Databend’s batch processing advantages.
Before PR #9661, SeaTunnel’s Databend sink connector only supported batch INSERT operations, lacking efficient handling of UPDATE and DELETE operations in CDC scenarios. This limitation restricted its application in real-time data synchronization scenarios.
Core Challenges
CDC scenarios present the following main challenges:
Parallel Processing: Support multi-table parallel CDC synchronization
Conclusion
By introducing Stream and MERGE INTO mechanisms, SeaTunnel’s Databend sink connector successfully implements high-performance CDC support. This innovative solution not only significantly improves data synchronization performance but also ensures data consistency and reliability. For OLAP scenarios requiring real-time data synchronization, this feature provides robust technical support.
Testcontainers is an open-source library that provides lightweight, disposable instances of databases, message brokers, web browsers, or any service that can run in a Docker container.
Core Features:
Disposable: Can be discarded after testing
Lightweight: Quick to start with minimal resource usage
Docker-based: Leverages container technology for isolation
Main Use Cases:
Database testing: MySQL, PostgreSQL, MongoDB, Databend etc.
Message queue testing: RabbitMQ, Kafka, etc.
Browser automation testing
Testing any containerizable service Using TestContainers for test cases helps avoid test environment pollution, ensures test environment consistency, simplifies test configuration, and improves test reliability.
This tool is particularly suitable for testing scenarios that depend on external services, enabling quick creation of isolated test environments.
Support Databend for Testcontainers
The Databend team has completed support for Databend data source in three major programming languages through PRs in testcontainer-java, testcontainers-go, and testcontainers-rs. This means developers can easily integrate Databend test environments in projects using these languages.
Prerequisites
Docker installed in the operating environment
Development environments for Java, Go, and Rust installed
Java Dependency Configuration
First, create a new Java Demo project. Here’s an example using Maven, adding databend testcontainers and databend-jdbc dependencies in pom.xml:
Create a `TestContainerDatabend` test class with its constructor: publicclassTestContainerDatabend{ privatefinal DatabendContainer dockerContainer;
publicTestContainerDatabend(){ dockerContainer = new DatabendContainer("datafuselabs/databend:v1.2.615"); dockerContainer.withUsername("databend").withPassword("databend").withUrlParam("ssl", "false"); dockerContainer.start(); } }
We specified datafuselabs/databend:v1.2.615 as the Docker image for starting Databend, other databend versions available at databend docker hub, then set the username and password, and started the container service.
public String getJdbcUrl(){ return format("jdbc:databend://%s:%s@%s:%s/", dockerContainer.getUsername(), dockerContainer.getPassword(), dockerContainer.getHost(), dockerContainer.getMappedPort(8000)); }
While running the test, we can see that testcontainers has started a databend container service in our system:
After the test completes, the container is immediately destroyed and resources are released.
Besides Databend, Testcontainers supports most databases and message queues available in the market, making it easy to build test suites that depend on these resources.
Go
Similarly, for Golang projects requiring Databend services, you can use testcontainers-go:
#[cfg(test)] mod tests { use databend_driver::Client;
use crate::{databend::Databend as DatabendImage, testcontainers::runners::AsyncRunner};
#[tokio::test] async fn test_databend() { let databend = DatabendImage::default().start().await.unwrap(); let http_port = databend.get_host_port_ipv4(8000).await.unwrap(); let dsn = format!( "databend://databend:databend@localhost:{}/default?sslmode=disable", http_port ); let client = Client::new(dsn.to_string()); let conn = client.get_conn().await.unwrap(); let row = conn.query_row("select 'hello'").await.unwrap(); assert!(row.is_some()); let row = row.unwrap(); let (val,): (String,) = row.try_into().unwrap(); assert_eq!(val, "hello");
let conn2 = conn.clone(); let row = conn2.query_row("select 'world'").await.unwrap(); assert!(row.is_some()); let row = row.unwrap(); let (val,): (String,) = row.try_into().unwrap(); assert_eq!(val, "world"); } }
Conclusion
For modern software development, reliable testing frameworks and toolchains are crucial foundations for ensuring code quality. With Databend’s multi-language support for Testcontainers, developers can more conveniently perform database-related integration testing, thereby improving overall development efficiency and code quality.
Whether using Java, Go, or Rust, Testcontainers provides reliable support for Databend developers’ testing work. We look forward to seeing more developers apply this powerful testing tool in real projects to build more robust application systems.
// Function to return the single instance func GetInstance() *singleton { // Use sync.Once to ensure the instance is created only once once.Do(func() { instance = &singleton{data: "This is a singleton"} })
// Build a villa v_builder := &VillaBuilder{} director.builder = v_builder villa := director.Construct() fmt.Println(*villa) // Output: {Villa Windows Villa Doors Villa Roof} }
func Example() { a := 1 c := make(chan error) go func() { c <- err return }() // Example exits here, causing a goroutine leak. if a > 0 { return } err := <-c }
只需将其改为缓冲通道即可解决这一问题: c := make(chan error, 1)
滥用 range with Channels
可以使用 range 遍历通道。但是,如果通道为空,range 将等待新数据,可能会阻塞 goroutine。
func main() { wg := &sync.WaitGroup{} c := make(chan any, 1) items := []int{1, 2, 3, 4, 5} for _, i := range items { wg.Add(1) go func() { c <- i }() } go func() { for data := range c { fmt.Println(data) wg.Done() } fmt.Println("close") }() wg.Wait() time.Sleep(1 * time.Second) }
// list1: uint64 to varint funcmain() { v := uint64(300) bytes := make([]byte, 0) bytes = binary.AppendUvarint(bytes, v) fmt.Println(len(bytes)) for i := len(bytes); i > 0; i-- { fmt.Printf("%08b ", bytes[i-1]) } }
varint 表示无符号整数
Go 标准库提供了两组 varint 函数:一组用于无符号整数(PutUvarint、Uvarint),另一组用于有符号整数(varint、Putvarint)。 让我们先看看无符号整数 varint 的实现:
1 2 3 4 5 6 7 8 9 10 11
// list2: go src PutUvarint func PutUvarint(buf []byte, x uint64) int { i := 0 for x >= 0x80 { buf[i] = byte(x) | 0x80 x >>= 7 i++ } buf[i] = byte(x) return i + 1 }
type Post struct { Id int64`json:"id,omitempty"` CreateTime time.Time `json:"create_time,omitempty"` TagList []Tag `json:"tag_list,omitempty"` Name string`json:"name,omitempty"` Score float64`json:"score,omitempty"` Category Category `json:"category,omitempty"` LikePost map[string]Post `json:"like,omitempty"` } type Tag struct { ID string`json:"id"` Name string`json:"name"` } type Category struct { ID float64`json:"id"` Name string`json:"name"` } funcmain() { b, _ := json.Marshal(new(Post)) fmt.Println(string(b)) }
Goja 因其与 Go 结构体的无缝集成而赢得了我的青睐。当你将一个 Go 结构体分配给 JavaScript 运行时中的一个值时,Goja 会自动推断字段和方法,使它们在 JavaScript 中可访问,而不需要单独的桥接层。它利用 Go 的反射能力来调用这些字段上的 getter 和 setter,提供了 Go 和 JavaScript 之间强大而透明的交互。
全局命名空间已经被变量 result 污染了。如果我用同一个池重新运行相同的代码,我会收到以下错误:SyntaxError: Identifier ‘result’ has already been declared at :1:1(0)。有一个 GitHub 问题推荐每次清除 result 的值。然而,我发现这种模式由于在处理用户提供的代码时增加的复杂性而不切实际。
// Fibonacci calculates the nth Fibonacci number. // This algorithm is not optimized and is used for demonstration purposes. func Fibonacci(n int64) int64 { if n <= 1 { return n } return Fibonacci(n-1) + Fibonacci(n-2) }
// NewHandler returns an HTTP handler that calculates the nth Fibonacci number. func NewHandler(l *slog.Logger, c cache.Cache, exp time.Duration) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { started := time.Now() defer func() { l.Info("request completed", "duration", time.Since(started).String()) }()
// consterror is a custom error type used to represent specific errors in the cache implementation. // It is derived from the int type to allow it to be used as a constant, ensuring immutability across packages. type consterror int
// Possible errors returned by the cache implementation. const ( ErrNotFound consterror = iota ErrExpired )
// _text maps consterror values to their corresponding error messages. var _text = map[consterror]string{ ErrNotFound: "cache: key not found", ErrExpired: "cache: key expired", }
// Error implements the error interface. func (e consterror) Error() string { txt, ok := _text[e] if !ok { return "cache: unknown error" } return txt }
// Cache defines the interface for a cache implementation. type Cache interface { // Set stores a key-value pair in the cache with a specified expiration time. Set(ctx context.Context, key, val string, exp time.Duration) error
// Get retrieves a value from the cache by its key. // Returns ErrNotFound if the key is not found. // Returns ErrExpired if the key has expired. Get(ctx context.Context, key string) (string, error) }
// Factory defines the function signature for creating a cache implementation. type Factory func(log *slog.Logger) (Cache, error)
// nopCache is a no-operation cache implementation. type nopCache int
// NopCache a singleton cache instance, which does nothing. const NopCache nopCache = 0
// Ensure that NopCache implements the Cache interface. var _ Cache = NopCache
// Set is a no-op and always returns nil. func (nopCache) Set(context.Context, string, string, time.Duration) error { return nil }
// Get always returns ErrNotFound, indicating that the key does not exist in the cache. func (nopCache) Get(context.Context, string) (string, error) { return "", ErrNotFound }
// loadCachePlugin loads a cache implementation from a shared object (.so) file at the specified path. // It calls the constructor function by name, passing the necessary dependencies, and returns the initialized cache. // If path is empty, it returns the NopCache implementation. func loadCachePlugin(log *slog.Logger, path, name string) (cache.Cache, error) { if path == "" { log.Info("no cache plugin configured; using nop cache") return cache.NopCache, nil }
sym, err := plug.Lookup(name) if err != nil { return nil, fmt.Errorf("lookup symbol New: %w", err) }
factoryPtr, ok := sym.(*cache.Factory) if !ok { return nil, fmt.Errorf("unexpected type %T; want %T", sym, factoryPtr) }
factory := *factoryPtr return factory(log) }
仔细看看这一行:factoryPtr, ok := sym.(cache.Factory)。我们要查找的符号是 plug.Lookup(“Factory”),正如我们所看到的,每个实现都有 var Factory cache.Factory = New,而不是 var Factory cache.Factory = New。
Go 中的 buildmode=plugin 功能是增强应用程序的强大工具,例如在 Envoy Proxy 中添加自定义缓存解决方案。它允许你构建和使用插件,使你能够在运行时加载和执行自定义代码,而无需更改主程序。这不仅有助于减少二进制文件的大小,还能加快构建过程。由于插件可以独立组成和更新,因此只有当主应用程序发生变化时才需要重建,避免了重建未更改的插件。
当然,这个方案也会存在缺点:插件加载会带来运行时开销,而且与静态链接代码相比,插件系统有一定的局限性。例如,可能存在跨平台兼容性和调试复杂性的问题。您应根据自己的具体需求仔细评估这些方面。有关使用插件的更多信息和详细警告,请参阅 Go 关于插件的官方文档。
]]>
<p class="description"></p>
<p><img src="https://" alt="" style="width:100%"></p>
[译] Range Over Function Typeshttps://cloudsjhan.github.io/2024/08/23/译-Range-Over-Function-Types/2024-08-23T09:15:48.000Z2024-08-23T09:16:55.128Z
在 Go 1.22 中作为试验特性发布,在 Go 1.23 中正式发布。我们可以在 for 循环的 range 子句中使用迭代器函数。就在前几天,官方也发布了 Range over Function Types 的教程。
Ian Lance Taylor in 20 August 2024
Go 1.23版本中函数类型范围遍历的新特性介绍
这是 Ian 在2024年GopherCon大会上演讲的博客文章版本,下面开始正文(文章较长但干货真的很多,读完会对迭代器函数的用法有新的理解)。
在 Go 1.23版本中,我们引入了一个新的语言特性:对函数类型进行范围遍历(Range over function types)。这篇博客文章将解释我们为什么要添加这个新特性,它究竟是什么,以及如何使用它。
WHY?
自 Go 1.18 版本以来,我们就能够编写新的泛型容器类型。例如,让我们实现一个非常简单的 Set 类型,一个基于 map 实现的泛型类型。
1 2 3 4 5 6 7 8 9
// Set 保存一组元素。 type Set[E comparable] struct { m map[E]struct{} }
// New 返回一个新的[Set]。 funcNew[Ecomparable]() *Set[E] { return &Set[E]{m: make(map[E]struct{})} }
// Contains 报告一个元素是否在set中。 func(s *Set[E])Contains(v E)bool { _, ok := s.m[v] return ok }
还需要一个函数来返回两个集合的并集。
1 2 3 4 5 6 7 8 9 10 11 12 13
// Union 返回两个set的并集。 funcUnion[Ecomparable](s1, s2 *Set[E]) *Set[E] { r := New[E]() // 注意for/range在内部Set字段m上。 // 我们正在遍历s1和s2中的map。 for v := range s1.m { r.Add(v) } for v := range s2.m { r.Add(v) } return r }
让我们花一点时间看看 Union 函数的实现。为了计算两个集合的并集,我们需要一种方法来获取每个集合中的所有元素。在这段代码中,我们使用了一个 for/range 语句来遍历 set 类型的未导出字段。这只在 Union 函数定义在set包中时才有效。
但是,有很多原因可能会有人想要遍历集合中的所有元素。这个 set 包必须为其用户提供一些方法来做到这一点。
这应该怎么实现呢?
Push Set 元素
一种方法是提供一个 Set 方法,该方法接受一个函数,并对 Set 中的每个元素调用该函数。我们将这称为 Push,因为 Set 将每个值推送到函数中。如果函数返回 false,我们停止调用它。
1 2 3 4 5 6 7
func(s *Set[E])Push(f func(E)bool) { for v := range s.m { if !f(v) { return } } }
funcPrintAllElements[Ecomparable](s *Set[E]) { for v := range s.All() { fmt.Println(v) } }
在这种代码中,s.All 是一个返回函数的方法。我们调用 s.All,然后使用 for/range 来遍历它返回的函数。在这种情况下,我们可以将 Set.All 做成一个迭代器函数本身,而不是让它返回一个迭代器函数。然而,在某些情况下,这行不通,比如如果返回迭代器的函数需要接受一个参数,或者需要做一些设置工作。作为一种惯例,我们鼓励所有容器类型都提供一个返回迭代器的 All 方法,这样程序员就不必记住是直接遍历 All 还是调用 All 来获取一个可以遍历的值。他们总是可以做后者。
// Filter 返回一个序列,其中包含 s 中 // 满足 f 返回 true 的元素。 funcFilter[Vany](f func(V)bool, siter.Seq[V]) iter.Seq[V] { returnfunc(yield func(V)bool) { for v := range s { if f(v) { if !yield(v) { return } } } } }
和之前的例子一样,函数签名在你第一次看到它们时看起来很复杂。一旦你超越了签名,实现就很简单了。
1 2 3 4 5 6 7
for v := range s { if f(v) { if !yield(v) { return } } }
代码遍历输入迭代器,检查过滤器函数,并用应该进入输出迭代器的值调用yield。
我们将在下面展示使用 Filter 的示例。
(Go标准库今天没有 Filter 的版本,但未来版本可能会添加。)
二叉树
作为推送迭代器对容器类型循环遍历的便利性的一个例子,让我们考虑这个简单的二叉树类型。
1 2 3 4 5
// Tree是一个二叉树。 type Tree[E any] struct { val E left, right *Tree[E] }
我们不会展示将值插入树的代码,但自然应该有某种方法来遍历树中的所有值。
事实证明,如果迭代器代码返回一个 bool,迭代器代码会更容易编写。由于 for/range 支持的函数类型不返回任何内容,这里的 All 方法返回一个小型函数字面量,它调用迭代器本身,这里称为 push,并忽略 bool 结果。
func freq(docs []string) int { var count int for _, doc := range docs { f, err := os.OpenFile(doc, os.O_RDONLY, 0) if err != nil { return 0 } data, err := io.ReadAll(f) if err != nil { return 0 } var d document if err := xml.Unmarshal(data, &d); err != nil { log.Printf("Decoding Document [Ns] : ERROR :%+v", err) return 0 } for _, item := range d.Channel.Items { if strings.Contains(strings.ToLower(item.Title), "go") { count++ } } } return count } func main() { trace.Start(os.Stdout) defer trace.Stop() files := make([]string, 0) for i := 0; i < 100; i++ { files = append(files, "index.xml") } count := freq(files) log.Println(fmt.Sprintf("find key word go %d count", count)) }
代码非常简单,我们使用 for 循环来完成任务,然后执行它:
1 2 3 4 5 6
➜ go_trace git:(main) ✗ go build ➜ go_trace git:(main) ✗ time ./go_trace 2 > trace_single.out -- result -- 2024/08/02 16:17:06 find key word go 2400 count ./go_trace 2 > trace_single.out 1.99s user 0.05s system 102% cpu 1.996 total
func concurrent(docs []string) int { var count int32 g := runtime.GOMAXPROCS(0) wg := sync.WaitGroup{} wg.Add(g) ch := make(chan string, 100) go func() { for _, v := range docs { ch <- v } close(ch) }() for i := 0; i < g; i++ { go func() { var iFound int32 defer func() { atomic.AddInt32(&count, iFound) wg.Done() }() for doc := range ch { f, err := os.OpenFile(doc, os.O_RDONLY, 0) if err != nil { return } data, err := io.ReadAll(f) if err != nil { return } var d document if err = xml.Unmarshal(data, &d); err != nil { log.Printf("Decoding Document [Ns] : ERROR :%+v", err) return } for _, item := range d.Channel.Items { if strings.Contains(strings.ToLower(item.Title), "go") { iFound++ } } } }() } wg.Wait() return int(count) }
用同样的方法运行程序:
1 2 3 4 5
go build time ./go_trace 2 > trace_pool.out --- 2024/08/02 19:27:13 find key word go 2400 count ./go_trace 2 > trace_pool.out 2.83s user 0.13s system 673% cpu 0.439 total
➜ go_trace git:(main) ✗ time GOGC=1000 ./go_trace 2 > trace_gogc_1000.out 2024/08/05 16:57:29 find key word go 2400 count GOGC=1000 ./go_trace 2 > trace_gogc_1000.out 2.46s user 0.16s system 757% cpu 0.346 total
➜ go_trace git:(main) ✗ time GOGC=off GOMEMLIMIT=124MiB ./go_trace 2 > trace_mem_limit.out 2024/08/05 18:10:55 find key word go 2400 count GOGC=off GOMEMLIMIT=124MiB ./go_trace 2 > trace_mem_limit.out 2.83s user 0.15s system 766% cpu 0.389 total
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count. // 64-bit atomic operations require 64-bit alignment, but 32-bit // compilers do not ensure it. So we allocate 12 bytes and then use // the aligned 8 bytes in them as state, and the other 4 as storage // for the sema. state1 [3]uint32 }
nocopy 是一种防止结构被复制的保护机制,将在后面介绍。
state1 主要存储计数状态和 semaphore,我们接下来将重点讨论。
要理解注释的内容,首先需要了解内存对齐方式,以及在 Add() 和 Wait() 中如何使用 state1。 内存对齐要求数据地址必须是某个值的倍数,这可以提高 CPU 读取内存数据的效率:
32 位对齐:数据的起始地址必须是 4 的倍数
64 位对齐:数据的起始地址必须是 8 的倍数
在 Add() 和 Wait() 中,计数器和等待器合并为一个 64 位整数使用。
1 2 3 4 5
statep, semap := wg.state() ... state := atomic.AddUint64(statep, uint64(delta)<<32) v := int32(state >> 32) w := uint32(state)
// Define a struct type type Person struct { Name string Age int }
func main() { // Create a struct instance person := Person{Name: "Alice", Age: 30}
// Create a pointer to the struct p := &person
// Access and modify the struct's fields through the pointer fmt.Println(p.Name) // Output: Alice fmt.Println((*p).Name) // Output: Alice p1 := p p.Age = 32 fmt.Println(p.Age) // Output: 32 fmt.Println(p1.Age) // Output: 32 }
在 Go 中,指针复制是一种浅层复制,即只复制顶层结构。如果原始结构及其副本都指向相同的底层数据,这可能会导致意想不到的行为。如果一个结构的数据被修改,可能会影响到另一个结构。
使用 noCopy 字段有助于进行静态编译检查。使用 go vet,可以检查对象或对象中的字段是否已被复制。
关于 WaitGroup 的说明
探索使用 WaitGroup 时的一些限制和潜在隐患,并学习如何避免这些问题。 如果你看过 Go 源代码,可能会注意到下面这些总结要点的经典注释:
TinyGo 通过 WebAssembly 将 Go 编程语言的强大功能和简易性扩展到微控制器和网络浏览器等受限环境。TinyGo 能够生成小二进制文件并高效使用内存,是物联网和嵌入式系统开发的理想选择。与完整的 Go 编译器相比,WebAssembly 有一些局限性,但它为 Go 开发人员在新领域创建创新应用提供了新的可能性。
{ "doc": "Sample schema to help you get started.", "fields": [ { "doc": "The int type is a 32-bit signed integer.", "name": "id", "type": "int" }, { "doc": "The string is a unicode character sequence.", "name": "name", "type": "string" }, { "doc": "The string is a unicode character sequence.", "name": "age", "type": "int" } ], "name": "sampleRecord", "type": "record" }
Add connector for topic
为刚创建的 topic 添加一个 sink connector
选择上面我们自定义的 databend connector 并配置 API key 和 secret。
近年来,函数式编程越来越受到重视,甚至在传统上与命令式或面向对象范式相关的语言中也不例外。以简单高效著称的 Go 也不例外。Lambda-Go 是一个旨在将受 Haskell 启发的函数式编程技术引入 Go 生态系统的库。在本文中,我们将探讨 Lambda-Go 的功能,以及它如何增强你的 Go 编程体验。
Lambda-Go 简介
Lambda-Go 是一个 Go 库,它通过函数式编程结构扩展了 Go 语言的功能。它提供了一系列工具和实用程序,允许开发人员编写更具表现力和更简洁的代码,同时还能利用 Go 强大的类型和性能优势。该库从 Haskell 中汲取灵感,Haskell 是一种纯函数式编程语言,以其优雅的语法和强大的抽象而著称。
Lambda-Go 的主要目标是为 Go 开发人员提供一种将函数式编程技术融入现有代码库的方法,而无需完全切换到另一种语言。这种方法可以使代码更简洁、更易维护,尤其是在处理复杂的数据转换或集合操作时。
func main() { people := []struct { Name string Age int }{ {"Alice", 25}, {"Bob", 30}, {"Charlie", 25}, {"David", 30}, } grouped := sortgroup.groupBy(people, func(p struct{ Name string; Age int }) int { return p.Age }) for age, group := range grouped { fmt.Printf("Age %d: %v\n", age, group) } }
使用 Lambda-Go 的好处
1.提高代码可读性:函数式编程模式通常使代码更具声明性,更易于理解,尤其是在处理复杂的数据转换时。
2.减少副作用:通过鼓励不变性和纯函数,Lambda-Go 可以帮助减少意外副作用导致的错误。
3.更好的抽象:程序库提供高级抽象,可简化常见的编程任务,使代码更具表现力。
4.FP 爱好者熟悉的概念:熟悉其他语言中函数式编程概念的开发人员会发现在 Go 项目中更容易应用他们的知识。
5.逐步采用:您可以在现有的 Go 代码库中逐步引入函数式编程概念,而无需完全重写。
挑战和需要考虑的因素
虽然 Lambda-Go 带来了许多好处,但也有一些挑战需要考虑: 1.性能开销:与命令式 Go 代码相比,某些函数式编程模式可能会带来轻微的性能开销。重要的是要对应用程序进行剖析,并谨慎使用这些技术。
// link to the tracepoint program that we loaded into the kernel tp, err := link.Tracepoint("sched", "sched_switch", objs.CpuProcessingTime, nil) if err != nil { log.Fatalf("opening kprobe: %s", err) } defer tp.Close()
// used as HashMap Key type processtimeKeyT struct{ Pid uint32 } // used as HashMap Value type processtimeValT struct { StartTime uint64 ElapsedTime uint64 }
这与我们在 C 程序中使用的两种类型相关:
1 2 3 4 5 6 7 8 9
// used as Hashmap Key struct key_t { __u32 pid; }; // used as Hashmap Value struct val_t { __u64 start_time; __u64 elapsed_time; };
var key processtimeKeyT // Iterate over all PIDs between 1 and 32767 (maximum PID on linux) // found in /proc/sys/kernel/pid_max for i := 1; i <= 32767; i++ { key.Pid = uint32(i) // Query the BPF map var mapValue processtimeValT if err := objs.ProcessTimeMap.Lookup(key, &mapValue); err == nil { log.Printf("CPU time for PID=%d: %dns\n", key.Pid, mapValue.ElapsedTime) } }
// Load the compiled eBPF ELF and load it into the kernel. var objs processtimeObjects if err := loadProcesstimeObjects(&objs, nil); err != nil { log.Fatal("Loading eBPF objects:", err) } defer objs.Close()
// link to the tracepoint program that we loaded into the kernel tp, err := link.Tracepoint("sched", "sched_switch", objs.CpuProcessingTime, nil) if err != nil { log.Fatalf("opening kprobe: %s", err) } defer tp.Close()
// Read loop reporting the total amount of times the kernel // function was entered, once per second. ticker := time.NewTicker(1 * time.Second) defer ticker.Stop()
log.Println("Waiting for events..") for range ticker.C { var key processtimeKeyT
// Iterate over all PIDs between 1 and 32767 (maximum PID on linux) // found in /proc/sys/kernel/pid_max for i := 1; i <= 32767; i++ { key.Pid = uint32(i) // Query the BPF map var mapValue processtimeValT if err := objs.ProcessTimeMap.Lookup(key, &mapValue); err == nil { log.Printf("CPU time for PID=%d: %dns\n", key.Pid, mapValue.ElapsedTime) } } } }
struct key_t { // This is the process ID // which we will use to identify // in the hash map __u32 pid; };
存储数据的方式是 value struct
1 2 3 4 5 6
struct val_t { // used to understand the start time of the process __u64 start_time; // used to store the elapsed time of the process __u64 elapsed_time; };
eBpf HashMap 将他们联系在一起
1 2 3 4 5 6 7 8 9 10 11 12 13
struct { // The type of BPF map we are creating __uint(type, BPF_MAP_TYPE_HASH); // specifying the type to be used for the key __type(key, struct key_t); // specifying the type to be used as the value __type(value, struct val_t); // max amount of entries to store in the map __uint(max_entries, 10240); // name of the map as well as a section macro // from the bpf lib to designate this type // as a BPF map } process_time_map SEC(".maps");
我已经添加了注释,解释这些结构中每一行的作用。
创建 eBPF 函数
最后一步是创建 eBPF 函数。为此,我们需要一个 eBPF 程序。 这是一个 C 语言函数,带有一些宏标识,这样我们就可以使用先前定义的类型进行交互,例如:
SEC("tracepoint/sched/sched_switch") int cpu_processing_time(struct sched_switch_args *ctx) { // get the current time in ns __u64 ts = bpf_ktime_get_ns(); // we need to check if the process is in our map struct key_t prev_key = { .pid = ctx->prev_pid, }; struct val_t *val = bpf_map_lookup_elem(&process_time_map, &prev_key); // if the previous PID does not exist it means that we just started // watching or we missed the start somehow // so we ignore it for now if (val) { // Calculate and store the elapsed time for the process and we reset the // start time so we can measure the next cycle of that process __u64 elapsed_time = ts - val->start_time; struct val_t new_val = {.start_time = ts, .elapsed_time = elapsed_time}; bpf_map_update_elem(&process_time_map, &prev_key, &new_val, BPF_ANY); return 0; }; // we need to check if the next process is in our map // if it's not we need to set initial time struct key_t next_key = { .pid = ctx->next_pid, }; struct val_t *next_val = bpf_map_lookup_elem(&process_time_map, &prev_key); if (!next_val) { struct val_t next_new_val = {.start_time = ts}; bpf_map_update_elem(&process_time_map, &next_key, &next_new_val, BPF_ANY); return 0; } return 0; }
// this is the structure of the sched_switch event struct sched_switch_args { char prev_comm[TASK_COMM_LEN]; int prev_pid; int prev_prio; long prev_state; char next_comm[TASK_COMM_LEN]; int next_pid; int next_prio; };
SEC("tracepoint/sched/sched_switch") int cpu_processing_time(struct sched_switch_args *ctx) { // get the current time in ns __u64 ts = bpf_ktime_get_ns(); // we need to check if the process is in our map struct key_t prev_key = { .pid = ctx->prev_pid, }; struct val_t *val = bpf_map_lookup_elem(&process_time_map, &prev_key); // if the previous PID does not exist it means that we just started // watching or we missed the start somehow // so we ignore it for now if (val) { // Calculate and store the elapsed time for the process and we reset the // start time so we can measure the next cycle of that process __u64 elapsed_time = ts - val->start_time; struct val_t new_val = {.start_time = ts, .elapsed_time = elapsed_time}; bpf_map_update_elem(&process_time_map, &prev_key, &new_val, BPF_ANY); return 0; }; // we need to check if the next process is in our map // if it's not we need to set initial time struct key_t next_key = { .pid = ctx->next_pid, }; struct val_t *next_val = bpf_map_lookup_elem(&process_time_map, &prev_key); if (!next_val) { struct val_t next_new_val = {.start_time = ts}; bpf_map_update_elem(&process_time_map, &next_key, &next_new_val, BPF_ANY); return 0; } return 0; }
char _license[] SEC("license") = "Dual MIT/GPL";
这样,我们就完成了 BPF 程序。在本系列的下一篇文章中,我将介绍用 GO 语言编写用户空间程序,并使用名为 bpf2go 的工具来帮助我们实现程序绑定。
func main() { numbers := []int{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5} // Example array totalSum := concurrentSum(numbers, parts) // Divide the array into 4 parts for summing fmt.Println("Total Sum:", totalSum) }
// sumPart sums a part of the array and sends the result to a channel. func sumPart(workerId int, nums []int, result chan<- int, wg *sync.WaitGroup) { defer wg.Done() // Ensure the WaitGroup counter decrements on function completion. sum := 0 for _, num := range nums { sum += num } fmt.Printf("Worker %d calculated sum: %d\n", workerId, sum) result <- sum // Send the partial sum to the result channel. }
// concurrentSum takes an array and the number of parts to divide it into, // then sums the array elements using concurrent goroutines. func concurrentSum(numbers []int, parts int) int { n := len(numbers) partSize := n / parts // Determine the size of each subarray fmt.Printf("Dividing the array of size %d into %d parts of size %d\n", n, parts, partSize) results := make(chan int, parts) // Channel to collect results with a buffer size var wg sync.WaitGroup // Fork step: Launch a goroutine for each part of the array for i := 0; i < parts; i++ { start := i * partSize end := start + partSize if i == parts-1 { // Ensure the last goroutine covers the remainder of the array end = n } wg.Add(1) go sumPart(i, numbers[start:end], results, &wg) }
// Close the results channel once all goroutines are done go func() { wg.Wait() close(results) }()
// Join step: Combine results totalSum := 0 for sum := range results { fmt.Printf("Received partial sum: %d\n", sum) totalSum += sum }
return totalSum }
结论
上面的示例展示了使用 Go 进行并发编程时 fork/join 模式的效率。通过将数组求和的任务分给多个 Worker,程序在多核处理器上的运行速度明显加快,使用 Go 进行并发编程任务具有的强大功能和简便性。这种模式同样可应用于其他各种计算问题。
]]>
Golang 并发的 fork/join 模式
Go 1.22 提供的更加强大的 Tracing 能力https://cloudsjhan.github.io/2024/06/21/Go-1-22-提供的更加强大的-Tracing-能力/2024-06-21T01:07:42.000Z2024-06-21T01:08:09.077Z
Trace 的优势在于它可以很容易展示出程序中难以以其他方式看到的问题。例如,许多 goroutine 阻塞在同一通道上的并发瓶颈可能在 CPU 分析中很难看到,因为根本没有执行可供采样。但在执行追踪中,许多堆栈可以清晰度显示出来,并且阻塞的 goroutine 的堆栈跟踪将迅速指向罪魁祸首。
Go 开发者甚至能够使用 task、regions和 logs 来对他们自己的程序进行工具化,他们可以使用这些来将他们的高级关注点与低级执行细节相关联。
存在的问题
不幸的是,执行追踪中的丰富信息常常难以获得。历史上,追踪存在四个主要问题。
追踪有高开销。
追踪没有很好地扩展,并且可能变得太大而无法分析。
通常不清楚何时开始追踪以捕获特定的不良行为。
只有一部分 gopher 能够程序化地分析追踪,因为缺乏通用的公共包来解析和解释执行追踪。
如果你在过去几年中使用过追踪,你很可能因为这些问题中的一个或多个而感到沮丧。但我们很高兴地分享,在过去两个 Go 版本中,我们在所有这四个领域都取得了巨大进展。
低开销追踪
在 Go 1.21 之前,追踪的运行时开销对于许多应用程序来说在 10-20% 的 CPU 之间,这限制了追踪的使用情况,而不是像 CPU 分析那样的持续使用。事实证明,追踪成本的很大一部分来自于回溯。运行时产生的许多事件都附有堆栈跟踪,这对于实际识别 goroutine 在关键时刻正在做什么非常有价值。
得益于 Felix Geisendörfer 和 Nick Ripley 在优化回溯效率方面的工作,执行追踪的运行时 CPU 开销已经大幅降低,对于许多应用程序降至 1-2%。你可以在 Felix 关于此主题的优秀博客文章中阅读更多关于这项工作的内容。
可扩展追踪
追踪格式及其事件的设计围绕相对高效的发射,但需要工具来解析并保留整个追踪的状态。几百 MB 的追踪可能需要几个 Gi B的 RAM 来分析!
var blocked int var blockedOnNetwork int for { // 读取事件。 ev, err := r.ReadEvent() if err == io.EOF { break } elseif err != nil { log.Fatal(err) }
// 处理它。 if ev.Kind() == trace.EventStateTransition { st := ev.StateTransition() if st.Resource.Kind == trace.ResourceGoroutine { from, to := st.Goroutine()
// 查找阻塞的goroutine,并计数。 if from.Executing() && to == trace.GoWaiting { blocked++ if strings.Contains(st.Reason, "network") { blockedOnNetwork++ } } } } } // 打印我们发现的内容。 p := 100 * float64(blockedOnNetwork) / float64(blocked) fmt.Printf("%2.3f%% instances of goroutines blocking were to block on the network\n", p)
type A struct { x int y string z struct{} } type B struct { x int z struct{} y string } func main() { println(unsafe.Alignof(A{})) println(unsafe.Alignof(B{})) println(unsafe.Sizeof(A{})) println(unsafe.Sizeof(B{})) } /** 8 8 32 24 **/
type A struct { x int y string z struct{} } type B struct { x int z struct{} y string } func main() { a := A{} b := B{} fmt.Printf("%p\n", &a.y) fmt.Printf("%p\n", &a.z) fmt.Printf("%p\n", &b.y) fmt.Printf("%p\n", &b.z) } /** 0x1400012c008 0x1400012c018 0x1400012e008 0x1400012e008 **/
// indirect 注释表示这里的项目没有直接导入 C 模块,而是因为 A 或 B 需要它才导入的。
还有一个要注意点:go get 不会更新或添加缺失的测试依赖项。要包含这些依赖项,请使用 -t 标志,如 go get -t ./...
go get
这里举几个例子,看看 go get 在不同情况下是如何工作的。
使用 go get .或 go get ./…查找当前目录或其子目录中所有缺失的依赖项,并将其添加到 go.mod 文件中。 这意味着它会检查任何尚未列出的依赖项,并将其添加进来。除非你特别要求,否则它不会将现有的依赖项更新到最新版本,比如下一个例子中的 -u 标志。
1
go get -u .
在 go get .中使用 -u 标志,会将当前目录中的现有依赖项更新到最新的次版本或补丁版本。请记住,它不会更新到新的主版本,因为它们被视为不同的模块。 要将主模块的所有依赖项更新到最新版本,可以使用 go get -u ./...
在下面的几个情况下,即使不指定 -u 标志,go get 仍会更新过时或丢失的依赖项。
go get github.com/user/project
此命令下载模块 github.com/user/project,并将其添加到 go.mod 文件中。如果该模块已列在该文件中,则会将其更新为最新的次版本或补丁版本。基本上,如果你不指定版本(或版本查询后缀),它会假定你想升级到最新版本,就像使用 go get github.com/user/project@upgrade 一样。
如果只是在没有任何参数的情况下运行 go install 会怎样呢? go install 就会下载缺失的依赖项,并在当前目录下构建当前模块。 这导致一些人误用 go install 来管理依赖关系,因为它确实会下载依赖关系。但这并不是它的主要工作,它实际上是要构建你的项目,并将生成的二进制文件安装到 $GOBIN 目录中。
go install 用于构建和安装软件包,而 go get 用于管理依赖关系。有些开发者经常会感到困惑,这是因为在旧版本的 Go 中,go get 确实是用来在更新 go.mod 文件后构建软件包,然后将它们安装到 $GOPATH/bin。
但从 Go 1.16 开始,go install 成为了构建和安装的首选命令,而 go get 则专注于管理 go.mod 文件中的需求。
func Test1000Allocs(t *testing.T) { go func() { for { i := 123 reader(&i) } }()
for i := 0; i < 1000; i++ { ii := i i = *reader(&ii) }
runtime.GC() }
func Test10000000000Allocs(t *testing.T) { go func() { for { i := 123 reader(&i) } }()
for i := 0; i < 10000000000; i++ { ii := i i = *reader(&ii) }
runtime.GC() }
//go:noinline func reader(i *int) *int { ii := i return ii }
我们运行每个测试时都启用了跟踪信息:
1 2 3 4
GOGC=off go test -run=Test1000Allocs -trace=trace1.out GOGC=off go test -run=Test10000000000Allocs -trace=trace2.out go tool trace trace1.out go tool trace trace2.out
$ mkdir memcached-operator $ cd memcached-operator $ operator-sdk init --domain=example.com --repo=github.com/example/memcached-operator Writing scaffold for you to edit... Get controller runtime: $ go get sigs.k8s.io/controller-runtime@v0.7.0 Update go.mod: $ go mod tidy
Running make: $ make go: creating new go.mod: module tmp Downloading sigs.k8s.io/controller-tools/cmd/controller-gen@v0.4.1 go: found sigs.k8s.io/controller-tools/cmd/controller-gen in sigs.k8s.io/controller-tools v0.4.1 /Users/username/workspace/projects/memcached-operator/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." go fmt ./... go vet ./... go build -o bin/manager main.go
domin 用于 operator 创建的任何 API Group,因此这里的 API Group 是 *.example.com。
大家可能熟悉的一个 API Group 是 rbac.authorization.k8s.io,创建 RBAC 资源(如 ClusterRoles 和 ClusterBindings)的功能通常就设置在 Kubernetes 集群上。operator-sdk 允许您指定一个自定义域,将其附加到您定义的任何 API 组,以帮助避免名称冲突。
Writing scaffold for you to edit... api/v1alpha1/memcached_types.go controllers/memcached_controller.go Running make:
$ make /Users/username/workspace/projects/memcached-operator/bin/controller-gen object:headerFile="hack/boilerplate.go.txt" paths="./..." go fmt ./... go vet ./... go build -o bin/manager main.go
--group 是自定义资源所在的组,因此它最终会出现在 API Group “cache.example.com “中。
// EDIT THIS FILE! THIS IS SCAFFOLDING FOR YOU TO OWN! // NOTE: json tags are required. Any new fields you add must have json tags for the fields to be serialized. // MemcachedSpec defines the desired state of Memcached type MemcachedSpec struct { // INSERT ADDITIONAL SPEC FIELDS - desired state of cluster // Important: Run "make" to regenerate code after modifying this file // Foo is an example field of Memcached. Edit Memcached_types.go to remove/update Foo string `json:"foo,omitempty"` } // MemcachedStatus defines the observed state of Memcached type MemcachedStatus struct { // INSERT ADDITIONAL STATUS FIELD - define observed state of cluster // Important: Run "make" to regenerate code after modifying this file }
// MemcachedSpec defines the desired state of Memcached type MemcachedSpec struct { // +kubebuilder:validation:Minimum=0 // Size is the size of the memcached deployment Size int32 `json:"size"` } // MemcachedStatus defines the observed state of Memcached type MemcachedStatus struct { // Nodes are the names of the memcached pods Nodes []string `json:"nodes"` }
Size 是一个整数,用于确定 Memcached 集群中的节点数量。我们在 Status 中添加了一个字符串数组,用于存储集群中包含的节点的 IP 地址。需要注意的是,这个特定的实现方式只是一个示例。 注意父 Memcached 结构 Status 字段的 Kubebuilder 子资源标记。这将在生成的 CRD 清单中添加 Kubernetes 状态子资源。这样,控制器就可以只更新状态字段,而无需更新整个对象,从而提高性能。
1 2 3 4 5 6 7 8
// Memcached is the Schema for the memcacheds API // +kubebuilder:subresource:status type Memcached struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"` Spec MemcachedSpec `json:"spec,omitempty"` Status MemcachedStatus `json:"status,omitempty"` }
// Reconcile is part of the main kubernetes reconciliation loop which aims to // move the current state of the cluster closer to the desired state. // TODO(user): Modify the Reconcile function to compare the state specified by // the Memcached object against the actual cluster state, and then // perform operations to make the cluster state reflect the state specified by // the user. //// For more details, check Reconcile and its Result here: // - https://pkg.go.dev/sigs.k8s.io/controller-runtime@v0.7.0/pkg/reconcile func (r *MemcachedReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { _ = r.Log.WithValues("memcached", req.NamespacedName) // your logic here return ctrl.Result{}, nil }
$ kubectl get crds NAME CREATED AT catalogsources.operators.coreos.com 2021-01-22T00:13:22Z clusterserviceversions.operators.coreos.com 2021-01-22T00:13:22Z installplans.operators.coreos.com 2021-01-22T00:13:22Z memcacheds.cache.example.com 2021-02-06T00:52:38Z operatorgroups.operators.coreos.com 2021-01-22T00:13:22Z rbacsyncs.ibm.com 2021-01-22T00:08:59Z subscriptions.operators.coreos.com 2021-01-22T00:13:22Z
运行控制器的部署和 Pod:
1 2 3 4 5 6 7
$ kubectl --namespace memcached-operator-system get deployments NAME READY UP-TO-DATE AVAILABLE AGE memcached-operator-controller-manager 1/1 1 1 2m18s
$ kubectl --namespace memcached-operator-system get pods NAME READY STATUS RESTARTS AGE memcached-operator-controller-manager-76b588bbb5-wvl7b 2/2 Running 0 2m44s
当 pod 开始运行,我们的 Operator 就可以使用了。编辑 config/samples/cache_v1alpha1_memcached.yaml 中的示例 YAML,加入一个大小整数,就像在自定义资源规范中定义的那样:
systemPrompt := `You are a programmatic country information API used software applications. All input messages provided MUST adhere to the CountryRequest schema: validate them and throw an error if not. Your responses MUST adhere to the CountryResponse schema ONLY with no additional narrative or markup, backquotes or anything. message CountryRequest { string country = 1; } message CountryResponse { string country = 1; int32 country_population = 2; string capital = 3; int32 capital_population = 4; int64 gdp_usd = 5; }
import _ "unsafe" // Required to use linkname //go:linkname main.fastHandle func fastHandle(input io.Writer) error { ... } // package main func fastHandle(input io.Writer) error // The main package can directly use fastHandle
并发是 Go 的核心功能之一,它使开发人员能够高效地同时执行多个进程。然而,管理并发性需要谨慎的同步,以避免常见的隐患,如竞赛条件,即两个或多个进程试图同时修改共享数据。Mutex(互斥锁)是 Go 程序员并发工具包中的一个重要工具。本文将探讨 Golang Mutex 的复杂性,说明何时以及如何正确使用它,以确保数据完整性和程序稳定性。
Understanding Golang Mutex
Mutex 是一种同步原语,可用于确保每次只有一个 goroutine 访问代码的关键部分。它用于保护并发程序(由 Go 运行时管理的轻量级线程)对数据和其他资源的访问。
在 Go 中,互斥由 sync 包提供,主要类型是 sync.Mutex 和 sync.RWMutex:
type Person struct { ID uint Name string Age int } funcMarshalPerson() { p := Person{ ID: 1, Name: "Bruce", Age: 18, } output, err := json.Marshal(p) if err != nil { panic(err) } println(string(output)) } funcUnmarshalPerson() { str := `{"ID":1,"Name":"Bruce","Age":18}` var p Person err := json.Unmarshal([]byte(str), &p) if err != nil { panic(err) } fmt.Printf("%+v\n", p) }
// The structure used here is the same as the previous one, // so I won't repeat it. error is also not captured to save space.
func MarshalPerson() { p := Person{ ID: 1, Name: "Bruce", address: address{ Code: 100, Street: "Main St", }, } // It would be more pretty by MarshalIndent output, _ := json.MarshalIndent(p, "", " ") println(string(output)) } func UnmarshalPerson() { str := `{"ID":1,"Name":"Bruce","address":{"Code":100,"Street":"Main St"}}` var p Person _ = json.Unmarshal([]byte(str), &p) fmt.Printf("%+v\n", p) } // Output MarshalPerson: { "ID": 1, "Name": "Bruce", "Code": 100, "Street": "Main St" } // Ouptput UnmarshalPerson: {ID:1 Name:Bruce address:{Code:0 Street:}}
这里先声明一个 Person 对象,然后使用 MarshalIndent 美化序列化结果并打印出来。从打印输出中我们可以看到,整个 Person 对象都被扁平化了。就 Person 结构而言,尽管进行了组合,但它看起来仍有一个地址成员字段。因此,有时我们会想当然地认为 Person 的序列化 JSON 看起来是这样的:
1 2 3 4 5 6 7 8 9
// The imagine of JSON serialization result { "ID": 1, "Name": "Bruce", "address": { "Code": 100, "Street": "Main St" } }
但事实并非如此,它被扁平化了。这更符合我们之前直接通过 Person 访问地址成员时的感觉,即地址成员似乎直接成为了 Person 的成员。这一点需要注意,因为这种组合会使序列化后的 JSON 结果扁平化。
// PartUpdateIssue simulates parsing two different // JSON strings with the same structure func PartUpdateIssue() { var p Person // The first data has the ID field and is not 0 str := `{"ID":1,"Name":"Bruce"}` _ = json.Unmarshal([]byte(str), &p) fmt.Printf("%+v\n", p) // The second data does not have an ID field, // deserializing it again with p preserves the last value str = `{"Name":"Jim"}` _ = json.Unmarshal([]byte(str), &p) // Notice the output ID is still 1 fmt.Printf("%+v\n", p) } // Output {ID:1 Name:Bruce} {ID:1 Name:Jim}
许多开发人员一听到指针这个词就头疼不已,其实大可不必。但 Go 中的指针确实给开发人员带来了 Go 程序中最常见的 panic 之一:空指针异常。当指针与 JSON 结合时会发生什么呢?
看下面的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
type Person struct { ID uint Name string Address *Address }
func UnmarshalPtr() { str := `{"ID":1,"Name":"Bruce"}` var p Person _ = json.Unmarshal([]byte(str), &p) fmt.Printf("%+v\n", p) // It would panic this line // fmt.Printf("%+v\n", p.Address.Street) } // Output {ID:1 Name:Bruce Address:<nil>}
if r.TLS == nil { log.Printf("Request must be over TLS") http.Error(w, "Request must be over TLS", http.StatusForbidden) return } iflen(r.TLS.PeerCertificates) == 0 { log.Printf("Request must contain a client certificate") http.Error(w, "Request must contain a client certificate", http.StatusForbidden) return }
cnName := r.TLS.PeerCertificates[0].Subject.CommonName log.Printf("Client CN: %s", cnName) for _, v := range mapping { if v.CertCN == cnName { rp := httputil.NewSingleHostReverseProxy(targetUrl)
]]>
使用 Golang 创建反向代理
Observability with OpenTelemetry and Gohttps://cloudsjhan.github.io/2024/05/13/Observability-with-OpenTelemetry-and-Go/2024-05-13T03:08:11.000Z2024-05-13T03:09:07.272Z
]]>
Observability with OpenTelemetry and Go
什么情况下使用 ErrGroup VS waitGroup?https://cloudsjhan.github.io/2024/05/11/什么情况下使用-ErrGroup-VS-waitGroup?/2024-05-11T12:43:56.000Z2024-05-11T12:46:03.738Z
Goroutine 是编写 Go 语言并发程序的强大工具。然而管理协程,特别是在处理协程的错误时,可能会变得繁琐。这时,x/sync 包中的 errgroup 就派上用场了。它提供了一种简化的方法来处理并发任务及其错误。
]]>
什么情况下使用 ErrGroup VS waitGroup?
Golang 实现枚举的各种方法及最佳实践https://cloudsjhan.github.io/2024/05/07/Golang-实现枚举的各种方法及最佳实践/2024-05-07T14:24:01.000Z2024-05-07T14:24:48.865Z
枚举提供了一种表示一组命名常量的方式。虽然 Go 语言没有内置的枚举类型,但开发者可以通过常量/自定义类型来模拟类似枚举的行为。
枚举在编程语言中扮演着至关重要的角色,提供了一种简洁而富有表现力的方式来定义一组命名常量。虽然像Java或C#这样的语言提供了对枚举的内置支持,但Go采用了不同的方法。在 Go 中,枚举并不是一种原生的语言特性,但开发者有几种技术可供使用,以实现类似的功能。 本文深入探讨了 Go 语言中的枚举,探索了定义和有效使用它们的各种技术。通过代码示例、比较和实际用例,我们的目标是掌握枚举并在 Go 项目中高效使用它们。
Understanding Enum
在 Go 语言中,枚举(enumerations 的缩写)提供了一种表示一组命名常量的方式。虽然 Go 语言没有像其他一些语言那样内建的枚举类型,但开发者可以使用常量或自定义类型来模拟类似枚举的行为。让我们深入了解 Go 中枚举的目的和语法:
Debezium is an open source distributed platform for change data capture. Start it up, point it at your databases, and your apps can start responding to all of the inserts, updates, and deletes that other apps commit to your databases. Debezium is durable and fast, so your apps can respond quickly and never miss an event, even when things go wrong.
]]>
数据同步工具考古
databend debezium server support auto schema evolutionhttps://cloudsjhan.github.io/2024/01/25/databend-debezium-server-support-auto-schema-evolution/2024-01-25T09:29:12.000Z2024-01-27T15:49:04.579Z
背景
Debezium Server Databend 是一个基于 Debezium Engine 自研的轻量级 CDC 项目,用于实时捕获数据库更改并将其作为事件流传递最终将数据写入目标数据库 Databend。它提供了一种简单的方式来监视和捕获关系型数据库的变化,并支持将这些变化转换为可消费事件。使用 Debezium server databend 实现 CDC 无须依赖大型的 Data Infra 比如 Flink, Kafka, Spark 等,只需一个启动脚本即可开启实时数据同步。
# mysql source debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector debezium.source.offset.storage.file.filename=data/offsets.dat debezium.source.offset.flush.interval.ms=60000
debezium.source.database.hostname=127.0.0.1 debezium.source.database.port=3306 debezium.source.database.user=root debezium.source.database.password=123456 debezium.source.database.dbname=mydb debezium.source.database.server.name=from_mysql debezium.source.include.schema.changes=false debezium.source.table.include.list=mydb.products # debezium.source.database.ssl.mode=required # Run without Kafka, use local file to store checkpoints debezium.source.database.history=io.debezium.relational.history.FileDatabaseHistory debezium.source.database.history.file.filename=data/status.dat # do event flattening. unwrap message! debezium.transforms=unwrap debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState debezium.transforms.unwrap.delete.handling.mode=rewrite debezium.transforms.unwrap.drop.tombstones=true
# ############ SET LOG LEVELS ############ quarkus.log.level=INFO # Ignore messages below warning level from Jetty, because it's a bit verbose quarkus.log.category."org.eclipse.jetty".level=WARN
INSERTINTO products VALUES (default,"scooter","Small 2-wheel scooter"), (default,"car battery","12V car battery"), (default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"), (default,"hammer","12oz carpenter's hammer"), (default,"hammer","14oz carpenter's hammer"), (default,"hammer","16oz carpenter's hammer"), (default,"rocks","box of assorted rocks"), (default,"jacket","water resistent black wind breaker"), (default,"cloud","test for databend"), (default,"spare tire","24 inch spare tire");
Databend Cloud 中创建 Database
1
createdatabase debezium
NOTE: 用户可以不必先在 Databend 中创建表,系统检测到后会自动为用户建表。
启动 Debezium Server Databend
1
bash run.sh
首次启动会进入 init snapshot 模式,通过配置的 Batch Size 全量将 MySQL 中的数据同步到 Databend,所以在 Databend 中可以看到 MySQL 中的数据已经同步过来了:
改变 Mysql 表结构
1
altertable products add columm a int;
在 products 表中新增一列 a int
同时在 Databend Cloud 中也可以看到目标同步表的结构也随之变更了:
此时在 mysql 中插入数据,新的数据就会以新的 Schema 形式写入目标表:
结论
Debezium Server Databend 在支持 Auto Schema Evolution 之后,用户无需在数据源发生 schema 变更时手动介入,大大降低用户的运维成本;只需对同步任务进行简单配置即可将多表、多个数据库同步至下游,提高了数据同步的效率并且降低了用户的开发难度。
]]>
Databend debezium server support auto schema evolution
(持续更新)Databend SDK 接入最佳实践&常见问题https://cloudsjhan.github.io/2024/01/06/Databend-SDK-接入最佳实践-常见问题/2024-01-06T09:45:41.000Z2024-01-06T12:38:43.804Z
c = Client.from_url(databend_url) c.execute('CREATE TABLE if not exists test (x Int32,y VARCHAR)') t, r = c.execute('INSERT INTO test VALUES', [(3, 'aa'),(4,'bb')],with_column_types=True) # execute 返回值有两个,第一个是(column_name, column_type):[('a', 'Int32'), ('b', 'String')], 只有当 with_column_types=True 的时候才返回,默认为 False; # 第二个返回值是数据集: [(1, 'a'), (2, 'b')]
批量插入
1 2 3 4 5 6 7 8
c = Client.from_url(databend_url) c.execute('DROP TABLE IF EXISTS test') c.execute('CREATE TABLE if not exists test (x Int32,y VARCHAR)') c.execute('DESC test') _, r1 = c.execute('INSERT INTO test VALUES', [(3, 'aa'), (4, 'bb')]) assertEqual(r1, 2) _, ss = c.execute('select * from test') assertEqual(ss, [(3, 'aa'), (4, 'bb')])
let dsn = "databend://root:@localhost:8000/default?sslmode=disable".to_string(); let client = Client::new(dsn); let conn = client.get_conn().await.unwrap();
let sql_create = "CREATE TABLE books ( title VARCHAR, author VARCHAR, date Date );"; conn.exec(sql_create).await.unwrap(); let sql_insert = "INSERT INTO books VALUES ('The Little Prince', 'Antoine de Saint-Exupéry', '1943-04-06');"; conn.exec(sql_insert).await.unwrap();
请求单行数据
1 2 3
let row = conn.query_row("SELECT * FROM books;").await.unwrap(); let (title,author,date): (String,String,i32) = row.unwrap().try_into().unwrap(); println!("{} {} {}", title, author, date);
GET /connectors – 返回所有正在运行的connector名。 POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。 GET /connectors/{name} – 获取指定connetor的信息。 GET /connectors/{name}/config – 获取指定connector的配置信息。 PUT /connectors/{name}/config – 更新指定connector的配置信息。
因为 Connector 需要与数据库进行通信,所以还需要 JDBC 驱动程序。JDBC Connector 插件也没有内置 MySQL 驱动程序,需要我们单独下载驱动程序。MySQL 为许多平台提供了 JDBC 驱动程序。选择 Platform Independent 选项,然后下载压缩的 TAR 文件。该文件包含 JAR 文件和源代码。将此 tar.gz 文件的内容解压到一个临时目录。将 jar 文件(例如,mysql-connector-java-8.0.17.jar),并且仅将此 JAR 文件复制到与 kafka-connect-jdbc jar 文件相同的 libs 目录下:
[2023-09-06 17:39:23,128] WARN [databend|task-0] These configurations '[metrics.context.connect.kafka.cluster.id]' were supplied but are not used yet. (org.apache.kafka.clients.consumer.ConsumerConfig:385) [2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka version: 3.4.0 (org.apache.kafka.common.utils.AppInfoParser:119) [2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka commitId: 2e1947d240607d53 (org.apache.kafka.common.utils.AppInfoParser:120) [2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka startTimeMs: 1693993163128 (org.apache.kafka.common.utils.AppInfoParser:121) [2023-09-06 17:39:23,148] INFO Created connector databend (org.apache.kafka.connect.cli.ConnectStandalone:113) [2023-09-06 17:39:23,148] INFO [databend|task-0] [Consumer clientId=connector-consumer-databend-0, groupId=connect-databend] Subscribed to topic(s): test_kafka (org.apache.kafka.clients.consumer.KafkaConsumer:969) [2023-09-06 17:39:23,150] INFO [databend|task-0] Starting Databend Sink task (com.databend.kafka.connect.sink.DatabendSinkConfig:33) [2023-09-06 17:39:23,150] INFO [databend|task-0] DatabendSinkConfig values:...
# mysql source debezium.source.connector.class=io.debezium.connector.mysql.MySqlConnector debezium.source.offset.storage.file.filename=data/offsets.dat debezium.source.offset.flush.interval.ms=60000
debezium.source.database.hostname=127.0.0.1 debezium.source.database.port=3306 debezium.source.database.user=root debezium.source.database.password=123456 debezium.source.database.dbname=mydb debezium.source.database.server.name=from_mysql debezium.source.include.schema.changes=false debezium.source.table.include.list=mydb.products # debezium.source.database.ssl.mode=required # Run without Kafka, use local file to store checkpoints debezium.source.database.history=io.debezium.relational.history.FileDatabaseHistory debezium.source.database.history.file.filename=data/status.dat # do event flattening. unwrap message! debezium.transforms=unwrap debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState debezium.transforms.unwrap.delete.handling.mode=rewrite debezium.transforms.unwrap.drop.tombstones=true
# ############ SET LOG LEVELS ############ quarkus.log.level=INFO # Ignore messages below warning level from Jetty, because it's a bit verbose quarkus.log.category."org.eclipse.jetty".level=WARN
Scenario: Databend-Driver Async Operations Given A new Databend-Driver Async Connector When Async exec "CREATE TABLE if not exists test_data (x Int32,y VARCHAR)" When Async exec "INSERT INTO test_data(x,y) VALUES(1,'xx')" Then The select "SELECT * FROM test_data" should run
.... Finished dev [unoptimized + debuginfo] target(s) in 8.71s 📦 Built wheel for abi3 Python ≥ 3.7 to /var/folders/x5/4hndsx0x7cb5_45qgpfqx4th0000gn/T/.tmpyzRsUc/databend_driver-0.0.1-cp37-abi3-macosx_11_0_arm64.whl 🛠 Installed databend-driver-0.0.1
]]>
2022 NO.40 weekly report
2022-41 homebrew formula example for gohttps://cloudsjhan.github.io/2022/10/06/homebrew-formula-example-for-go/2022-10-06T12:35:49.000Z2022-10-09T09:41:42.288Z
classBendsql < Formula desc "Work seamlessly with Databend Cloud from the command line." homepage "https://github.com/databendcloud/bendsql" url "https://github.com/databendcloud/bendsql/releases/download/v0.0.2/bendsql-darwin-amd64.tar.gz" sha256 "25c1a2a4e1922261535325634a939fe42a0ffcc12ae6c262ed7021dab611f622" license "MIT" head "https://github.com/databendcloud/bendsql.git", branch:"main"
depends_on "go" => :build
definstall system "go", "build", *std_go_args(ldflags:"-s -w") end
test do system "make test" end end
根据 homebrew-core 的文档,在提 PR 之前要完成几个前置操作:
当执行到 brew test bendsql 的时候,发现向 homebrew 官方仓库提交应用是需要满足一定条件的:
所以只要在 databendcloud 的账户下,新建一个这样的 repo,将上面配好的 formula 提交进去就可以 brew tap databendcloud/homebrew-tap && brew install bendsql 很方便地下载了。
]]>
homebrew formula example for go
2022 40 Open source weekly reporthttps://cloudsjhan.github.io/2022/09/25/2022-40-Open-source-weekly-report/2022-09-25T03:10:04.000Z2022-10-21T10:38:41.015Z
背景
不知不觉 Weekly report 已拖更三周,除了日常忙碌之外,也是觉得没有什么特别值得写的。 八月中旬的时候开始着手写一个工具 - bendsql(见33 weekly report),用来帮助用户更高效地操作 Databend Cloud,当时是用了大概一周的时间完成了这个项目,经过几周的内部使用和迭代,现在已经被用在 perf test 和 e2e test 中,跑得还算稳定QUQ,所以决定本周将其开源,让更多的用户/开发者使用并参与到产品的开发中。
CORE COMMANDS create: Create a warehouse delete: Delete a warehouse ls: show warehouse list resume: Resume a warehouse status: show warehouse status suspend: Suspend a warehouse
INHERITED FLAGS --help Show help for command
LEARN MORE Use 'bendsql <command> <subcommand> --help' for more information about a command.
参考使用文档即可,这里就不详细展开了。
操作 stage
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Operate stage
USAGE bendsql stage <command> [flags]
CORE COMMANDS ls: List stage or files in stage upload: Upload file to stage using warehouse
INHERITED FLAGS --help Show help for command
LEARN MORE Use 'bendsql <command> <subcommand> --help' for more information about a command.
以及 Pod 是否已经完成调度,如果未完成调度的话就无法完成原地重启(无法使用部署到节点上的 kruise-daemon):
1 2 3 4 5
if !kubecontroller.IsPodActive(pod) { return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in an inactive Pod")) } elseif pod.Spec.NodeName == "" { return admission.Errored(http.StatusBadRequest, fmt.Errorf("not allowed to recreate containers in a pending Pod")) }
1.3 将 Pod 中的信息注入到 CRR
CRR 的运行需要获取 Pod 的信息,比如获取 Pod 中的 Lifecycle.PreStop 让 kruise-daemon 执行 preStop hook 后把容器停掉,获取指定容器的 containerID 来判断重启后 containerID 的变化等。
type ContainerRecreateRequestStatus struct { // Phase of this ContainerRecreateRequest, e.g. Pending, Recreating, Completed Phase ContainerRecreateRequestPhase `json:"phase"` // Represents time when the ContainerRecreateRequest was completed. It is not guaranteed to // be set in happens-before order across separate operations. // It is represented in RFC3339 form and is in UTC. CompletionTime *metav1.Time `json:"completionTime,omitempty"` // A human readable message indicating details about this ContainerRecreateRequest. Message string`json:"message,omitempty"` // ContainerRecreateStates contains the recreation states of the containers. ContainerRecreateStates []ContainerRecreateRequestContainerRecreateState `json:"containerRecreateStates,omitempty"` } type ContainerRecreateRequestContainerRecreateState struct { // Name of the container. Name string`json:"name"` // Phase indicates the recreation phase of the container. Phase ContainerRecreateRequestPhase `json:"phase"` // A human readable message indicating details about this state. Message string`json:"message,omitempty"` }
CRR controller 不断更新 container 的重启信息到 status 中。
1 2 3
func(r *ReconcileContainerRecreateRequest)syncContainerStatuses(crr *appsv1alpha1.ContainerRecreateRequest, pod *v1.Pod)error { ... }
controller 同步 container status 的逻辑非常重要,在这里笔者曾经遇到一个诡异的问题,就是创建了好几个 CRR 后,其中几个 CRR 一直卡在 Recreating 的状态,即使 container 已经重启完成或者 TTL 到期也不会发生变化,详情可以见这个 issue。原因就是同步 container status 的逻辑跟时钟同步有关:
1 2 3 4 5 6 7 8 9
containerStatus := util.GetContainerStatus(c.Name, pod) if containerStatus == nil { klog.Warningf("Not found %s container in Pod Status for CRR %s/%s", c.Name, crr.Namespace, crr.Name) continue } elseif containerStatus.State.Running == nil || containerStatus.State.Running.StartedAt.Before(&crr.CreationTimestamp) { // 只有 container 的创建时间晚于 crr 的创建时间,才认为 crr 重启了 container,假如此时 CRR 所处节点或者 Pod 所在节点的时钟发生漂移,那有可能出现 container 创建的时间早于 crr 创建时间,即使该 container 是由 crr 控制重启。 continue } ...
经过排查后发现确实是好多 k8s Node 的 NTP server 出现问题导致时钟漂移,再加上上述的逻辑,就不难解释为何 CRR 会卡住不动了。
2.2 make pod not ready
CRR 在重启 container 之前会给 Pod 注入一个 v1.PodConditionType - KruisePodReadyConditionType 并置为 false, 使 Pod 进入 not ready 状态,从 service 的 Endpoint 上摘掉流量。
// once first update its phase to recreating if crr.Status.Phase != appsv1alpha1.ContainerRecreateRequestRecreating { return c.updateCRRPhase(crr, appsv1alpha1.ContainerRecreateRequestRecreating) }
3.3 wait for unready grace period
CRR 中的 unreadyGracePeriodSeconds 表示在 2.2 步骤中将 Pod 设置为 not ready 后等待多久再执行 restart container。
1 2 3 4 5 6 7 8
// crr_daemon_controller.go
leftTime := time.Duration(*crr.Spec.Strategy.UnreadyGracePeriodSeconds)*time.Second - time.Since(unreadyTime) if leftTime > 0 { klog.Infof("CRR %s/%s is waiting for unready grace period %v left time.", crr.Namespace, crr.Name, leftTime) c.queue.AddAfter(crr.Namespace+"/"+crr.Spec.PodName, leftTime+100*time.Millisecond) returnnil }
if crr.Spec.ActiveDeadlineSeconds != nil { leftTime := time.Duration(*crr.Spec.ActiveDeadlineSeconds)*time.Second - time.Since(crr.CreationTimestamp.Time) if leftTime <= 0 { klog.Warningf("Complete CRR %s/%s as failure for recreating has exceeded the activeDeadlineSeconds", crr.Namespace, crr.Name) return reconcile.Result{}, r.completeCRR(crr, "recreating has exceeded the activeDeadlineSeconds") } duration.Update(leftTime) }
符合原地升级条件的 pod 都会在 condition 中增加 InPlaceUpdateReady 的 ConditionType,开始原地升级的时候,将该值置为 false,如果 Pod 上层有 Service 的话,就会自动将准备升级的 pod 从 Endpoint 上摘下,避免升级过程中有流量损失。
原地升级中提供了 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。 这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
1 2 3 4 5 6 7 8 9
if spec.GraceSeconds <= 0 { if clone, err = opts.PatchSpecToPod(clone, spec, &inPlaceUpdateState); err != nil { return err } appspub.RemoveInPlaceUpdateGrace(clone) } else { // Put the info into annotation // 此处设置了 GracePeriod 后,效果会在 上面的 reconcile controller 中体现 }
if utilfeature.DefaultFeatureGate.Enabled(features.DaemonWatchingPod) { // DaemonWatchingPod enables kruise-daemon to list watch pods that belong to the same node. containerMetaController, err := containermeta.NewController(opts) if err != nil { returnnil, fmt.Errorf("failed to new containermeta controller: %v", err) } runnables = append(runnables, containerMetaController) }
// Run the pre-stop lifecycle hooks if applicable and if there is enough time to run it if containerSpec.Lifecycle != nil && containerSpec.Lifecycle.PreStop != nil && gracePeriod > 0 { gracePeriod = gracePeriod - m.executePreStopHook(pod, containerID, containerSpec, gracePeriod) } ... err := m.runtimeService.StopContainer(containerID.ID, gracePeriod) ...
CD 平台是掌门的持续交付系统,Triton 作为 CD 平台的核心容器发布组件,自 2020.4 月在 CD 平台上正式上线,支撑了掌门近 1000 个应用从虚机迁移至容器的过程,保障了虚机迁容器过程的稳定性。目前,Triton 除了提供日常的应用容器发布、网络策略配置、Ingress 域名配置等能力之外,也成为其他组件、平台的资源交付基座,比如,大规模的流水线交付,压测平台等。Triton 解决了应用生命周期管理的问题,包括开发、部署、运维等,同时打通了微服务治理,极大地帮助研发提升了持续交付的效率。
// DeployFlow is the Schema for the deploys API type DeployFlow struct { metav1.TypeMeta `json:",inline"` metav1.ObjectMeta `json:"metadata,omitempty"`
Spec DeployFlowSpec `json:"spec,omitempty"` Status DeployFlowStatus `json:"status,omitempty"` }
BatchPending: 表示当前批次的 pod 正在准备资源,比如此时 pod 正在被调度中,image 在下载中,对应 Kubernetes 中的 pod 处于 Pending,ContainerCreating 状态。
BatchSmoking: 表示当前批次的 pod 正在启动过程中,pod 处于 Running 状态,但是 ContainerReady 字段还没有置为 true。
BatchSmoked: 表示当前批次的所有 pod 都已经启动成功,也就是 pod 中的 ContainerReady 字段已经被置为 true,但是 Ready 字段还处于 false。此时如果通过 service 来处理服务流量的话,启动的 pod 并不会被加入到对应 service 的 endpoint,如果是微服务架构,则该 pod 并不会被拉入到微服务的注册中心,从而保证了业务流量的安全。正是拥有了这种机制以及批次间可暂停的能力,我们可以轻松实现应用的金丝雀发布,这个在后面还会详细讲到。
BatchBaking: 表示当前批次的所有 pod 都已经启动成功,正在执行流量拉入操作,也就是将 pod 的 Ready 字段置为 true。
BatchBaked: 表示当前批次的所有 pod 的 Ready 字段都已被置为 true,pod 开始接收生产流量,至此也意味着本批次的结束,可以开始下一批次的操作。
底层架构以及核心组件 DeployFlow 的设计逻辑虽然稍显复杂,但得益于 Triton 暴露的 REST & GRPC API 以及丰富的 status 字段,使得前端在发布的 UI 交互逻辑上能够做到简洁直观。下面让我们从 UI 入手,看下 Triton 如何进行应用的交付以及对应用的副本实例的规划。
2.3.1 发布入口及发布清单
进入生产发布页面,在容器发布页签,选择需要发布的 group,点击“发布”。
点击后弹出一个发布清单的页面,在这里需要配置本次发布需要的策略以及相关参数。
其中有些参数在上面的 CRD 设计篇章中已经有所描述,比如应用描述,批次大小,批次间处理方式,批次间隔等,这里不再赘述。启动超时时间 是开放给开发者自定义应用需要用来启动的时间,比如有些应用尤其是 java 应用,在真正启动之前需要执行一些 warm up 的操作,开发者就可以根据自己应用的实际情况填写该值,避免这类应用启动失败。微服务拉出等待时间 是用来支持微服务 pod 优雅退出的。
那何谓优雅退出,为什么要优雅退出呢?在 Kubernetes 中当删掉一个 pod 的时候,理想状况当然是 Kubernetes 从对应的 Service(假如有的话)把这个 pod 摘掉,同时给 pod 发 SIGTERM 信号让 pod 中的各个容器优雅退出就行了。但实际上 pod 有可能犯各种幺蛾子:
已经卡死了,处理不了优雅退出的代码逻辑或需要很久才能处理完成;
优雅退出的逻辑有 BUG,自己死循环了;
代码写得野,根本不理会 SIGTERM;
因此,Kubernetes 的 pod 终止流程中还有一个”最多可以容忍的时间”,即 grace period (在 pod 的 .spec.terminationGracePeriodSeconds 字段中定义),这个值默认是 30 秒,我们在执行 kubectl delete 的时候也可通过 --grace-period 参数显式指定一个优雅退出时间来覆盖 pod 中的配置。而当 grace period 超出之后,Kubernetes 就只能选择 SIGKILL 强制干掉 pod 了。
但是在微服务的场景下,除了把 pod 从 Kubernetes 的 Service 上摘下来以及进程内部的优雅退出之外,我们还必须做一些额外的事情,比如说从 Kubernetes 外部的服务注册中心上反注册,不然可能会出现 pod 已经被删掉,但是注册中心上还留着已删掉 pod 的服务信息,此时有流量进入的话就会出现服务不可用的情况。所以我们在 prestop hook 中定义了一个名为 gracefully_shutdown 的文件来处理 pod 删除后的微服务优雅退出。
至此,一次完整的 DeployFlow 流程就走完了,发布到达成功的状态。可以看到每个批次所负责的 pod 数量以及 pod 状态、日志等信息。
2.3.4 指定实例的操作
在实例运行过程中,如果发现实例负载异常或需要重新加载 apollo 配置,就会有重启实例的需求。Kubernetes 本身没有提供重启的操作逻辑,一般通过杀掉一个 pod 来达到重启的效果,但这种方式比较粗暴而且存在安全隐患。Triton 提供了安全的重启策略,会先新增一个 pod 如果该 pod 启动成功成功,再删掉你所指定要重启的 pod,以此来达到安全重启的效果,这就是 Triton 的指定实例重启的功能。
这个特性并不会出现在即将发布的 Go1.17 中,但是计划在未来的某个 Go 版本中正式 release 这个特性。官方希望这个特性能够帮助 Go 开发人员开始编写 fuzzing 测试,并提供关于 fuzzing 的设计的反馈,为未来该功能的代码正式合并 master 做准备。
Happy fuzzing!
]]>
Golang Fuzzing is beta ready
Go 1.16 is released, Apple silicon M1 可以放心买啦https://cloudsjhan.github.io/2021/02/20/Go-1-16-is-released-Apple-silicon-M1-可以放心买啦/2021-02-20T07:32:51.000Z2021-02-20T07:35:16.002Z
//go:embed hello.txt var b []byte print(string(b))
将一个或多个文件嵌入到文件系统中
1 2 3 4 5 6
import"embed"
//go:embed hello.txt var f embed.FS data, _ := f.ReadFile("hello.txt") print(string(data))
这种将静态文件在编译时嵌入可执行文件的方式,在极大地提高了 go 访问静态文件的灵活性的同时,也能提高了敏感配置文件的安全性。更大胆一点,是不是在前端领域,golang 也能插一脚了?
增加对 Apple silicon ARM 64 架构的支持
Go 1.16 还添加了macOS ARM64 支持(也称为Apple silicon)。 自 Apple 宣布其新的 ARM64 架构以来,go team 一直在与他们紧密合作以确保 Go 得到完全的支持。一直在 观望 M1 的开发者这下可以放心去买新的 Mac 啦。
默认开启 Go modules
Go 1.16 默认使用 Go modules。因为根据 go team 的 2020 Go 开发人员调查,现在有96%的 Go 开发人员已经在使用 Go modules了。
其他的性能改善与提高
最后,还有许多其他改进和 bug fix,比如构建速度提高了25%,内存使用量减少了15%。 有关更改的完整列表以及有关上述改进的更多信息,可以参考 Go 1.16发行说明)。
以上就是 Go 1.16 带来的新特性,有开发者调侃到 “最大的特性就是离泛型的版本号更近了(狗头)”哈哈哈。
]]>
Go 1.16 is released, Apple silicon M1 可以放心买啦'
Redirecting godoc.org requests to pkg.go.devhttps://cloudsjhan.github.io/2020/12/16/Redirecting-godoc-org-requests-to-pkg-go-dev/2020-12-16T06:54:42.000Z2020-12-16T07:30:18.000Z
现状
随着 Go Module 的引入和 Go 生态系统的发展,pkg.go.dev 于 2019 年启动,为开发人员提供了了一个查找 Go package 的地方,官方称之为 center place。 像 godoc.org 一样,pkg.go.dev 提供 Go 文档,但它也支持 Go Module、更好的搜索功能以及帮助 Go 用户找到正确软件包的指引。
]]>
Redirecting godoc.org requests to pkg.go.dev
Can I convert a []T to an []interface{}?https://cloudsjhan.github.io/2020/12/09/Can-I-convert-a-T-to-an-interface/2020-12-09T12:33:50.000Z2020-12-09T12:35:21.000Z
]]>
Can I convert a []T to an []interface{}?
kubectl delete pod 等待 30s 的问题排查与解决https://cloudsjhan.github.io/2020/11/23/kubectl-delete-pod-等待-30s-的问题排查与解决/2020-11-23T05:56:03.000Z2020-11-23T07:50:19.908Z
我们平时在使用 Kubernetes 的时候,一般会使用 kubectl delete pod podName 的方式删除一个容器。 但我们发现,每次执行 kubectl delete pod 之后都要等待 30s kubectl 才会返回。也许你会觉得 30s 是一个可以忍受的时间, 只要最终能删掉 pod 就行,但这样的问题真的只有 30s 这么简单吗? 为什么不能很快关闭容器呢? 或者为什么恰好就是 30s 呢?下面就让我们从根源弄清楚这件事情并解决它。
]]>
kubectl delete pod 等待 30s 的问题排查与解决
Why is there no Goroutine ID?https://cloudsjhan.github.io/2020/11/09/Why-is-there-no-goroutine-ID/2020-11-09T03:32:25.000Z2020-11-09T03:35:41.000Z
Goroutines do not have names; they are just anonymous workers. They expose no unique identifier, name, or data structure to the programmer. Some people are surprised by this, expecting the go statement to return some item that can be used to access and control the Goroutine later.
The fundamental reason Goroutines are anonymous is so that the full Go language is available when programming concurrent code. By contrast, the usage patterns that develop when threads and Goroutines are named can restrict what a library using them can do.
Here is an illustration of the difficulties. Once one names a Goroutine and constructs a model around it, it becomes special, and one is tempted to associate all computation with that Goroutine, ignoring the possibility of using multiple, possibly shared Goroutines for the processing. If the net/http package associated per-request state with a Goroutine, clients would be unable to use more Goroutines when serving a request.
Moreover, experience with libraries such as those for graphics systems that require all processing to occur on the “main thread” has shown how awkward and limiting the approach can be when deployed in a concurrent language. The very existence of a special thread or Goroutine forces the programmer to distort the program to avoid crashes and other problems caused by inadvertently operating on the wrong thread.
For those cases where a particular Goroutine is truly special, the language provides features such as channels that can be used in flexible ways to interact with it.
]]>
Why is there no Goroutine ID?
Go team 关于如何保持 Go Modules 兼容性的一些实践https://cloudsjhan.github.io/2020/08/13/Go-team-关于如何保持-Go-Modules-兼容性的一些实践/2020-08-13T06:05:13.000Z2020-08-13T06:07:27.552Z
近日,Go team 在其官方 blog 上讨论了如何让你的 Go Modules 保持兼容性的话题,并给出了一些建议,这些建议都是该团队在实际开发中不断踩坑总结出来的精华,可以说是最佳实践。我们站在巨人的肩膀上,可以写出更优雅,更具有兼容性的代码,下面让我们深入逐条解读这些建议。
随着新功能的添加,或者重构 Go Module 的某些公共部分,Go Module 将随着时间的推移而不断发生变化。
但是,发布新的 Go Module 版本对使用者来是一个噩耗。 他们必须找到新版本,学习新的API,并更改其代码。 而且某些用户可能永远不会更新,这意味着您必须永远为代码维护两个版本。 因此,通常最好以兼容的方式更改现有的 Go Module。
在本文中,我们将探讨一些代码技巧,能够让你保持 Go Module 的兼容性。 核心的思想就是是:添加,但是不要更改或删除你的 Go Module 代码。 我们还将从宏观角度讨论如何设计具备高度兼容性的 API 。
增加了 control function,允许调用者在网络连接还没有 bind 的时候调整原始连接的参数。
这看起来是相当大的调整了,如果是一般开发者,最多也就会新增一个函数,参数中添加 context, control function。但是 Go team 的开发者非等闲之辈,net package 的作者想到未来的某一天这个函数是不是会有调整,或者需要更多的参数?于是就预留了一个 ListenConfig 的结构体,为这个 strcut 实现了 Listen 方法,从而也不用再新增一个函数才能解决问题。
1 2 3 4 5
type ListenConfig struct { Control func(network, address string, c syscall.RawConn)error } func(*ListenConfig)Listen(ctx context.Context, network, address string)(Listener, error)
// A private method to prevent users implementing the // interface and so future additions to it will not // violate Go 1 compatibility. // private 避免用户去实现它 private() }
新增配置方法
到目前为止,我们讨论了修改函数签名或者为 interface 添加方法,会影响到用户的代码导致编译失败。实际上,函数行为的改变会造成同样的问题。例如,很多开发者希望 json.Decoder 可以忽略 struct 中没有的 json 字段。但是当 Go team 想要在这种情况下返回一些错误的时候,就必须要小心,因为这样做会导致很多使用该方法的用户突然收到以前从未遇到的错误。
从头开始规划 API 的时候,请仔细考虑 API 在将来的可扩展性。 而且当你确实需要添加新功能时,请记住以下规则:添加,不要更改或删除。请牢记,添加接口方法,函数参数和返回值都会导致 Go Module 不能向后兼容。
如果你确实需要大规模更改 API,或者要添加更多新特性,那么使用新的 API 版本会是更好的方式。 但是大多数时候,进行向后兼容的更改应该是你的首选,能够避免给用户带来麻烦。
]]>
Go team 关于如何保持 Go Modules 兼容性的一些实践
lxcfs 实现容器资源视图隔离的最佳实践https://cloudsjhan.github.io/2020/07/04/lxcfs-实现容器资源视图隔离的最佳时间/2020-07-04T12:49:46.000Z2020-07-04T12:55:06.656Z
LXCFS is a small FUSE filesystem written with the intention of making Linux containers feel more like a virtual machine. It started as a side-project of LXC but is useable by any runtime.
对于需要获取 host cpu info 的程序,比如在开发 golang 服务端需要获取 golang中 runtime.GOMAXPROCS(runtime.NumCPU()) 或者运维在设置服务启动进程数量的时候( 比如 nginx 配置中的 worker_processes auto ),都喜欢通过程序自动判断所在运行环境CPU的数量。但是在容器内的进程总会从/proc/cpuinfo中获取到 CPU 的核数,而容器里面的/proc文件系统还是物理机的,从而会影响到运行在容器里面服务的运行状态。
]]>
lxcfs 实现容器资源隔离的最佳实践
重磅!微软 VS Code 的 Go 语言插件迁移至由 Go 官方团队维护https://cloudsjhan.github.io/2020/06/12/重磅!微软-VS-Code-的-Go-语言插件迁移至由-Go-官方团队维护/2020-06-12T11:49:44.000Z2020-06-12T11:51:42.038Z
Go 官方 6月 9日电:VS Code 的 Go plugin 已经转为 Go 官方团队维护的项目。其中有两个重要的标志性事件:
在 VS Code 插件市场中的发布者也由 Microsoft 变更为 Go Team at Google 。
自去年 Go modules 发布以来,VS Code 团队就和 Go 团队开始了紧密的合作,让插件得以支持 Go 的官方语言服务器 gopls,目前还正在改进对 Delve 调试器的支持。
从另一方面来看,迁移至由 Go 团队维护意味着此插件成为了 Go 项目的一部分,可确保 Go 社区成员能参与到项目的每一步。插件目前依赖于许多不同的工具和库,而这些工具和库均由社区维护,VS Code 团队希望与这些项目的所有者合作,以帮助减少 Go 社区的维护工作负担,并鼓励更多 Gophers 参与进来共同维护。
]]>
重磅!微软 VS Code 的 Go 语言插件迁移至由 Go 官方团队维护
Uber Go 语言编码规范https://cloudsjhan.github.io/2020/06/09/Uber-Go-语言编码规范/2020-06-09T02:36:29.000Z2020-06-09T02:37:57.862Z
type LogHandler struct { h http.Handler log *zap.Logger } var _ http.Handler = LogHandler{} func(h LogHandler)ServeHTTP( w http.ResponseWriter, r *http.Request, ) { // ... }
Our suggested way of implementing this pattern is with an Option interface that holds an unexported method, recording options on an unexported options struct.
Golang有很多优点,这也是它如此流行的主要原因。但是 Go 1 对错误处理的支持过于简单了,以至于日常开发中会有诸多不便利,遭到很多开发者的吐槽。 这些不足催生了一些开源解决方案。与此同时, Go 官方也在从语言和标准库层面作出改进。 这篇文章将给出几种常见创建错误的方式并分析一些常见问题,对比各种解决方案,并展示了迄今为止(go 1.13)的最佳实践。
几种创建错误的方式
首先介绍几种常见的创建错误的方法
基于字符串的错误
1 2 3 4
err1 := errors.New("math: square root of negative number")
err2 := fmt.Errorf("math: square root of negative number %g", x)
funcmain() { err := Call() if err == sql.ErrNoRows { fmt.Printf("data not found, %+v\n", err) return } if err != nil { // Unknown error } } //Outputs: // data not found, sql: no rows in result set
funcmain() { err := Call() if errors.Cause(err) == sql.ErrNoRows { fmt.Printf("data not found, %v\n", err) fmt.Printf("%+v\n", err) return } if err != nil { // unknown error } } /*Output: data not found, Call failed: GetSql failed: sql: no rows in result set sql: no rows in result set main.GetSql /usr/three/main.go:11 main.Call /usr/three/main.go:15 main.main /usr/three/main.go:19 runtime.main ... */
funcmain() { err := Call() if xerrors.Is(err, sql.ErrNoRows) { fmt.Printf("data not found, %v\n", err) fmt.Printf("%+v\n", err) return } if err != nil { // unknown error } } /* Outputs: data not found, Call failed: GetSql failed: sql: no rows in result set bar failed: main.Call /usr/four/main.go:12 - GetSql failed: main.GetSql /usr/four/main.go:18 - sql: no rows in result set */
funcmain() { err := Call() if errors.Is(err, sql.ErrNoRows) { fmt.Printf("data not found, %+v\n", err) return } if err != nil { // unknown error } } /* Outputs: data not found, Call failed: GetSql failed: sql: no rows in result set */
这次的受访者的受众特征与 Stack Overflow 的调查受访者相似,使得这些结果可以代表更多的 Go 开发人员的心声。
大多数受访者每天都使用 Go,而且这个数字每年都在上升。
Go 的使用仍集中在技术公司,但是 Go 在越来越多的行业中被用到,例如金融行业和媒体相关。
开发者使用 Go 解决的问题很相似,基本集中在构建 API, RPC 服务和 CLI 工具。
大多数团队都试图尽快更新到最新的 Go 版本。 但是第三方 package 的 provider 更新地会相对慢一点。
现在,Go生态系统中的几乎每个人都在使用 Go Modules,但是用户对软件包管理方面仍然存在困惑。
有待改进的重点领域包括改善开发人员的 debug 体验,Go Modules 和 cloud service 方面的体验。
VS Code 和 GoLand 仍然是最受欢迎的编辑器,受访的四个人中就有三个在使用他们。
受访的开发者群体
受访者公司规模
受访者的编程工作年限
受访者使用 Go 编程的时间
从使用 Go 的经验来看,我们发现大多数受访者(56%)使用 Go 的时间不到两年,相对较新。 多数人还说,他们在工作中(72%)和工作外(62%)使用Go。 可以看到在工作中使用 Go 的受访者比例每年都在上升。
受访者的开发背景
使用 Go 时间较长的受访者与新的 Go 开发人员的背景不同。 这些 Go 老兵更有可能拥有 C / C ++ 的专业知识,而不太可能具备 JavaScript,TypeScript 和 PHP 的专业知识。 但是不管他们使用 Go 已有多长时间,Python似乎都是大多数受访者熟悉的语言(不是Go🤔)。
Go 是一个成功的开源项目,但这并不意味着使用它的开发人员也正在编写免费或开源软件。 与往年一样,我们发现大多数受访者并不是 Go 开源项目的频繁贡献者,有 75% 的受访者表示他们“很少”或“从不”参与 Go 开源项目。 随着Go社区的扩展,我们发现从未为 Go 开源项目做出过贡献的受访者所占的比例正在缓慢上升。
开发工具篇
受访者开发中使用的 OS
与往年一样,绝大多数开发者表示在 Linux 和 macOS 系统上使用 Go。 这是我们的受访者与StackOverflow的2019 年调查结果之间存在很大差异的一个方面:在我们的调查中,只有20%的受访者使用 Windows 作为主要开发平台,而对于 StackOverflow 而言,这一比例为 45%。 Linux 的使用率为 66%,macOS 的使用率为 53%,这两者都远远高于 StackOverflow 的受众,后者分别报告了 25% 和 30%(看来 Gopher 还是喜欢 UNIX 多一些)。
受访者使用的 IDE
今年,IDE 整合的趋势仍在继续。 GoLand 今年的使用量增长最快,从 24% → 34% 上升。 VS Code的增长速度有所放缓,但仍然是受访者中最受欢迎的编辑器,占41%。 结合起来,这两个 IDE 现在的占有率是 75%。
关于自建 Go document server
今年,我们添加了一个有关内部 Go 文档工具(例如 gddo )的问题。 少数受访者( 6% )表示他们的组织运行自己的Go文档服务器,尽管当我们查看大公司受访者(拥有至少5,000名员工)时,这一比例几乎翻了一番(达到11%),但当我们与后者交流时,他们说基本已经停止了自建 document server,原因是收益小,成本高。
受访者对 Go 的使用意向
大部分受访者都认为 Go 在他们的团队中表现良好(86%),并且他们希望将其用于下一个项目(89%)。 我们还发现,超过一半的受访者(59%)认为 Go 对其公司的成功至关重要。 自2016年以来,这些指标一直保持稳定。
受访者对 Go 生态的满意度
在 Go 生态的满意度上,我们看到很大比例的受访者同意每种说法(82%–88%),并且在过去四年中,这些比率在很大程度上保持稳定。
总体而言,大多数受访者对在所有三大主要云提供商上使用 Go 感到满意。 受访者具有对 Go(AWS)(80%满意)和GCP(78%)的 满意度。
Go project 的部署服务类型
存在的痛点
受访者表示无法使用Go的主要原因有三个:
(56%)当前的项目正在使用其他语言;
团队更倾向于使用其他语言(37%);
Go本身缺乏一些关键功能 (25%)。
对一些 Go 特性的期待
在 25% 的受访者中,认为 Go 缺乏他们需要的语言特性。其中 79% 认为泛型是一个严重缺失的特性。22% 的人提到了对错误处理的持续改进(除了 Go 1.13 的更改之外),13 %的人要求更多的函数式编程特性,尤其是内置的map/filter/reduce 功能。需要说明的是,这些数字来自受访者的子集,他们表示,如果提供了他们需要的一个或多个关键功能,他们将能够更多地使用 Go。
没有使用 Go 作为项目的语言的一些原因
对于他们所从事的工作来说,Go “不是一种合适的语言”的受访者有各种各样的理由和用例。最常见的是他们从事某种形式的前端开发(22%),例如用于 web、桌面或移动设备的g ui。另一个常见的回答是,受访者说他们工作的领域中已经有占主导地位的语言(9%),因此很难使用不同的语言。一些受访者还告诉我们他们指的是哪个领域(或者只是提到了一个领域,而没有提到另一种更常见的语言),我们通过下面的“I work on [domain]”行来说明这一点。受访者提到的另一个主要原因是需要更好的性能(9%),尤其是实时计算。
受访者认为目前存在的最大的阻碍
受访者报告的最大阻碍与去年基本保持一致。 Go 缺乏泛型和模块,包管理工具仍然是最主要的问题(分别占反馈的15%和12%),并且强调工具问题的受访者比例有所增加。 这些数字与上面的图表不同,因为这个问题是所有受访者都提出的,无论他们说最大的阻碍什么。 这三个问题都是今年 Go 团队关注的领域,我们希望在未来几个月内极大地改善开发人员的体验,尤其是在模块,工具和入门经验方面。
Debug Go project 的痛点
任何一种语言的 debug 和 benchmark 都具有挑战性。 受访者告诉我们,这两个方面的最大挑战不是 Go 的工具所特有的,而是一个更根本的问题:缺乏知识,经验或最佳实践。 我们希望在今年晚些时候通过文档和其他材料来帮助解决这些问题。 其他主要问题涉及到工具的使用,尤其是在学习/使用 Go 的调试和 profile 分析工具时,在成本/收益方面存在不利的权衡,以及使工具在各种环境中工作的挑战(例如,在容器中进行调试或从生产环境中获取性能分析)。
Go community
大约三分之二的受访者使用 Stack Overflow 来回答与 go 相关的问题(64%)。其他排名靠前的答案来源是godoc.org(47%),直接阅读源代码(42%)和 golang.org (33%)。
关于 MeetUp
上表突展示了不同的寻求帮助的方式(几乎都是社区驱动的),受访者在使用Go开发过程中依靠它们来克服挑战。事实上,对于许多 gopher 来说,这可能是他们与更大的社区互动的主要要点之一: 随着我们的社区不断扩大,我们看到越来越多的受访者不用参加任何与 go 相关的活动。在2019年,这一比例接近三分之二的受访者(62%)。
受访者的语言
由于谷歌更新了全谷歌范围内的隐私指南,我们无法再询问受访者生活在哪个国家。相反,我们询问了首选的口语/书面语作为 Go 在全球使用的粗略调查,这有助于为潜在的本地化工作提供数据。
我们希望你了解这次 2019 年开发者调查的结果。了解开发人员的经验和挑战有助于我们为 2020 年制定计划并确定工作的优先级。再一次,非常感谢所有参与调查的人,你们的反馈将有助于在未来一年甚至更长的时间内引导 Go 前进的方向。
]]>
官宣:2019 年 Go 开发者调查报告
手把手教你实现高性能 kubernetes web terminalhttps://cloudsjhan.github.io/2020/04/24/手把手教你实现高性能-kubernetes-web-terminal/2020-04-24T10:03:44.000Z2020-04-24T10:03:44.116Z
type InsInfo struct { Connections string `gorm:"column:connections"` CPU int `gorm:"column:cpu"` CreateTime time.Time `gorm:"column:create_time"` Env int `gorm:"column:env"` ID int64 `gorm:"column:id;primary_key"` IP string `gorm:"column:ip"` Organization string `gorm:"column:organization"` Pass string `gorm:"column:pass"` Port string `gorm:"column:port"` RegionId string `gorm:"column:regionid"` ServerIP string `gorm:"column:server_ip"` Status int `gorm:"column:status"` Type string `gorm:"column:type"` UUID string `gorm:"column:uuid"` }
如果你的数据库在本地,那么只需要执行 docker-compose up -d, 访问localhost:8000,你就会得到下面的界面:
服务器上的数据库
如果你的数据库在内网服务器上,你需要先修改后端接口的ip:port,然后重新build Docker镜像,push到自己的镜像仓库,然后修改docker-compose.yaml,再执行docker-compose up -d。修改的位置是:fuckdb/frontend/src/config/index.js.
fuckdb --help From mysql schema generate golang struct with gorm, json tag
Usage: fuckdb [command]
Available Commands: generate use `fuckdb generate` to generate fuckdb.json go fuckdb go to generate golang struct with gorm and json tag help Help about any command
Flags: -h, --help help for fuckdb
Use "fuckdb [command] --help" for more information about a command.
]]>
fuckdb Lite, 帮助你更快地生成go struct代码
Proposals for Go 1.15(译)https://cloudsjhan.github.io/2020/02/01/Proposals-for-Go-1-15-译/2020-02-01T02:48:54.000Z2020-04-01T09:03:03.550Z
当前,Go允许任何类型断言x.(T)(以及相应的类型切换情况),其中x和T为接口类型。但是,如果x和T有相同名字的方法,但是签名不同,则分配给x的任何值也不能实现T(这种类型的断言在运行时总是失败,panic或evaluate to false)。因为我们在编译时就知道这一点,所以编译器会报告错。在这种情况下,编译报错不是向后兼容的,因此我们也将在go vet中添加对该情况的检查。
]]>
本文是Golang官方对于Go近期版本的现状总结以及Go 1.15版本的一些提案,原文发布于 The Go Blog
Go GC 20问https://cloudsjhan.github.io/2020/01/06/Go-GC-20问/2020-01-06T06:05:44.000Z2020-01-06T13:18:19.500Z
gofunc() { var t time.Time for atomic.LoadInt32(&stop) == 0 { t = time.Now() runtime.GC() sum += time.Since(t) count++ } fmt.Printf("GC spend avg: %v\n", time.Duration(int64(sum)/count)) }()
concat() atomic.StoreInt32(&stop, 1) }
这个程序的执行结果是:
1 2 3
$ go build -o main $ ./main GC spend avg: 2.583421ms
funcconcat() { wg := sync.WaitGroup{} for n := 0; n < 100; n++ { wg.Add(8) for i := 0; i < 8; i++ { gofunc() { s := "Go GC" s += " " + "Hello" s += " " + "World" _ = s wg.Done() }() } wg.Wait() } }
这时候我们再来看:
1 2 3
$ go build -o main $ ./main GC spend avg: 328.54µs
GC 的平均时间就降到 300 微秒了。这时的赋值器 CPU 使用率也提高到了 60%,相对来说就很可观了:
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2 This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Concurrency Level: 100 Time taken for tests: 0.987 seconds Complete requests: 500 Failed requests: 0 Total transferred: 65500 bytes HTML transferred: 7000 bytes Requests per second: 506.63 [#/sec] (mean) Time per request: 197.382 [ms] (mean) Time per request: 1.974 [ms] (mean, across all concurrent requests) Transfer rate: 64.81 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 1 1.1 0 7 Processing: 13 179 77.5 170 456 Waiting: 10 168 78.8 162 455 Total: 14 180 77.3 171 458
Percentage of the requests served within a certain time (ms) 50% 171 66% 203 75% 222 80% 239 90% 281 95% 335 98% 365 99% 400 100% 458 (longest request)
GC 反复被触发,一个显而易见的原因就是内存分配过多。我们可以通过 go tool pprof 来查看究竟是谁分配了大量内存(使用 web 指令来使用浏览器打开统计信息的可视化图形):
1 2 3 4 5 6 7 8 9
$ go tool pprof http://127.0.0.1:6060/debug/pprof/heap Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap Saved profile in /Users/changkun/pprof/pprof.alloc_objects.alloc_space.inuse_o bjects.inuse_space.003.pb.gz Type: inuse_space Time: Jan 1, 2020 at 11:15pm (CET) Entering interactive mode (type"help"for commands, "o"for options) (pprof) web (pprof)
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2 This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Concurrency Level: 100 Time taken for tests: 0.427 seconds Complete requests: 500 Failed requests: 0 Total transferred: 65500 bytes HTML transferred: 7000 bytes Requests per second: 1171.32 [#/sec] (mean) Time per request: 85.374 [ms] (mean) Time per request: 0.854 [ms] (mean, across all concurrent requests) Transfer rate: 149.85 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 1 1.4 1 9 Processing: 5 75 48.2 66 211 Waiting: 5 72 46.8 63 207 Total: 5 77 48.2 67 211
Percentage of the requests served within a certain time (ms) 50% 67 66% 89 75% 107 80% 122 90% 148 95% 167 98% 196 99% 204 100% 211 (longest request)
但从 Requests per second 每秒请求数来看,从原来的 506.63 变为 1171.32 得到了近乎一倍的提升。从 trace 的结果来看,GC 也没有频繁的被触发从而长期消耗 CPU 使用率:
funcconcat() { wg := sync.WaitGroup{} for n := 0; n < 100; n++ { wg.Add(8) for i := 0; i < 8; i++ { gofunc() { s := make([]byte, 0, 20) s = append(s, "Go GC"...) s = append(s, ' ') s = append(s, "Hello"...) s = append(s, ' ') s = append(s, "World"...) _ = string(s) wg.Done() }() } wg.Wait() } }
$ ab -n 500 -c 100 http://127.0.0.1:8080/example2 This is ApacheBench, Version 2.3 <$Revision: 1843412 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/ Licensed to The Apache Software Foundation, http://www.apache.org/
Concurrency Level: 100 Time taken for tests: 0.923 seconds Complete requests: 500 Failed requests: 0 Total transferred: 65500 bytes HTML transferred: 7000 bytes Requests per second: 541.61 [#/sec] (mean) Time per request: 184.636 [ms] (mean) Time per request: 1.846 [ms] (mean, across all concurrent requests) Transfer rate: 69.29 [Kbytes/sec] received
Connection Times (ms) min mean[+/-sd] median max Connect: 0 1 1.8 0 20 Processing: 9 171 210.4 66 859 Waiting: 5 158 199.6 62 813 Total: 9 173 210.6 68 860
Percentage of the requests served within a certain time (ms) 50% 68 66% 133 75% 198 80% 292 90% 566 95% 696 98% 723 99% 743 100% 860 (longest request)
可以看到,压测的结果得到了一定幅度的改善(Requests per second 从原来的 506.63 提高为了 541.61), 并且 GC 的执行频率明显降低:
新生代中的对象主要通过副垃圾回收器进行回收。该回收过程是一种采用复制的方式实现的垃圾回收算法,它将堆内存一分为二,这两个空间中只有一个处于使用中,另一个则处于闲置状态。处于使用状态的空间称为 From 空间,处于闲置的空间称为 To 空间。分配对象时,先是在 From 空间中进行分配,当开始垃圾回收时,会检查 From 空间中的存活对象,并将这些存活对象复制到 To 空间中,而非存活对象占用的空间被释放。完成复制后,From 空间和 To 空间的角色互换。也就是通过将存活对象在两个空间中进行复制。
end := time.Now() elapsed := end.Sub(start) if elapsed > worst { worst = elapsed worstAt = end } if elapsed < best { best = elapsed bestAt = end } }
funcnewMsg(n int) []byte { m := make([]byte, 1024) for i := range m { m[i] = byte(n) } return m }
运行此程序我们可以得到类似下面的结果:
1 2 3 4 5 6 7
$ go run main.go
Best send delay 330ns at 773.037956ms, worst send delay: 7.127915ms at 579.835487ms. Wall clock: 831.066632ms Best send delay 331ns at 873.672966ms, worst send delay: 6.731947ms at 1.023969626s. Wall clock: 1.515295559s Best send delay 330ns at 1.812141567s, worst send delay: 5.34028ms at 2.193858359s. Wall clock: 2.199921749s Best send delay 338ns at 2.722161771s, worst send delay: 7.479482ms at 2.665355216s. Wall clock: 2.920174197s Best send delay 337ns at 3.173649445s, worst send delay: 6.989577ms at 3.361716121s. Wall clock: 3.615079348s
]]>
Go GC 20问
golang自动生成对应MySQL数据库表的struct定义https://cloudsjhan.github.io/2020/01/01/golang自动生成对应MySQL数据库表的struct定义/2020-01-01T14:37:14.000Z2020-01-01T15:16:15.693Z
type InsInfo struct { Connections string`gorm:"column:connections"` CPU int`gorm:"column:cpu"` CreateTime time.Time `gorm:"column:create_time"` Env int`gorm:"column:env"` ID int64`gorm:"column:id;primary_key"` IP string`gorm:"column:ip"` Organization string`gorm:"column:organization"` Pass string`gorm:"column:pass"` Port string`gorm:"column:port"` RegionId string`gorm:"column:regionid"` ServerIP string`gorm:"column:server_ip"` Status int`gorm:"column:status"` Type string`gorm:"column:type"` UUID string`gorm:"column:uuid"` }
如果你的数据库在本地,那么只需要执行 docker-compose up -d,访问localhost:8088,你就会得到下面的界面:
如果你的数据库在内网服务器上,你需要先修改后端接口的ip:port,然后重新build Docker镜像,push到自己的镜像仓库,然后修改docker-compose.yaml,再执行docker-compose up -d。修改的位置是:fuckdb/frontend/src/config/index.js.
// AutomaticEnv has Viper check ENV variables for all. // keys setin config, default & flags AutomaticEnv()
// BindEnv binds a Viper key to a ENV variable. // ENV variables are case sensitive. // If only a key is provided, it will use the env key matching the key, uppercased. // EnvPrefix will be used when set when env name is not provided. BindEnv(string…) : error
// SetEnvPrefix defines a prefix that ENVIRONMENT variables will use. // E.g. if your prefix is "spf", the env registry will look for env // variables that start with "SPF_". SetEnvPrefix(string)
func main() { v := viper.New() v.AddRemoteProvider("consul", "localhost:8500", "config") v.SetConfigType("json") // Need to explicitly set this to json if err := v.ReadRemoteConfig(); err != nil { log.Println(err) return }
// @title Swagger Example API // @version 1.0 // ...
复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14
➜ swaggo-gin git:(master) ✗ go build ➜ swaggo-gin git:(master) ✗ ./swaggo-gin [GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production. - using env: export GIN_MODE=release - using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET /api/v1/hello --> main.HandleHello (3 handlers) [GIN-debug] POST /api/v1/login --> main.HandleLogin (3 handlers) [GIN-debug] POST /upload --> main.HandleUpload (4 handlers) [GIN-debug] GET /list --> main.HandleList (4 handlers) [GIN-debug] GET /swagger/*any --> github.com/swaggo/gin-swagger.WrapHandler.func1 (4 handlers) [GIN-debug] Listening and serving HTTP on :8080
`// Cron keeps track of any number of entries, invoking the associated func as``// specified by the schedule. It may be started, stopped, and the entries may``// be inspected while running. ``// Cron保持任意数量的条目的轨道,调用相关的func时间表指定。它可以被启动,停止和条目,可运行的同时进行检查。``type Cron struct {`` ``entries []*Entry // 任务`` ``stop chan struct{} // 叫停止的途径`` ``add chan *Entry // 添加新任务的方式`` ``snapshot chan []*Entry // 请求获取任务快照的方式`` ``running bool // 是否在运行`` ``ErrorLog *log.Logger // 出错日志(新增属性)`` ``location *time.Location // 所在地区(新增属性) ``}`
`// Entry consists of a schedule and the func to execute on that schedule.``// 入口包括时间表和可在时间表上执行的func``type Entry struct {`` ``// 计时器`` ``Schedule Schedule`` ``// 下次执行时间`` ``Next time.Time`` ``// 上次执行时间`` ``Prev time.Time`` ``// 任务`` ``Job Job``}`
`// 开始任务``// Start the cron scheduler in its own go-routine, or no-op if already started.``func (c *Cron) Start() {`` ``if c.running {`` ``return`` ``}`` ``c.running = true`` ``go c.run()``}``// 结束任务``// Stop stops the cron scheduler if it is running; otherwise it does nothing.``func (c *Cron) Stop() {`` ``if !c.running {`` ``return`` ``}`` ``c.stop <- struct{}{}`` ``c.running = false``}` `// 执行定时任务``// Run the scheduler.. this is private just due to the need to synchronize``// access to the 'running' state variable.``func (c *Cron) run() {`` ``// Figure out the next activation times for each entry.`` ``now := time.Now().In(c.location)`` ``for _, entry := range c.entries {`` ``entry.Next = entry.Schedule.Next(now)`` ``}`` ``// 无限循环`` ``for {`` ``//通过对下一个执行时间进行排序,判断那些任务是下一次被执行的,防在队列的前面.sort是用来做排序的`` ``sort.Sort(byTime(c.entries))` ` ``var effective time.Time`` ``if len(c.entries) == 0 || c.entries[0].Next.IsZero() {`` ``// If there are no entries yet, just sleep - it still handles new entries`` ``// and stop requests.`` ``effective = now.AddDate(10, 0, 0)`` ``} else {`` ``effective = c.entries[0].Next`` ``}` ` ``timer := time.NewTimer(effective.Sub(now))`` ``select {`` ``case now = <-timer.C: // 执行当前任务`` ``now = now.In(c.location)`` ``// Run every entry whose next time was this effective time.`` ``for _, e := range c.entries {`` ``if e.Next != effective {`` ``break`` ``}`` ``go c.runWithRecovery(e.Job)`` ``e.Prev = e.Next`` ``e.Next = e.Schedule.Next(now)`` ``}`` ``continue` ` ``case newEntry := <-c.add: // 添加新的任务`` ``c.entries = append(c.entries, newEntry)`` ``newEntry.Next = newEntry.Schedule.Next(time.Now().In(c.location))` ` ``case <-c.snapshot: // 获取快照`` ``c.snapshot <- c.entrySnapshot()` ` ``case <-c.stop: // 停止任务`` ``timer.Stop()`` ``return`` ``}` ` ``// 'now' should be updated after newEntry and snapshot cases.`` ``now = time.Now().In(c.location)`` ``timer.Stop()`` ``}``}`
`// SpecSchedule specifies a duty cycle (to the second granularity), based on a``// traditional crontab specification. It is computed initially and stored as bit sets.``type SpecSchedule struct {`` ``// 表达式中锁表明的,秒,分,时,日,月,周,每个都是uint64`` ``// Dom:Day of Month,Dow:Day of week`` ``Second, Minute, Hour, Dom, Month, Dow uint64``}` `// bounds provides a range of acceptable values (plus a map of name to value).``// 定义了表达式的结构体``type bounds struct {`` ``min, max uint`` ``names map[string]uint``}` `// The bounds for each field.``// 这样就能看出各个表达式的范围``var (`` ``seconds = bounds{0, 59, nil}`` ``minutes = bounds{0, 59, nil}`` ``hours = bounds{0, 23, nil}`` ``dom = bounds{1, 31, nil}`` ``months = bounds{1, 12, map[string]uint{`` ``"jan": 1,`` ``"feb": 2,`` ``"mar": 3,`` ``"apr": 4,`` ``"may": 5,`` ``"jun": 6,`` ``"jul": 7,`` ``"aug": 8,`` ``"sep": 9,`` ``"oct": 10,`` ``"nov": 11,`` ``"dec": 12,`` ``}}`` ``dow = bounds{0, 6, map[string]uint{`` ``"sun": 0,`` ``"mon": 1,`` ``"tue": 2,`` ``"wed": 3,`` ``"thu": 4,`` ``"fri": 5,`` ``"sat": 6,`` ``}}``)` `const (`` ``// Set the top bit if a star was included in the expression.`` ``starBit = 1 << 63``)`
services: proxy: build: ./proxy networks: - front app: build: ./app networks: - front - back db: image: postgres networks: - back
networks: front: # Use a custom driver driver: custom-driver-1 back: # Use a custom driver which takes special options driver: custom-driver-2 driver_opts: foo: "1" bar: "2"
之后,通过docker-compose up -d命令启动这两个容器,然后执行docker exec -it test2 ping test1,你将会看到如下的输出:
1 2 3 4 5 6 7 8
docker exec -it test2 ping test1 PING test1 (172.18.0.2): 56 data bytes 64 bytes from 172.18.0.2: icmp_seq=0 ttl=64 time=0.091 ms 64 bytes from 172.18.0.2: icmp_seq=1 ttl=64 time=0.146 ms 64 bytes from 172.18.0.2: icmp_seq=2 ttl=64 time=0.150 ms 64 bytes from 172.18.0.2: icmp_seq=3 ttl=64 time=0.145 ms 64 bytes from 172.18.0.2: icmp_seq=4 ttl=64 time=0.126 ms 64 bytes from 172.18.0.2: icmp_seq=5 ttl=64 time=0.147 ms
证明这两个容器是成功链接了,反过来在test1中pingtest2也是能够正常ping通的。
如果我们通过docker run --rm --name test3 -d nginx这种方式来先启动了一个容器(test3)并且没有指定它所属的外部网络,而需要将其与test1或者test2链接的话,这个时候手动链接外部网络即可:
‘’’ in enter Traceback (most recent call last): type: val: integer division or modulo by zero File “/home/user/cltdevelop/Code/TF_Practice_2017_06_06/with_test.py”, line 36, in tb: sample.do_something() File “/home/user/cltdevelop/Code/TF_Practice_2017_06_06/with_test.py”, line 32, in do_something bar = 1 / 0 ZeroDivisionError: integer division or modulo by zero
Process finished with exit code 1
‘’’ 三、异常处理 with 应用 异常处理逻辑太多,以至于扰乱了代码核心逻辑。具体表现就是,代码里充斥着大量的 try、except、raise 语句,让核心逻辑变得难以辨识。
// ReadFrom reads data from r until EOF and appends it to the buffer, growing // the buffer as needed. The return value n is the number of bytes read. Any // error except io.EOF encountered during the read is also returned. If the // buffer becomes too large, ReadFrom will panic with ErrTooLarge. func(b *Buffer)ReadFrom(r io.Reader)(n int64, err error) { b.lastRead = opInvalid // If buffer is empty, reset to recover space. if b.off >= len(b.buf) { b.Truncate(0) } for { if free := cap(b.buf) - len(b.buf); free < MinRead { // not enough space at end newBuf := b.buf if b.off+free < MinRead { // not enough space using beginning of buffer; // double buffer capacity newBuf = makeSlice(2*cap(b.buf) + MinRead) } copy(newBuf, b.buf[b.off:]) b.buf = newBuf[:len(b.buf)-b.off] b.off = 0 } m, e := r.Read(b.buf[len(b.buf):cap(b.buf)]) b.buf = b.buf[0 : len(b.buf)+m] n += int64(m) if e == io.EOF { break } if e != nil { return n, e } } return n, nil// err is EOF, so return nil explicitly }
# s = 'xiaomi9iphone8iphone7',需要在每个手机型号后面加上逗号,变成 s= 'xiaomi9,iphone8,iphone7' import re print(re.sub(r'(?=iphone)',',',s)) # 顺序肯定环视,所确定的位置右边是字符串iPhone,在此位置即可添加逗号
逆序肯定环视
1 2 3 4 5 6
# s = 'Takes Reservations:No Delivery:No Take-out:Yes Accepts Credit Cards:Yes Good for Groups:No' # 需求是要在Yes,和No的后面加上逗号,使之变成 # s = 'Takes Reservations:No, Delivery:No, Take-out:Yes, Accepts Credit Cards:Yes, Good for Groups:No' import re re.sub(r"(?<=(No))(?=(\s+))|(?<=(Yes))(?=(\s+))",',',s) # 逆序肯定环视,所要确定的位左边必须能匹配上No,或者Yes
顺序否定环视
1 2 3 4
# s = '123aaa',将s字符串变成 s='123,a,a,a,' # 分析一下,就是在字符串右侧非数字的位置,添加逗号,即使用顺序否定环视,匹配右侧非数字位置 s = '123aaa' re.sub(r'(?!\d+)',',',s)
DELETE FROM `table` WHERE `去重字段名` IN ( SELECT x FROM ( SELECT `去重字段名` AS x FROM `table` GROUP BY `去重字段名` HAVING COUNT(`去重字段名`) > 1 ) tmp0 ) AND `递增主键名` NOT IN ( SELECT y FROM ( SELECT min(`递增主键名`) AS y FROM `table` GROUP BY `去重字段名` HAVING COUNT(`去重字段名`) > 1 ) tmp1 )
]]>
mysql数据去重
dokcer.service 提示缺失bridge网络,导致Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?https://cloudsjhan.github.io/2019/06/04/dokcer-service-提示缺失bridge网络,导致Cannot-connect-to-the-Docker-daemon-at-unix-var-run-docker-sock-Is-the-docker-daemon-running/2019-06-04T07:25:01.000Z2019-06-06T08:39:54.660Z
]]>
dokcer.service 提示缺失bridge网络,导致Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
python 正则表达式及re详解https://cloudsjhan.github.io/2019/04/28/python-正则表达式及re详解/2019-04-28T06:52:31.000Z2019-04-28T08:15:06.233Z
func main(){ var wg sync.WaitGroup var urls = []string{ "http://www.golang.org/", "http://www.google.com/", } for _, url := range urls { wg.Add(1) go func(url string) { defer wg.Done() http.Get(url) }(url) } wg.Wait() }
在Golang官网中对于WaitGroup介绍是A WaitGroup must not be copied after first use,在 WaitGroup 第一次使用后,不能被拷贝
应用示例:
1 2 3 4 5 6 7 8 9 10 11 12
func main(){ wg := sync.WaitGroup{} for i := 0; i < 5; i++ { wg.Add(1) go func(wg sync.WaitGroup, i int) { fmt.Printf("i:%d", i) wg.Done() }(wg, i) } wg.Wait() fmt.Println("exit") }
运行:
1 2 3 4 5 6 7 8 9 10
i:1i:3i:2i:0i:4fatal error: all goroutines are asleep - deadlock!
// A Context carries a deadline, cancelation signal, and request-scoped values // across API boundaries. Its methods are safe for simultaneous use by multiple // goroutines. type Context interface { // Done returns a channel that is closed when this `Context` is canceled // or times out. Done() <-chan struct{}
// Err indicates why this Context was canceled, after the Done channel // is closed. Err() error
// Deadline returns the time when this Context will be canceled, if any. Deadline() (deadline time.Time, ok bool)
// Value returns the value associated with key or nil if none. Value(key interface{}) interface{} }
int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
标记-清除(mark and sweep)分为两步,标记从根变量开始迭代得遍历所有被引用的对象,对能够通过应用遍历访问到的对象都进行标记为“被引用”;标记完成后进行清除操作,对没有标记过的内存进行回收(回收同时可能伴有碎片整理操作)。这种方法解决了引用计数的不足,但是也有比较明显的问题:每次启动垃圾回收都会暂停当前所有的正常代码执行,回收是系统响应能力大大降低!当然后续也出现了很多mark&sweep算法的变种(如三色标记法)优化了这个问题。
图中灰色的那些goroutine并没有运行,而是出于ready的就绪态,正在等待被调度。P维护着这个队列(称之为runqueue),Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,在下一个调度点,就从runqueue中取出(如何决定取哪个goroutine?)一个goroutine执行。
LVS是 Linux Virtual Server 的简称,也就是Linux虚拟服务器。这是一个由章文嵩博士发起的一个开源项目,它的官方网站是LinuxVirtualServer现在 LVS 已经是 Linux 内核标准的一部分。使用 LVS 可以达到的技术目标是:通过 LVS 达到的负载均衡技术和 Linux 操作系统实现一个高性能高可用的 Linux 服务器集群,它具有良好的可靠性、可扩展性和可操作性。 从而以低廉的成本实现最优的性能。LVS 是一个实现负载均衡集群的开源软件项目,LVS架构从逻辑上可分为调度层、Server集群层和共享存储。
// A Mutex is a mutual exclusion lock which is distributed across a cluster. type Mutex struct { key string id string // The identity of the caller client client.Client kapi client.KeysAPI ctx context.Context ttl time.Duration mutex *sync.Mutex logger io.Writer }
// New creates a Mutex with the given key which must be the same // across the cluster nodes. // machines are the ectd cluster addresses func New(key string, ttl int, machines []string) *Mutex { cfg := client.Config{ Endpoints: machines, Transport: client.DefaultTransport, HeaderTimeoutPerRequest: time.Second, }
// Lock locks m. // If the lock is already in use, the calling goroutine // blocks until the mutex is available. func (m *Mutex) Lock() (err error) { m.mutex.Lock() for try := 1; try <= defaultTry; try++ { if m.lock() == nil { return nil }
m.debug("Received an event : %q", resp) if resp.Action == deleteAction || resp.Action == expireAction { return nil } }
}
// Unlock unlocks m. // It is a run-time error if m is not locked on entry to Unlock. // // A locked Mutex is not associated with a particular goroutine. // It is allowed for one goroutine to lock a Mutex and then // arrange for another goroutine to unlock it. func (m *Mutex) Unlock() (err error) { defer m.mutex.Unlock() for i := 1; i <= defaultTry; i++ { var resp *client.Response resp, err = m.kapi.Delete(m.ctx, m.key, nil) if err == nil { m.debug("Delete %v OK", m.key) return nil } m.debug("Delete %v falied: %q", m.key, resp) e, ok := err.(client.Error) if ok && e.Code == client.ErrorCodeKeyNotFound { return nil } } return err }
List 说白了就是链表(redis 使用双端链表实现的 List),相信学过数据结构知识的人都应该能理解其结构。使用 List 结构,我们可以轻松地实现最新消息排行等功能(比如新浪微博的 TimeLine )。List 的另一个应用就是消息队列,可以利用 List 的 *PUSH 操作,将任务存在 List 中,然后工作线程再用 POP 操作将任务取出进行执行。
Redis 还提供了操作 List 中某一段元素的 API,你可以直接查询,删除 List 中某一段的元素。
List 列表应用:
微博 TimeLine.
消息队列.
Set 集合
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用 Redis 提供的 Set 数据结构,可以存储一些集合性的数据。比如在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。因为 Redis 非常人性化的为集合提供了求交集、并集、差集等操作,那么就可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
在这个方案中,处理failover的方式是高可用集群软件Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。在数据共享方面,通过SAN(Storage Area Network)存储来共享数据,这种方案可以实现99.990%的SLA。
> go run rwmutex.go try to lock read 0 get locked 0 try to lock read 4 get locked 4 try to lock read 3 get locked 3 try to lock read 1 get locked 1 try to lock read 2 get locked 2 try to lock for writing try to unlock for reading 0 unlocked for reading 0 try to unlock for reading 2 unlocked for reading 2 try to unlock for reading 1 unlocked for reading 1 try to unlock for reading 3 unlocked for reading 3 try to unlock for reading 4 unlocked for reading 4 locked for writing
func (m *Map) Delete(key interface{}) { read, _ := m.read.Load().(readOnly) e, ok := read.m[key] //如果read中没有,并且dirty中有新元素,那么就去dirty中去找 if !ok && read.amended { m.mu.Lock() //这是双检查(上面的if判断和锁不是一个原子性操作) read, _ = m.read.Load().(readOnly) e, ok = read.m[key] if !ok && read.amended { //直接删除 delete(m.dirty, key) } m.mu.Unlock() } if ok { //如果read中存在该key,则将该value 赋值nil(采用标记的方式删除!) e.delete() } }
func (e *entry) delete() (hadValue bool) { for { p := atomic.LoadPointer(&e.p) if p == nil || p == expunged { return false } if atomic.CompareAndSwapPointer(&e.p, p, nil) { return true } } }
func (m *Map) Store(key, value interface{}) { // 如果m.read存在这个key,并且没有被标记删除,则尝试更新。 read, _ := m.read.Load().(readOnly) if e, ok := read.m[key]; ok && e.tryStore(&value) { return } // 如果read不存在或者已经被标记删除 m.mu.Lock() read, _ = m.read.Load().(readOnly) if e, ok := read.m[key]; ok { //如果entry被标记expunge,则表明dirty没有key,可添加入dirty,并更新entry if e.unexpungeLocked() { //加入dirty中 m.dirty[key] = e } //更新value值 e.storeLocked(&value) //dirty 存在该key,更新 } else if e, ok := m.dirty[key]; ok { e.storeLocked(&value) //read 和dirty都没有,新添加一条 } else { //dirty中没有新的数据,往dirty中增加第一个新键 if !read.amended { //将read中未删除的数据加入到dirty中 m.dirtyLocked() m.read.Store(readOnly{m: read.m, amended: true}) } m.dirty[key] = newEntry(value) } m.mu.Unlock() }
//将read中未删除的数据加入到dirty中 func (m *Map) dirtyLocked() { if m.dirty != nil { return } read, _ := m.read.Load().(readOnly) m.dirty = make(map[interface{}]*entry, len(read.m)) //read如果较大的话,可能影响性能 for k, e := range read.m { //通过此次操作,dirty中的元素都是未被删除的,可见expunge的元素不在dirty中 if !e.tryExpungeLocked() { m.dirty[k] = e } } }
//判断entry是否被标记删除,并且将标记为nil的entry更新标记为expunge func (e *entry) tryExpungeLocked() (isExpunged bool) { p := atomic.LoadPointer(&e.p) for p == nil { // 将已经删除标记为nil的数据标记为expunged if atomic.CompareAndSwapPointer(&e.p, nil, expunged) { return true } p = atomic.LoadPointer(&e.p) } return p == expunged }
//对entry 尝试更新 func (e *entry) tryStore(i *interface{}) bool { p := atomic.LoadPointer(&e.p) if p == expunged { return false } for { if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) { return true } p = atomic.LoadPointer(&e.p) if p == expunged { return false } } }
> go run goroutine.go the ch value send 0xc00009c000 the result i 0 the ch value send 0xc00009c000 the result i 1 the ch value send 0xc00009c000 the result i 2 the ch value send 0xc00009c000 the result i 3 the ch value send 0xc00009c000 the result i 4 the ch value send 0xc00009c000 the result i 5 the ch value send 0xc00009c000 the ch value receive 0xc00009c000 the result i 6 the ch value receive 0xc00009c000 the ch value send 0xc00009c000 the result i 7 the ch value send 0xc00009c000 the result i 8 the ch value send 0xc00009c000 the result i 9 the ch value send 0xc00009c000 the ch value receive 0xc00009c000 the ch value receive 0xc00009c000 the ch value receive 0xc00009c000 the result i 10 the ch value send 0xc00009c000 the result i 11 the ch value send 0xc00009c000 the result i 12 the ch value send 0xc00009c000 the result i 13 the ch value send 0xc00009c000 the ch value receive 0xc00009c000 the ch value receive 0xc00009c000 the ch value receive 0xc00009c000 the ch value receive 0xc00009c000 the result i 14 the ch value receive 0xc00009c000 > go run goroutine.go the ch value send 0xc00007e000 the result i 0 the ch value send 0xc00007e000 the result i 1 the ch value send 0xc00007e000 the result i 2 the ch value send 0xc00007e000 the result i 3 the ch value send 0xc00007e000 the ch value receive 0xc00007e000 the result i 4 the ch value send 0xc00007e000 the ch value receive 0xc00007e000 the result i 5 the ch value send 0xc00007e000 the ch value receive 0xc00007e000 the result i 6 the ch value send 0xc00007e000 the result i 7 the ch value send 0xc00007e000 the ch value receive 0xc00007e000 the ch value receive 0xc00007e000 the ch value receive 0xc00007e000 the result i 8 the ch value send 0xc00007e000 the result i 9
the NumGoroutine begin is: 1 the NumGoroutine continue is: 6 the NumGoroutine continue is: 7 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 6 the NumGoroutine continue is: 3 the NumGoroutine continue is: 2 the NumGoroutine done is: 1
package main import "fmt" func main() { type A struct { a int } type B struct { a int } a := A{1} //b := A{1} b := B{1} if a == b { fmt.Println("a == b") }else{ fmt.Println("a != b") } } // output // command-line-arguments [command-line-arguments.test] // ./.go:14:7: invalid operation: a == b (mismatched types A and B)
func main() { var m = map[string]int{ "hello": 0, "morning": 1, "my": 2, "girl": 3, } var keys []string for k := range m { keys = append(keys, k) } sort.Strings(keys) for _, k := range keys { fmt.Println("Key:", k, "Value:", m[k]) } }
> go help mod Go mod provides access to operations on modules.
Note that support for modules is built into all the go commands, not just 'go mod'. For example, day-to-day adding, removing, upgrading, and downgrading of dependencies should be done using 'go get'. See 'go help modules' for an overview of module functionality.
Usage:
go mod <command> [arguments]
The commands are:
download download modules to local cache edit edit go.mod from tools or scripts graph print module requirement graph init initialize new module in current directory tidy add missing and remove unused modules vendor make vendored copy of dependencies verify verify dependencies have expected content why explain why packages or modules are needed
Use "go help mod <command>" for more information about a command.
go mod tidy //拉取缺少的模块,移除不用的模块。 go mod download //下载依赖包 go mod graph //打印模块依赖图 go mod vendor //将依赖复制到vendor下 go mod verify //校验依赖 go mod why //解释为什么需要依赖
1
go list -m -json all //依赖详情
]]>
Go modules 使用
Python的map/reduce/filterhttps://cloudsjhan.github.io/2019/03/27/Python的map-reduce-filter/2019-03-27T03:06:12.000Z2019-03-27T03:09:29.569Z
ReplaceAllString returns a copy of src, replacing matches of the Regexp with the replacement string repl. Inside repl, $ signs are interpreted as in Expand, so for instance $1 represents the text of the first submatch.
module.exports = { build: { env: require('./prod.env'), index: path.resolve(__dirname, '../dist/index.html'), assetsRoot: path.resolve(__dirname, '../dist'), assetsSubDirectory: 'static', assetsPublicPath: '.', productionSourceMap: false, // Gzip off by default as many popular static hosts such as // Surge or Netlify already gzip all static assets for you. // Before setting to `true`, make sure to: // npm install --save-dev compression-webpack-plugin productionGzip: false, productionGzipExtensions: ['js', 'css'], // Run the build command with an extra argument to // View the bundle analyzer report after build finishes: // `npm run build --report` // Set to `true` or `false` to always turn it on or off bundleAnalyzerReport: process.env.npm_config_report }, dev: { env: require('./dev.env'), port: 8080, // hosts:"0.0.0.0", autoOpenBrowser: true, assetsSubDirectory: 'static', assetsPublicPath: '/', //配置跨域请求,注意配置完之后需要重启编译该项目 proxyTable: { //请求名字变量可以自己定义 '/api': { target: 'http://test.com', // 请求的接口域名或IP地址,开头是http或https // secure: false, // 如果是https接口,需要配置这个参数 changeOrigin: true,// 是否跨域,如果接口跨域,需要进行这个参数配置 pathRewrite: { '^/api':""//表示需要rewrite重写路径 } } }, // CSS Sourcemaps off by default because relative paths are "buggy" // with this option, according to the CSS-Loader README // (https://github.com/webpack/css-loader#sourcemaps) // In our experience, they generally work as expected, // just be aware of this issue when enabling this option. cssSourceMap: false } }
// see http://vuejs-templates.github.io/webpack for documentation. var path = require('path')
module.exports = { build: { env: require('./prod.env'), index: path.resolve(__dirname, '../dist/index.html'), assetsRoot: path.resolve(__dirname, '../dist'), assetsSubDirectory: 'static', assetsPublicPath: '.', productionSourceMap: false, // Gzip off by default as many popular static hosts such as // Surge or Netlify already gzip all static assets for you. // Before setting to `true`, make sure to: // npm install --save-dev compression-webpack-plugin productionGzip: false, productionGzipExtensions: ['js', 'css'], // Run the build command with an extra argument to // View the bundle analyzer report after build finishes: // `npm run build --report` // Set to `true` or `false` to always turn it on or off bundleAnalyzerReport: process.env.npm_config_report }, dev: { env: require('./dev.env'), port: 8080, // hosts:"0.0.0.0", autoOpenBrowser: true, assetsSubDirectory: 'static', assetsPublicPath: '/', //配置跨域请求,注意配置完之后需要重启编译该项目 proxyTable: { //请求名字变量可以自己定义 '/api': { target: 'http://billing.hybrid.cloud.ctripcorp.com', // 请求的接口域名或IP地址,开头是http或https // secure: false, // 如果是https接口,需要配置这个参数 changeOrigin: true,// 是否跨域,如果接口跨域,需要进行这个参数配置 pathRewrite: { '^/api':""//表示需要rewrite重写路径 } } }, // CSS Sourcemaps off by default because relative paths are "buggy" // with this option, according to the CSS-Loader README // (https://github.com/webpack/css-loader#sourcemaps) // In our experience, they generally work as expected, // just be aware of this issue when enabling this option. cssSourceMap: false } }
(gdb) bt #0 runtime.futex () at /usr/local/go/src/runtime/sys_linux_amd64.s:532 #1 0x000000000042b08b in runtime.futexsleep (addr=0xa9a160 <runtime.m0+320>, ns=-1, val=0) at /usr/local/go/src/runtime/os_linux.go:46 #2 0x000000000040c382 in runtime.notesleep (n=0xa9a160 <runtime.m0+320>) at /usr/local/go/src/runtime/lock_futex.go:151 #3 0x0000000000433b4a in runtime.stoplockedm () at /usr/local/go/src/runtime/proc.go:2165 #4 0x0000000000435279 in runtime.schedule () at /usr/local/go/src/runtime/proc.go:2565 #5 0x00000000004353fe in runtime.park_m (gp=0xc000066d80) at /usr/local/go/src/runtime/proc.go:2676 #6 0x000000000045ae1b in runtime.mcall () at /usr/local/go/src/runtime/asm_amd64.s:299 #7 0x000000000045ad39 in runtime.rt0_go () at /usr/local/go/src/runtime/asm_amd64.s:201 #8 0x0000000000000000 in ?? ()
(dlv) goroutine 20 Switched from 0 to 20 (thread 1628)
(dlv) stack -full 0 0x000000000042d7bb in runtime.gopark at /usr/local/go/src/runtime/proc.go:303 lock = unsafe.Pointer(0xc000104058) reason = waitReasonChanSend ··· 3 0x00000000004066a5 in runtime.chansend1 at /usr/local/go/src/runtime/chan.go:125 c = (unreadable empty OP stack) elem = (unreadable empty OP stack)
4 0x000000000062478f in main.(*Metrics).SetM at /vagrant/example/server/metrics.go:105 key = (unreadable empty OP stack) m = (unreadable empty OP stack) value = (unreadable empty OP stack)
5 0x0000000000624e64 in main.(*Metrics).sendMetricsToOutChannel at /vagrant/example/server/metrics.go:146 m = (*main.Metrics)(0xc000056040) scope = 0 updateInterval = (unreadable could not find loclist entry at 0x89f76 for address 0x624e63)
6 0x0000000000624a2f in main.(*Metrics).startInChannelConsumer at /vagrant/example/server/metrics.go:127 m = (*main.Metrics)(0xc000056040) inMetrics = main.Metric {Type: TypeCount, Scope: 0, Key: "server.req-incoming",...+2 more} nextUpdate = (unreadable could not find loclist entry at 0x89e86 for address 0x624a2e)
]]>
beego注解路由中@Param的参数解释
golang use reflect to judge type of variablehttps://cloudsjhan.github.io/2018/12/25/golang-use-reflect-to-judge-type-of-variable/2018-12-25T11:38:43.000Z2018-12-25T11:48:50.260Z
func main() { var x int32 = 20 fmt.Println("type:", reflect.TypeOf(x)) }
]]>
golang use reflect to judge type of variable
mysql add primary key auto_incrementhttps://cloudsjhan.github.io/2018/12/25/mysql-add-primary-key-auto-increment/2018-12-25T11:08:53.000Z2018-12-25T11:52:17.418Z
添加字段id,并将其设置为主键自增
alter table TABLE_NAME add id int not null primary key Auto_increment
如果想添加已经有了一列为主键,可以用:
alter table TABLE_NAME add primary key(COL_NAME);
如果想修改一列为主键,则需要先删除原来的主键:
alter table TABLE_NAME drop primary key;
再重新添加主键:
alter table TABLE_NAME add primary key(COL_NAME);
]]>
MySQL add primary key auto_increment for established table
Go关于time包的解析与使用https://cloudsjhan.github.io/2018/12/16/Go关于time包的解析与使用/2018-12-16T15:16:34.000Z2019-01-09T11:24:47.279Z
Environments are a group of variables & values, that allow you to quickly switch the context for your requests and collections. Learn more about environments You can declare a variable in an environment and give it a starting value, then use it in a request by putting the variable name within curly-braces. Create an environment to get started.
输入 Key 和 value:
点击 Add 后:
[info] 环境变量可以使用的地方
URL
URL params
Header values
form-data/url-encoded values
Raw body content
Helper fields
写 test 测试脚本中
通过 postman 的接口,获取或设置环境变量的值。
此处把之前的在 url 中的 IP 地址(或域名)换成环境变量:
鼠标移动到环境变量上,可以动态显示出具体的值:
再去添加另外一个开发环境:
则可添加完 2 个环境变量,表示两个服务器地址,两个版本:
然后就可以切换不同服务器环境了:
可以看到,同样的变量 server_address,在切换后对应 IP 地址就变成希望的开发环境的 IP 了:
[root@k8s-m1 ~]# influx Connected to http://localhost:8086 version 1.7.1 InfluxDB shell version: 1.7.1 Enter an InfluxQL query >
到此完成了influxDB的安装,接下来我们做基本的配置。
配置
用户管理
1 2 3 4 5 6 7 8 9 10
-- 创建一个管理员用户 CREATE USER "admin" WITH PASSWORD 'xxxx' WITH ALL PRIVILEGES -- 创建一个普通用户 CREATE USER "user" WITH PASSWORD 'xxxxx' -- 为用户授权读权限 GRANT READ ON [database] to "user" -- 为用户授权写权限 GRANT WRITE ON [database] to "user" --------------------- # 需要修改InfluxDB的配置文件/etc/influxdb/influxdb.conf,设置http下的auth-enabled = true,重启后,使用influx命令登录数据库就需要用户名和密码了。(Influx命令实际上也是使用API来操作InfluxDB的,InfluxDB只提供了API接口)
查看用户
1 2 3 4 5 6
> show users user admin ---- ----- admin true sjhan true >
When a coroutine blocks, such as by calling a blocking system call, the run-time automatically moves other coroutines on the same operating system thread to a different, runnable thread so they won’t be blocked.
]]>
git常用基本操作
ionic project-Could not find module @angular-devkit/build-angular from XXXhttps://cloudsjhan.github.io/2018/11/30/ionic-project-Could-not-find-module-angular-devkit-build-angular-from-XXX/2018-11-30T14:02:49.000Z2018-11-30T14:45:25.088Z
从GitHub上找了一个ionic的demo,准备运行一下,报错:Could not find module @angular-devkit/build-angular from XXX
Could not find module "@angular-devkit/build-angular" from
解决方案:
npm install –save @angular-devkit/build-angular
]]>
ionic project-Could not find module @angular-devkit/build-angular from XXX
快排之golang实现https://cloudsjhan.github.io/2018/11/18/快排之golang实现/2018-11-18T06:36:38.000Z2018-11-19T02:09:59.522Z
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
funcquickSort(sortArray []int, left, right int) { if left < right { pos := partition2(sortArray, left, right)//修改此处测试不同的实现方式 quickSort(sortArray, left, pos-1) quickSort(sortArray, pos+1, right) } }
BUT!
要表达快排的思想,还是使用Python比较透彻:
1 2 3 4 5 6 7 8 9
defquickSort(array):
if len(array) < 2: return array else: pivot = array[0] less = [i for i in array[1:] if i <= pivot] greater = [i for i in array[1:] if i > pivot] return quickSort(less) + [pivot] + quickSort(greater)
Usage of /tmp/go-build327358548/command-line-arguments/_obj/a.out: -baudrate=1200: help message for flagname -databits=10: number of data bits exit status 2
\2. Identiers 2.1. Choose identiers for clarity, not brevity 2.2. Identier length 2.3. Don’t name your variables for their types 2.4. Use a consistent naming style 2.5. Use a consistent declaration style 2.6. Be a team player
\3. Comments 3.1. Comments on variables and constants should describe their contents not their purpose 3.2. Always document public symbols
\4. Package Design 4.1. A good package starts with its name 4.2. Avoid package names like base , common , or util 4.3. Return early rather than nesting deeply 4.4. Make the zero value useful 4.5. Avoid package level state
\5. Project Structure 5.1. Consider fewer, larger packages 5.2. Keep package main small as small as possible
\6. API Design 6.1. Design APIs that are hard to misuse. 6.2. Design APIs for their default use case 6.3. Let functions dene the behaviour they requires
\7. Error handling 7.1. Eliminate error handling by eliminating errors 7.2. Only handle an error once
\8. Concurrency 8.1. Keep yourself busy or do the work yourself 8.2. Leave concurrency to the caller 8.3. Never start a goroutine without when it will stop.
Introduction
Hello, My goal over the next two sessions is to give you my advice for best practices writing Go code.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
This is a workshop style presentation, I’m going to dispense with the usual slide deck and we’ll work directly from the document which you can take away with you today.
If I’m going to talk about best practices in any programming language I need some way to define what I mean by best. If you came to my keynote yesterday you would have seen this quote from the Go team lead, Russ Cox:
“Software engineering is what happens to programming when you add time and other programmers.
— Russ Cox
Russ is making the distinction between software programming and software engineering. The former is a program you write for yourself. The latter is a product that many people will work on over time. Engineers will come and go, teams will grow and shrink over time, requirements will change, features will be added and bugs fixed. This is the nature of software engineering.
I’m possibly one of the earliest users of Go in this room, but to argue that my seniority gives my views more weight is false. Instead, the advice I’m going to present today is informed by what I believe to be the guiding principles underlying Go itself. They are:
\1. Simplicity \2. Readability 3. Productivity
NOTE
You’ll note that I didn’t say performance, or concurrency. There are languages which are a bit faster than Go, but they’re certainly not as simple as Go. There are languages which make concurrency their highest goal, but they are not as readable, nor as productive.
Performance and concurrency are important attributes, but not as important as simplicity, readability, and productivity.
1.1. Simplicity
Why should we strive for simplicity? Why is important that Go programs be simple?
We’ve all been in a situation where you say “I can’t understand this code”, yes? We’ve all worked on programs where you’re scared to make a change because you’re worried it’ll break another part of the program; a part you don’t understand and don’t know how to fix.
This is complexity. Complexity turns reliable software in unreliable software. Complexity is what kills software projects.
Simplicity is the highest goal of Go. Whatever programs we write, we should be able to agree that they are simple.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
“Readability is essential for maintainability. — Mark Reinhold
JVM language summit 2018
Why is it important that Go code be readable? Why should we strive for readability?
“Programs must be written for people to read, and only incidentally for machines to execute. — Hal Abelson and Gerald Sussman
Structure and Interpretation of Computer Programs
Readability is important because all software, not just Go programs, is written by humans to be read by other humans. The fact that software is also consumed by machines is secondary.
Code is read many more times than it is written. A single piece of code will, over its lifetime, be read hundreds, maybe thousands of times.
“The most important skill for a programmer is the ability to effectively communicate ideas. — Gastón Jorquera [1]
Readability is key to being able to understand what the program is doing. If you can’t understand what a program is doing, how can you hope to maintain it? If software cannot be maintained, then it will be rewritten; and that could be the last time your company will invest in Go.
If you’re writing a program for yourself, maybe it only has to run once, or you’re the only person who’ll ever see it, then do what ever works for you. But if this is a piece of software that more than one person will contribute to, or that will be used by people over a long enough time that requirements, features, or the environment it runs in changes, then your goal must be for your program to be maintainable.
The first step towards writing maintainable code is making sure the code is readable.
“1.3. Productivity Design is the art of arranging code to work today, and be changeable forever.
— Sandi Metz
The last underlying principle I want to highlight is productivity. Developer productivity is a sprawling topic but it boils down to this; how much time do you spend doing useful work verses waiting for your tools or hopelessly lost in a foreign code-base. Go programmers should feel that they can get a lot done with Go.
The joke goes that Go was designed while waiting for a C++ program to compile. Fast compilation is a key feature of Go and a key recruiting tool to attract new developers. While compilation speed remains a constant battleground, it is fair to say that compilations which take minutes in other languages, take seconds in Go. This helps Go developers feel as productive as their counterparts working in dynamic languages without the reliability issues inherent in those languages.
More fundamental to the question of developer productivity, Go programmers realise that code is written to be read and so place the act of reading code above the act of writing it. Go goes so far as to enforce, via tooling and custom, that all code be formatted in a specific style. This removes the friction of learning a project specific dialect and helps spot mistakes because they just look incorrect.
Go programmers don’t spend days debugging inscrutable compile errors. They don’t waste days with complicated build scripts or deploying code to production. And most importantly they don’t spend their time trying to understand what their coworker wrote.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Productivity is what the Go team talk about when they say the language must scale. 2. Identiers
The first topic we’re going to discuss is identifiers. An identifier is a fancy word for a name; the name of a variable, the name of a function, the name of a method, the name of a type, the name of a package, and so on.
“Poor naming is symptomatic of poor design. — Dave Cheney
Given the limited syntax of Go, the names we choose for things in our programs have an oversized impact on the readability of our programs. Readability is the defining quality of good code thus choosing good names is crucial to the readability of Go code.
“2.1. Choose identiers for clarity, not brevity Obvious code is important. What you can do in one line you should do in three.
— Ukiah Smith
Go is not a language that optimises for clever one liners. Go is not a language which optimises for the least number of lines in a program. We’re not optimising for the size of the source code on disk, nor how long it takes to type.
“Good naming is like a good joke. If you have to explain it, it’s not funny. — Dave Cheney
Key to this clarity is the names we choose for identifies in Go programs. Let’s talk about the qualities of a good name:
A good name is concise. A good name need not be the shortest it can possibly be, but a good name should waste no space on things which are extraneous. Good names have a high signal to noise ratio.
A good name is descriptive. A good name should describe the application of a variable or constant, not their contents. A good name should describe the result of a function, or behaviour of a method, not their operation. A good name should describe the purpose of a package, not its contents. The more accurately a name describes the thing it identifies, the better the name.
A good name is should be predictable. You should be able to infer the way a name will be used from its name alone. This is a function of choosing descriptive names, but it also about following tradition. This is what Go programmers talk about when they say idiomatic.
Let’s talk about each of these properties in depth.
2.2. Identier length
Sometimes people criticise the Go style for recommending short variable names. As Rob Pike said, “Go programmers want the right length identifiers”. [1]
Andrew Gerrand suggests that by using longer identifies for some things we indicate to the reader that they are of higher importance.
“The greater the distance between a name’s declaration and its uses, the longer the name should be.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Short variable names work well when the distance between their declaration and last use is short. Long variable names need to justify themselves; the longer they are the more value they need to provide. Lengthy
bureaucratic names carry a low amount of signal compared to their weight on the page.
Don’t include the name of your type in the name of your variable.
Constants should describe the value they hold, not how that value is used.
Single letter variables for loops and branches, single words for parameters and return values, multiple words for functions and package level declarations
Single words for methods, interfaces, and packages. Remember that the name of a package is part of the name the caller uses to to refer to it, so make use of that.
Let’s look at an example to
1 2
type Person struct { Name string
Age int }
1 2 3 4
// AverageAge returns the average age of people. func AverageAge(people []Person) int { if len(people) == 0 { return 0
}
1 2
var count, sum int for _, p := range people {
sum += p.Age
count += 1 }
1 2
return sum / count }
GO
In this example, the range variable p is declared on line 10 and only referenced on the following line. p lives for a very short time both on the page, and during the execution of the function. A reader who is interested in the effect values of p have on the program need only read two lines.
By comparison people is declared in the function parameters and lives for seven lines. The same is true for sum , and count , thus they justify their longer names. The reader has to scan a wider number of lines to locate them so they are
given more distinctive names.
I could have chosen s for sum and c (or possibly n ) for but this would have reduced all the variables in the program to the same level of importance. I could have chosen instead of but that would have left the problem of what to call the for … range iteration variable. The singular would look odd as the loop iteration variable which lives for little time has a longer name than the slice of values it was derived from.
count
TIP
Use blank lines to break up the flow of a function in the same way you use paragraphs to break up the flow of a document. In AverageAge we have three operations occurring in sequence. The first is the precondition, checking that we don’t divide by zero if people is empty, the second is the accumulation of the sum and count, and the final is the computation of the average.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
It’s important to recognise that most advice on naming is contextual. I like to say it is a principle, not a rule.
What is the difference between two identifiers, i , and index . We cannot say conclusively that one is better than another, for example is
fundamentally more readable than
I argue it is not, because it is likely the scope of i , and index for that matter, is limited to the body of the for loop and the extra verbosity of the latter adds little to comprehension of the program.
However, which of these functions is more readable?
1
func (s *SNMP) Fetch(oid []int, index int) (int, error)
or
1
func (s *SNMP) Fetch(o []int, i int) (int, error)
In this example, oid is an abbreviation for SNMP Object ID, so shortening it to o would mean programmers have to translate from the common notation that they read in documentation to the shorter notation in your code. Similarly, reducing index to i obscures what i stands for as in SNMP messages a sub value of each OID is called an Index.
TIP Don’t mix and match long and short formal parameters in the same declaration. 2.3. Don’t name your variables for their types
You shouldn’t name your variables after their types for the same reason you don’t name your pets “dog” and “cat”. You also probably shouldn’t include the name of your type in the name of your variable’s name for the same reason.
The name of the variable should describe its contents, not the type of the contents. Consider this example: var usersMap map[string]*User
What’s good about this declaration? We can see that its a map, and it has something to do with the *User type, that’s probably good. But usersMap is a map, and Go being a statically typed language won’t let us accidentally use it where a scalar variable is required, so the Map suffix is redundant.
Now, consider what happens if we were to declare other variables like:
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
1 2 3
var ( companiesMap map[string]*Company productsMap map[string]*Products
)
Now we have three map type variables in scope, usersMap , companiesMap , and productsMap , all mapping strings to different types. We know they are maps, and we also know that their map declarations prevent us from using one in place of another—the compiler will throw an error if we try to use companiesMap where the code is expecting a
map[string]*User . In this situation it’s clear that the Map suffix does not improve the clarity of the code, its just extra boilerplate to type.
My suggestion is to avoid any suffix that resembles the type of the variable. TIP If users isn’t descriptive enough, then usersMap won’t be either.
This advice also applies to function parameters. For example:
Naming the Config parameter config is redundant. We know its a Config , it says so right there. In this case consider conf or maybe c will do if the lifetime of the variable is short enough.
If there is more that one in scope at any one time then calling them conf1 and conf2 is less descriptive than calling them and as the latter are less likely to be mistaken for one another.
Don’t let package names steal good variable names.
The name of an imported identifier includes its package name. For example the context package will be known as context.Context . This makes it impossible to use
a variable or type in your package.
type in the as
func WriteLog(context context.Context, message string) Will not compile. This is why the local declaration for context.Context types is traditionally ctx .
Another property of a good name is it should be predictable. The reader should be able to understand the use of a name when they encounter it for the first time. When they encounter a common name, they should be able to assume it has not changed meanings since the last time they saw it.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
For example, if your code passes around a database handle, make sure each time the parameter appears, it has the same name. Rather than a combination of d sql.DB , dbase sql.DB , DB sql.DB , and database sql.DB , instead consolidate on something like;
db sql.DB Doing so promotes familiarity; if you see a db , you know it’s a sql.DB and that it has either been declared locally or
provided for you by the caller.
Similarly for method receivers; use the same receiver name every method on that type. This makes it easier for the reader to internalise the use of the receiver across the methods in this type.
The convention for short receiver names in Go is at odds with the advice provided so far. This is just NOTE one of the choices made early on that has become the preferred style, just like the use of CamelCase
TIP
rather than snake_case .
Go style dictates that receivers have a single letter name, or acronyms derived from their type. You may find that the name of your receiver sometimes conflicts with name of a parameter in a method. In this case, consider making the parameter name slightly longer, and don’t forget to use this new parameter name consistently.
Finally, certain single letter variables have traditionally been associated with loops and counting. For example, i , j , and k are commonly the loop induction variable for simple for loops. n is commonly associated with a counter or accumulator. v is a common shorthand for a value in a generic encoding function, k is commonly used for the key of a map, and s is often used as shorthand for parameters of type string .
As with the db example above programmers expect to be a loop induction variable. If you ensure that is always a loop variable, not used in other contexts outside a loop. When readers encounter a variable called , or j , they know that a loop is close by.
i
i
for
i
TIP
If you found yourself with so many nested loops that you exhaust your supply of i , j , and k variables, its probably time to break your function into smaller units.
2.5. Use a consistent declaration style
Go has at least six different ways to declare a variable
varxint=1 varx=1 varxint;x=1 var x = int(1) x:=1
I’m sure there are more that I haven’t thought of. This is something that Go’s designers recognise was probably a mistake, but its too late to change it now. With all these different ways of declaring a variable, how do we avoid each Go programmer choosing their own style?
I want to present a suggestions for how I declare variables in my programs. This is the style I try to use where possible.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
When declaring, but not initialising, a variable, use var . When declaring a variable that will be explicitly initialised later in the function, use the var keyword.
The var acts as a clue to say that this variable has been deliberately declared as the zero value of the indicated type. This is also consistent with the requirement to declare variables at the package level using var as opposed to the short declaration syntax—although I’ll argue later that you shouldn’t be using package level variables at all.
When declaring and initialising, use := . When declaring and initialising the variable at the same time, that is to say we’re not letting the variable be implicitly initialised to its zero value, I recommend using the short variable declaration form. This makes it clear to the reader that the variable on the left hand side of the := is being deliberately initialised.
To explain why, Let’s look at the previous example, but this time deliberately initialising each variable:
In the first and third examples, because in Go there are no automatic conversions from one type to another; the type on the left hand side of the assignment operator must be identical to the type on the right hand side. The compiler can infer the type of the variable being declared from the type on the right hand side, to the example can be written more concisely like this:
This leaves us with explicitly initialising players to 0 which is redundant because 0 is `players’ zero value. So its better to make it clear that we’re going to use the zero value by instead writing
1
var players int
What about the second statement? We cannot elide the type and write
var things = nil Because nil does not have a type. [2] Instead we have a choice, do we want the zero value for a slice?
1 2 3 4 5 6 7 8 9 10 11 12
var players int // 0 var things []Thing // an empty slice of Things var thing Thing // empty Thing struct json.Unmarshall(reader, &thing) var players int = 0 var things []Thing = nil var thing *Thing = new(Thing) json.Unmarshall(reader, thing) var players = 0 var things []Thing = nil var thing = new(Thing) json.Unmarshall(reader, thing)
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
1
var things []Thing
or do we want to create a slice with zero elements?
1
var things = make([]Thing, 0)
If we wanted the latter then this is not the zero value for a slice so we should make it clear to the reader that we’re making this choice by using the short declaration form:
things := make([]Thing, 0) Which tells the reader that we have chosen to initialise things explicitly.
This brings us to the third declaration,
var thing = new(Thing) Which is both explicitly initialising a variable and introduces the uncommon use of the new keyword which some Go
programmer dislike. If we apply our short declaration syntax recommendation then the statement becomes
thing := new(Thing) Which makes it clear that thing is explicitly initialised to the result of new(Thing) –a pointer to a Thing –but still
leaves us with the unusual use of new . We could address this by using the compact literal struct initialiser form, thing := &Thing{}
Which does the same as means we’re explicitly initialising
, hence why some Go programmers are upset by the duplication. However this with a pointer to a Thing{} , which is the zero value for a Thing .
new(Thing)
thing
Instead we should recognise that is being declared as its zero value and use the address of operator to pass the address of thing to
thing
1 2 3
json.Unmarshall var thing Thing json.Unmarshall(reader, &thing)
Practical Go: Real world advice for writing maintainable Go programs
NOTE
Of course, with any rule of thumb, there are exceptions. For example, sometimes two variables are closely related so writing
Would be odd. The declaration may be more readable like this
min, max := 0, 1000
1 2
var min int max := 1000
In summary: When declaring a variable without initialisation, use the var syntax.
When declaring and explicitly initialising a variable, use := . Make tricky declarations obvious.
When something is complicated, it should look complicated. var length uint32 = 0x80
Here length may be being used with a library which requires a specific numeric type and is more TIP explicit that length is being explicitly chosen to be uint32 than the short declaration form:
length := uint32(0x80)
In the first example I’m deliberately breaking my rule of using the var declaration form with an explicit initialiser. This decision to vary from my usual form is a clue to the reader that something unusual is happening.
2.6. Be a team player
I talked about a goal of software engineering to produce readable, maintainable, code. Therefore you will likely spend most of your career working on projects of which you are not the sole author. My advice in this situation is to follow the local style.
Changing styles in the middle of a file is jarring. Uniformity, even if its not your preferred approach, is more valuable for maintenance than your personal preference. My rule of thumb is; if it fits through gofmt then its usually not worth holding up a code review for.
If you want to do a renaming across a code-base, do not mix this into another change. If someone is TIP using git bisect they don’t want to wade through thousands of lines of renaming to find the code you
changed as well.
\3. Comments
Before we move on to larger items I want to spend a few minutes talking about comments.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
“Good code has lots of comments, bad code requires lots of comments. — Dave Thomas and Andrew Hunt
The Pragmatic Programmer
Comments are very important to the readability of a Go program. A comments should do one of three things:
\1. The comment should explain what the thing does. \2. The comment should explain how the thing does what it does. 3. The comment should explain why the thing is why it is.
The first form is ideal for commentary on public symbols:
The second form is ideal for commentary inside a method:
The third form, the why , is unique as it does not displace the first two, but at the same time it’s not a replacement for the what, or the how. The why style of commentary exists to explain the external factors that drove the code you read on the page. Frequently those factors rarely make sense taken out of context, the comment exists to provide that context.
In this example it may not be immediately clear what the effect of setting HealthyPanicThreshold to zero percent will do. The comment is needed to clarify that the value of 0 will disable the panic threshold behaviour.
3.1. Comments on variables and constants should describe their contents not their purpose
I talked earlier that the name of a variable, or a constant, should describe its purpose. When you add a comment to a variable or constant, that comment should describe the variables contents, not the variables purpose.
1
const randomNumber = 6 // determined from an unbiased die
In this example the comment describes why is assigned the value six, and where the six was derived from. The comment does not describe where will be used. Here are some more examples:
1 2 3 4 5
// Open opens the named file for reading. // If successful, methods on the returned file can be used for reading. // queue all dependant actions var results []chan error for _, dep := range a.Deps {
In the context of HTTP the number 100 is known as StatusContinue , as defined in RFC 7231, section 6.2.1. For variables without an initial value, the comment should describe who is responsible for
// sizeCalculationDisabled indicates whether it is safe // to calculate Types’ widths and alignments. See dowidth. var sizeCalculationDisabled bool
TIP
initialising this variable.
Here the comment lets the reader know that the dowidth function is responsible for maintaining the state of sizeCalculationDisabled .
Hiding in plain sight
This is a tip from Kate Gregory. [3] Sometimes you’ll find a better name for a variable hiding in a comment.
The comment was added by the author because registry doesn’t explain enough about its purpose —it’s a registry, but a registry of what?
By renaming the variable to sqlDrivers its now clear that the purpose of this variable is to hold SQL drivers.
var sqlDrivers = make(map[string]*sql.Driver)
Now the comment is redundant and can be removed.
// registry of SQL drivers var registry = make(map[string]*sql.Driver)
TIP
3.2. Always document public symbols
Because godoc is the documentation for your package, you should always add a comment for every public symbol— variable, constant, function, and method—declared in your package.
Here are two rules from the Google Style guide
Any public function that is not both obvious and short must be commented. Any function in a library must be commented regardless of length or complexity
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
1 2 3 4 5 6
package ioutil // ReadAll reads from r until an error or EOF and returns the data it read. // A successful call returns err == nil, not err == EOF. Because ReadAll is // defined to read from src until EOF, it does not treat an EOF from Read // as an error to be reported. func ReadAll(r io.Reader) ([]byte, error)
There is one exception to this rule; you don’t need to document methods that implement an interface. Specifically don’t do this:
This comment says nothing. It doesn’t tell you what the method does, in fact it’s worse, it tells you to go look somewhere else for the documentation. In this situation I suggest removing the comment entirely.
// Read implements the io.Reader interface func (r *FileReader) Read(buf []byte) (int, error) // LimitReader returns a Reader that reads from r // but stops with EOF after n bytes. // The underlying implementation is a *LimitedReader. func LimitReader(r Reader, n int64) Reader { return &LimitedReader{r, n} } // A LimitedReader reads from R but limits the amount of // data returned to just N bytes. Each call to Read // updates N to reflect the new amount remaining. // Read returns EOF when N <= 0 or when the underlying R returns EOF. type LimitedReader struct { R Reader // underlying reader N int64 // max bytes remaining } func (l *LimitedReader) Read(p []byte) (n int, err error) { if l.N <= 0 { return 0, EOF } if int64(len(p)) > l.N { p = p[0:l.N] } n, err = l.R.Read(p) l.N -= int64(n) return
}
Note that the declaration is directly preceded by the function that uses it, and the declaration of follows the declaration of LimitedReader itself. Even though LimitedReader.Read has no
documentation itself, its clear from that it is an implementation of io.Reader .
1 2
LimitedReader LimitedReader.Read
TIP
Before you write the function, write the comment describing the function. If you find it hard to write the comment, then it’s a sign that the code you’re about to write is going to be hard to understand.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
“ Don’t comment bad code — rewrite it — Brian Kernighan
Comments highlighting the grossness of a particular piece of code are not sufficient. If you encounter one of these comments, you should raise an issue as a reminder to refactor it later. It is okay to live with technical debt, as long as the amount of debt is known.
The tradition in the standard library is to annotate a TODO style comment with the username of the person who noticed it.
1
// TODO(dfc) this is O(N^2), find a faster way to do this.
The username is not a promise that that person has committed to fixing the issue, but they may be the best person to ask when the time comes to address it. Other projects annotate TODOs with a date or an issue number.
“3.2.2. Rather than commenting a block of code, refactor it
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer.
— Steve McConnell
Functions should do one thing only. If you find yourself commenting a piece of code because it is unrelated to the rest of the function, consider extracting it into a function of its own.
In addition to be easier to comprehend, smaller functions are easier to test in isolation, and now you’ve isolated the orthogonal code into its own function, its name may be all the documentation required.
“4. Package Design Write shy code - modules that don’t reveal anything unnecessary to other modules and that
don’t rely on other modules’ implementations.
— Dave Thomas
Each Go package is in effect it’s own small Go program. Just as the implementation of a function or method is unimportant to the caller, the implementation of the functions and methods and types that make your package’s public API—its behaviour—is unimportant for the caller.
A good Go package should strive to have a low degree of source level coupling such that, as the project grows, changes to one package do not cascade across the code-base. These stop-the-world refactorings place a hard limit on the rate of change in a code base and thus the productivity of the members working in that code-base.
In this section we’ll talk about designing a package including the package’s name, naming types, and tips for writing methods and functions.
4.1. A good package starts with its name
Writing a good Go package starts with the package’s name. Think of your package’s name as an elevator pitch to describe what it does using just one word.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Just as I talked about names for variables in the previous section, the name of a package is very important. The rule of thumb I follow is not, “what types should I put in this package?”. Instead the question I ask “what does service does package provide?” Normally the answer to that question is not “this package provides the X type”, but “this package let’s you speak HTTP”.
TIP Name your package after what is provides, not what it contains. 4.1.1. Good package names should be unique.
Within your project, each package name should be unique. This advice is pretty easy to follow if the advice that a package’s name should derive from its purpose—if you find you have two packages which need the same name, it is likely either;
a. The name of the package is too generic.
b. The package overlaps another package of a similar name. In this case either you should review your design, or consider merging the packages.
4.2. Avoid package names like base , common , or util
A common cause of poor package names is what call utility packages. These are packages where common helpers and utility code congeals over time. As these packages contain an assortment of unrelated functions, their utility is hard to describe in terms of what the package provides. This often leads to the package’s name being derived from what the package contains–utilities.
Package names like utils or helpers are commonly found in larger projects which have developed deep package hierarchies and want to share helper functions without encountering import loops. By extracting utility functions to new package the import loop is broken, but because the package stems from a design problem in the project, its name doesn’t reflect its purpose, only its function of breaking the import cycle.
My recommendation to improve the name of utils or helpers packages is to analyse where they are called and if possible move the relevant functions into their caller’s package. Even if this involves duplicating some helper code this is better than introducing an import dependency between two packages.
“[A little] duplication is far cheaper than the wrong abstraction. — Sandy Metz
In the case where utility functions are used in many places prefer multiple packages, each focused on a single aspect, to a single monolithic package.
TIP Use plurals for naming utility packages. For example the strings for string handling utilities.
Packages with names like base or common are often found when functionality common to two or more implementations, or common types for a client and server, has been refactored into a separate package. I believe the solution to this is to reduce the number of packages, to combine the client, server, and common code into a single package named after the function of the package.
For example, the net/http package does not have client and sub packages, instead it has a client.go and server.go file, each holding their respective types, and a file for the common message transport code.
Practical Go: Real world advice for writing maintainable Go programs
TIP
An identifier’s name includes its package name.
It’s important to remember that the name of an identifier includes the name of its package.
The Get function from the net/http package becomes http.Get when referenced by another package.
The Reader type from the strings package becomes strings.Reader when imported into other packages.
The Error interface from the net package is clearly related to network errors. 4.3. Return early rather than nesting deeply
As Go does not use exceptions for control flow there is no requirement to deeply indent your code just to provide a top level structure for the try and catch blocks. Rather than the successful path nesting deeper and deeper to the right, Go code is written in a style where the success path continues down the screen as the function progresses. My friend Mat Ryer calls this practice ‘line of sight’ coding. [4]
This is achieved by using guard clauses; conditional blocks with assert preconditions upon entering a function. Here is an example from the bytes package,
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune") } if b.off >= int(b.lastRead) { b.off -= int(b.lastRead) } b.lastRead = opInvalid
return nil }
Upon entering UnreadRune the state of b.lastRead is checked and if the previous operation was not an error is returned immediately. From there the rest of the function proceeds with the assertion that is greater that opInvalid .
Compare this to the same function written without a guard clause,
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune")
}
GO
The body of the successful case, the most common, is nested inside the first if condition and the successful exit condition, return nil , has to be discovered by careful matching of closing braces. The final line of the function now returns an error, and the called must trace the execution of the function back to the matching opening brace to know
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
when control will reach this point.
This is more error prone for the reader, and the maintenance programmer, hence why Go prefer to use guard clauses and returning early on errors.
4.4. Make the zero value useful
Every variable declaration, assuming no explicit initialiser is provided, will be automatically initialised to a value that matches the contents of zeroed memory. This is the values zero value. The type of the value determines its zero value; for numeric types it is zero, for pointer types nil, the same for slices, maps, and channels.
This property of always setting a value to a known default is important for safety and correctness of your program and can make your Go programs simpler and more compact. This is what Go programmers talk about when they say “give your structs a useful zero value”.
Consider the sync.Mutex type. sync.Mutex contains two unexported integer fields, representing the mutex’s internal state. Thanks to the zero value those fields will be set to will be set to 0 whenever a sync.Mutex is declared.
sync.Mutex has been deliberately coded to take advantage of this property, making the type usable without explicit initialisation.
1 2
type MyInt struct { mu sync.Mutex
val int }
1 2 3 4 5 6
func main() { var i MyInt // i.mu is usable without explicit initialisation. i.mu.Lock() i.val++ i.mu.Unlock()
}
GO
Another example of a type with a useful zero value is bytes.Buffer . You can declare a bytes.Buffer and start writing to it without explicit initialisation.
A useful property of slices is their zero value is nil . This makes sense if we look at the runtime’s definition of a slice header.
1 2 3 4
func main() { var b bytes.Buffer b.WriteString("Hello, world!\n") io.Copy(os.Stdout, &b)
}
GO
1 2 3 4
type slice struct { array *[...]T // pointer to the underlying array len int cap int
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
The zero value of this struct would imply len and cap have the value 0 , and array , the pointer to memory holding the contents of the slice’s backing array, would be nil . This means you don’t need to explicitly make a slice, you can just declare it.
1 2 3 4 5 6 7
func main() { // s := make([]string, 0) // s := []string{} var s []string s = append(s, "Hello") s = append(s, "world") fmt.Println(strings.Join(s, " "))
}
GO
var s []string is similar to the two commented lines above it, but not identical. It is possible to detect the difference between a slice value that is nil and a slice value that has zero length. The following code will output false.
NOTE
A surprising, but useful, property of uninitialised pointer variables—nil pointers—is you can call methods on types that have a nil value. This can be used to provide default values simply.
func main() { var s1 = []string{} var s2 []string fmt.Println(reflect.DeepEqual(s1, s2))
}
GO
1 2
type Config struct { path string
}
1 2 3 4 5 6 7 8 9 10
func (c *Config) Path() string { if c == nil { return "/usr/home" } return c.path } func main() { var c1 *Config var c2 = &Config{ path: "/export",
}
1 2
fmt.Println(c1.Path(), c2.Path()) }
GO
4.5. Avoid package level state
The key to writing maintainable programs is that they should be loosely coupled—a change to one package should have a low probability of affecting another package that does not directly depend on the first.
There are two excellent ways to achieve loose coupling in Go
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
\1. Use interfaces to describe the behaviour your functions or methods require. 2. Avoid the use of global state.
In Go we can declare variables at the function or method scope, and also at the package scope. When the variable is public, given a identifier starting with a capital letter, then its scope is effectively global to the entire program—any package may observe the type and contents of that variable at any time.
Mutable global state introduces tight coupling between independent parts of your program as global variables become an invisible parameter to every function in your program! Any function that relies on a global variable can be broken if that variable’s type changes. Any function that relies on the state of a global variable can be broken if another part of the program changes that variable.
If you want to reduce the coupling a global variable creates,
\1. Move the relevant variables as fields on structs that need them. \2. Use interfaces to reduce the coupling between the behaviour and the implementation of that behaviour.
\5. Project Structure
Let’s talk about combining packages together into a project. Commonly this will be a single git repository, but in the future Go developers will use module and project interchangeably.
Just like a package, each project should have a clear purpose. If your project is a library, it should provide one thing, say XML parsing, or logging. You should avoid combining multiple purposes into a single package, this will help avoid the dreaded common library.
In my experience, the common repo ends up tightly coupled to its biggest consumer and that makes TIP it hard to back-port fixes without upgrading both common and consumer in lock step, bringing in a
lot of unrelated changes and API breakage along the way.
If your project is an application, like your web application, Kubernetes controller, and so on, then you might have one or more packages inside your project. For example, the Kubernetes controller I work on has a single
package which serves as both the server deployed to a Kubernetes cluster, and a client for debugging
purposes.
5.1. Consider fewer, larger packages
One of the things I tend to pick up in code review for programmers who are transitioning from other languages to Go is they tend to overuse packages.
Go does not provide elaborate ways of establishing visibility; thing Java’s public , protected , private , and implicit default access modifiers. There is no equivalent of C++’s notion of friend classes.
In Go we have only two access modifiers, public and private, indicated by the capitalisation of the first letter of the identifier. If an identifier is public, it’s name starts with a capital letter, that identifier can be referenced by any other Go package.
NOTE You may hear people say exported and not exported as synonyms for public and private. Given the limited controls available to control access to a package’s symbols, what practices should Go programmers
follow to avoid creating over-complicated package hierarchies?
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
TIP Every package, with the exception of cmd/ and internal/ , should contain some source code.
The advice I find myself repeating is to prefer fewer, larger packages. Your default position should be to not create a new package. That will lead to too many types being made public creating a wide, shallow, API surface for your package..
The sections below explores this suggestion in more detail.
TIP
Coming from Java?
If you’re coming from a Java or C# background, consider this rule of thumb. - A Java package is equivalent to a single .go source file. - A Go package is equivalent to a whole Maven module or .NET assembly.
5.1.1. Arrange code into les by import statements
If you’re arranging your packages by what they provide to callers, should you do the same for files within a Go package? How do you know when you should break up a .go file into multiple ones? How do you know when you’ve gone to far and should consider consolidating .go file?
Here are the rules of thumb I use: Start each package with one file. Give that file the same name as the name of the folder. eg. package http
should be placed in a file called in a directory named http .
As your package grows you may decide to split apart the various responsibilities into different files. eg, contains the `Request and Response types, client.go contains the Client type, server.go
contains the type.
If you find your files have similar import declarations, consider combining them. Alternatively, identify the differences between the import sets and move those
Different files should be responsible for different areas of the package. may be responsible for marshalling of HTTP requests and responses on and off the network, may contain the low level network handling logic, client.go and server.go implement the HTTP business logic of request construction or routing, and so on.
TIP Prefer nouns for source file names.
The Go compiler compiles each package in parallel. Within a package the compiler compiles each NOTE function (methods are just fancy functions in Go) in parallel. Changing the layout of your code within
a package does not affect compilation time.
5.1.2. Prefer internal tests to external tests
The go tool supports writing your testing package tests in two places. Assuming your package is called http2 , you can write a file and use the declaration. Doing so will compile the code in
as if it were part of the package. This is known colloquially as an internal test.
The go tool also supports a special package declaration, ending in test , ie., package http_test . This allows your test files to live alongside your code in the same package, however when those tests are compiled they are not part of your package’s code, they live in their own package. This allows you to write your tests as if you were another package calling into your code. This is known as an _external test.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
I recommend using internal tests when writing unit tests for your package. This allows you to test each function or method directly, avoiding the bureaucracy of external testing.
However, you should place your Example test functions in an external test file. This ensures that when viewed in godoc, the examples have the appropriate package prefix and can be easily copy pasted.
TIP
Avoid elaborate package hierarchies, resist the desire to apply taxonomy
With one exception, which we’ll talk about next, the hierarchy of Go packages has no meaning to the go tool. For example, the net/http package is not a child or sub-package of the net package.
If you find you have created intermediate directories in your project which contain no .go files, you may have failed to follow this advice.
5.1.3. Use internal packages to reduce your public API surface
If your project contains multiple packages you may have some exported functions which are intended to be used by other packages in your project, but are not intended to be part of your project’s public API. If you find yourself in this situation the go tool recognises a special folder name—not package name–, internal/ which can be used to place code which is public to your project, but private to other projects.
To create such a package, place it in a directory named internal/ or in a sub-directory of a directory named internal/ . When the go command sees an import of a package with in its path, it verifies that the
package doing the import is within the tree rooted at the parent of the directory. For example, a package can be imported only by code in the directory tree rooted at …
/a/b/c . It cannot be imported by code in or in any other repository. [5] 5.2. Keep package main small as small as possible
Your main function, and package should do as little as possible. This is because main.main acts as a singleton; there can only be one function in a program, including tests.
Because main.main is a singleton there are a lot of assumptions built into the things that main.main will call that they will only be called during main.main or main.init, and only called once. This makes it hard to write tests for code written in main.main , thus you should aim to move as much of your business logic out of your main function and ideally out of your main package.
TIP
main should parse flags, open connections to databases, loggers, and such, then hand off execution to a high level object.
\6. API Design
The last piece of design advice I’m going to give today I feel is the most important.
All of the suggestions I’ve made so far are just that, suggestions. These are the way I try to write my Go, but I’m not going to push them hard in code review.
However when it comes to reviewing APIs during code review, I am less forgiving. This is because everything I’ve talked about so far can be fixed without breaking backward compatibility; they are, for the most part, implementation details.
When it comes to the public API of a package, it pays to put considerable thought into the initial design, because changing that design later is going to be disruptive for people who are already using your API.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
“6.1. Design APIs that are hard to misuse. APIs should be easy to use and hard to misuse.
— Josh Bloch [3]
If you take anything away from this presentation, it should be this advice from Josh Bloch. If an API is hard to use for simple things, then every invocation of the API will look complicated. When the actual invocation of the API is complicated it will be less obvious and more likely to be overlooked.
6.1.1. Be wary of functions which take several parameters of the same type
A good example of a simple looking, but hard to use correctly API is one which takes two or more parameters of the same type. Let’s compare two function signatures:
What’s the difference between these two functions? Obviously one returns the maximum of two numbers, the other copies a file, but that’s not the important thing.
Max is commutative; the order of the parameters does not matter. The maximum of eight and ten is ten regardless of if I compare eight to ten or ten two eight.
However, this property does not hold true for CopyFile .
Which one of these statements made a backup of your presentation and which one overwrite your presentation with last week’s version? You can’t tell without consulting the documentation. A code reviewer cannot know if you’ve got the order correct without consulting the documentation.
One possible solution to this is to introduce a helper type which will be responsible for calling CopyFile correctly.
1 2 3 4 5 6 7 8 9
func Max(a, b int) int func CopyFile(to, from string) error Max(8, 10) // 10 Max(10, 8) // 10 CopyFile("/tmp/backup", "presentation.md") CopyFile("presentation.md", "/tmp/backup") type Source string func (src Source) CopyTo(dest string) error { return CopyFile(dest, string(src))
}
1 2 3
func main() { var from Source = "presentation.md" from.CopyTo("/tmp/backup")
}
GO
In this way CopyFile is always called correctly—this can be asserted with a unit test—and can possibly be made private, further reducing the likelihood of misuse.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
TIP APIs with multiple parameters of the same type are hard to use correctly. 6.2. Design APIs for their default use case
A few years ago I gave a talk [6] about using functional options [7] to make APIs easier to use for their default case.
The gist of this talk was you should design your APIs for the common use case. Sad another way, your API should not require the caller to provide parameters which they don’t care about.
6.2.1. Discourage the use of nil as a parameter
I opened this chapter with the suggestion that you shouldn’t force the caller of your API into providing you parameters when they don’t really care what those parameters mean. This is what I mean when I say design APIs for their default use case.
Here’s an example from the net/http package
package http
1 2 3 4 5 6 7 8
// ListenAndServe listens on the TCP network address addr and then calls // Serve with handler to handle requests on incoming connections. // Accepted connections are configured to enable TCP keep-alives. // // The handler is typically nil, in which case the DefaultServeMux is used. // // ListenAndServe always returns a non-nil error. func ListenAndServe(addr string, handler Handler) error {
ListenAndServe takes two parameters, a TCP address to listen for incoming connections, and http.Handler to handle the incoming HTTP request. Serve allows the second parameter to be nil , and notes that usually the caller will pass nil indicating that they want to use http.DefaultServeMux as the implicit parameter.
Now the caller of Serve has two ways to do the same thing.
Both do exactly the same thing.
This behaviour is viral. The http package also has a http.Serve helper, which you can reasonably imagine that builds upon like this
Practical Go: Real world advice for writing maintainable Go programs
Because behaviour. In fact,
permits the caller to pass for the second parameter, also supports this is the one that implements the “if is nil , use
for one parameter may lead the caller into thinking they can pass for both parameters. However calling like this,
results in an ugly panic. TIP Don’t mix nil and non nil-able parameters in the same function signature.
The author of was trying to make the API user’s life easier in the common case, but possibly made the package harder to use safely.
There is no difference in line count between using explicitly, or implicitly via .
verses
and a was this confusion really worth saving one line?
TIP
Give serious consideration to how much time helper functions will save the programmer. Clear is better than concise.
Avoid public APIs with test only parameters
TIP Avoid exposing APIs with values who only differ in test scope. Instead, use Public wrappers to hide those parameters, use test scoped helpers to set the property in test scope.
6.2.2. Prefer var args to []T parameters
It’s very common to write a function or method that takes a slice of values.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
This is just an example I made up, but its common to a lot of code I’ve worked on. The problem with signatures like these is they presume that they will be called with more than one entry. However, what I have found is many times these type of functions are called with only one argument, which has to be “boxed” inside a slice just to meet the requirements of the functions signature.
Additionally, because the ids parameter is a slice, you can pass an empty slice or nil to the function and the compiler will be happy. This adds extra testing load because you should cover these cases in your testing.
To give an example of this class of API, recently I was refactoring a piece of logic that required me to set some extra fields if at least one of a set of parameters was non zero. The logic looked like this:
As the if statement was getting very long I wanted to pull the logic of the check out into its own function. This is what I came up with:
1 2 3 4 5 6 7 8
if svc.MaxConnections > 0 || svc.MaxPendingRequests > 0 || svc.MaxRequests > 0 || svc.MaxRetries > 0 { // apply the non zero parameters } // anyPostive indicates if any value is greater than zero. func anyPositive(values ...int) bool { for _, v := range values { if v > 0 {
return true }
}
1 2
return false }
GO
This enabled me to make the condition where the inner block will be executed clear to the reader:
However there is a problem with anyPositive , someone could accidentally invoke it like this if anyPositive() { … }
In this case anyPositive would return false because it would execute zero iterations and immediately return false . This isn’t the worst thing in the world — that would be if anyPositive returned true when passed no
arguments.
Nevertheless it would be be better if we could change the signature of anyPositive to enforce that the caller should pass at least one argument. We can do that by combining normal and vararg parameters like this:
1 2
if anyPositive(svc.MaxConnections, svc.MaxPendingRequests, svc.MaxRequests, svc.MaxRetries) { // apply the non zero parameters
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Now anyPositive cannot be called with less than one argument. 6.3. Let functions dene the behaviour they requires
Let’s say I’ve been given a task to write a function that persists a Document structure to disk.
I could specify this function, Save, which takes an *os.File as the destination to write the Document . But this has a few problems
The signature of Save precludes the option to write the data to a network location. Assuming that network storage is likely to become requirement later, the signature of this function would have to change, impacting all its callers.
Save is also unpleasant to test, because it operates directly with files on disk. So, to verify its operation, the test would have to read the contents of the file after being written.
And I would have to ensure that f was written to a temporary location and always removed afterwards.
os.File also defines a lot of methods which are not relevant to , like reading directories and checking to see if a path is a symlink. It would be useful if the signature of the function could describe only the parts of os.File that were relevant.
What can we do ?
Using io.ReadWriteCloser we can apply the interface segregation principle to redefine Save to take an interface that describes more general file shaped things.
With this change, any type that implements the io.ReadWriteCloser interface can be substituted for the previous *os.File .
This makes Save both broader in its application, and clarifies to the caller of Save which methods of the *os.File type are relevant to its operation.
1 2
// Save writes the contents of doc to the file f. func Save(f *os.File, doc *Document) error
Save
Save
1 2 3 4 5 6 7 8 9 10 11
// Save writes the contents of doc to the supplied // ReadWriterCloser. func Save(rwc io.ReadWriteCloser, doc *Document) error // anyPostive indicates if any value is greater than zero. func anyPositive(first int, rest ...int) bool { if first > 0 { return true } for _, v := range rest { if v > 0 { return true
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
And as the author of I no longer have the option to call those unrelated methods on as it is hidden behind the interface.
But we can take the interface segregation principle a bit further.
Firstly, it is unlikely that if Save follows the single responsibility principle, it will read the file it just wrote to verify its contents—that should be responsibility of another piece of code.
So we can narrow the specification for the interface we pass to Save to just writing and closing. Secondly, by providing Save with a mechanism to close its stream, which we inherited in this desire to make it still
look like a file, this raises the question of under what circumstances will wc be closed. Possibly Save will call Close unconditionally, or perhaps Close will be called in the case of success.
This presents a problem for the caller of Save as it may want to write additional data to the stream after the document is written.
A better solution would be to redefine Save to take only an io.Writer , stripping it completely of the responsibility to do anything but write data to a stream.
By applying the interface segregation principle to our Save function, the results has simultaneously been a function which is the most specific in terms of its requirements—it only needs a thing that is writable—and the most general in its function, we can now use Save to save our data to anything which implements io.Writer.
\7. Error handling
I’ve given several presentations about error handling [8] and written a lot about error handling on my blog. I also spoke a lot about error handling in yesterday’s session so I won’t repeat what I’ve said.
Instead I want to cover two other areas related to error handling.
7.1. Eliminate error handling by eliminating errors
If you were in my presentation yesterday I talked about the draft proposals for improving error handling. But do you know what is better than an improved syntax for handling errors? Not needing to handle errors at all.
Save
*os.File
1 2 3 4 5 6
// Save writes the contents of doc to the supplied // WriteCloser. func Save(wc io.WriteCloser, doc *Document) error // Save writes the contents of doc to the supplied // Writer. func Save(w io.Writer, doc *Document) error
NOTE
I’m not saying “remove your error handling”. What I am suggesting is, change your code so you do not have errors to handle.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
This section draws inspiration from John Ousterhout’s recently book, A philosophy of Software Design [9]. One of the chapters in that book is called “Define Errors Out of Existence”. We’re going to try to apply this advice to Go.
7.1.1. Counting lines
Let’s write a function to count the number of lines in a file.
1 2 3 4 5
func CountLines(r io.Reader) (int, error) { var ( br = bufio.NewReader(r) lines int err error
)
1 2 3 4
for { _, err = br.ReadString('\n') lines++ if err != nil {
break }
}
1 2
if err != io.EOF { return 0, err
}
1 2
return lines, nil }
GO
Because we’re following our advice from previous sections, CountLines takes an io.Reader, not a *File; its the job of the caller to provide the io.Reader who’s contents we want to count.
We construct a bufio.Reader , and then sit in a loop calling the ReadString method, incrementing a counter until we reach the end of the file, then we return the number of lines read.
At least that’s the code we want to write, but instead this function is made more complicated by error handling. For example, there is this strange construction,
We increment the count of lines before checking the error—that looks odd. The reason we have to write it this way is ReadString will return an error if it encounters and end-of-file before
hitting a newline character. This can happen if there is no final newline in the file. To try to fix this, we rearrange the logic to increment the line count, then see if we need to exit the loop.
NOTE this logic still isn’t perfect, can you spot the bug?
1 2 3
_, err = br.ReadString('\n') lines++ if err != nil {
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
But we’re not done checking errors yet. will return when it hits the end of the file. This is expected, needs some way of saying stop, there is nothing more to read. So before we return the error to the caller of , we need to check if the error was not io.EOF , and in that case propagate it up, otherwise we return nil to say that everything worked fine.
I think this is a good example of Russ Cox’s observation that error handling can obscure the operation of the function. Let’s look at an improved version.
This improved version switches from using bufio.Reader to bufio.Scanner .
Under the hood bufio.Scanner uses , but it adds a nice layer of abstraction which helps remove the error handling with obscured the operation of .
1
bufio.Reader
CountLines
NOTE
The method, the body of our
bufio.Scanner can scan for any pattern, but by default it looks for newlines.
returns true if the scanner has matched a line of text and has not encountered an error. So, loop will be called only when there is a line of text in the scanner’s buffer. This means our revised
sc.Scan()
for
CountLines correctly handles the case where there is no trailing newline, and also handles the case where the file was empty.
Secondly, as sc.Scan returns false once an error is encountered, our for loop will exit when the end-of-file is reached or an error is encountered. The type memoises the first error it encountered and we can recover that error once we’ve exited the loop using the method.
Lastly, sc.Err() takes care of handling io.EOF and will convert it to a nil if the end of file was reached without encountering another error.
1
bufio.Scanner
sc.Err()
TIP
When you find yourself faced with overbearing error handling, try to extract some of the operations into a helper type.
7.1.2. WriteResponse
My second example is inspired from the Errors are values blog post [10].
Earlier in this presentation We’ve seen examples dealing with opening, writing and closing files. The error handling is present, but not overwhelming as the operations can be encapsulated in helpers like ioutil.ReadFile and
ioutil.WriteFile . However when dealing with low level network protocols it becomes necessary to build the response directly using I/O primitives the error handling can become repetitive. Consider this fragment of a HTTP server which is constructing the HTTP response.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
First we construct the status line using fmt.Fprintf , and check the error. Then for each header we write the header key and value, checking the error each time. Lastly we terminate the header section with an additional \r\n , check the error, and copy the response body to the client. Finally, although we don’t need to check the error from io.Copy , we need to translate it from the two return value form that io.Copy returns into the single return value that
WriteResponse returns. That’s a lot of repetitive work. But we can make it easier on ourselves by introducing a small wrapper type,
errWriter .
errWriter fulfils the io.Writer contract so it can be used to wrap an existing io.Writer . errWriter passes writes through to its underlying writer until an error is detected. From that point on, it discards any writes and returns the previous error.
1 2
type Header struct { Key, Value string
}
1 2 3 4 5 6 7
type Status struct { Code int Reason string } func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error { _, err := fmt.Fprintf(w, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason) if err != nil {
return err }
1 2 3
for _, h := range headers { _, err := fmt.Fprintf(w, "%s: %s\r\n", h.Key, h.Value) if err != nil {
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Applying errWriter to WriteResponse dramatically improves the clarity of the code. Each of the operations no longer needs to bracket itself with an error check. Reporting the error is moved to the end of the function by inspecting the ew.err field, avoiding the annoying translation from `io.Copy’s return values.
7.2. Only handle an error once
Lastly, I want to mention that you should only handle errors once. Handling an error means inspecting the error value, and making a single decision.
If you make less than one decision, you’re ignoring the error. As we see here, the error from w.WriteAll is being discarded.
But making more than one decision in response to a single error is also problematic. The following is code that I come across frequently.
1 2
// WriteAll writes the contents of buf to the supplied writer. func WriteAll(w io.Writer, buf []byte) {
}
1 2 3
w.Write(buf) type errWriter struct { io.Writer
err error }
1 2 3 4 5 6 7
func (e *errWriter) Write(buf []byte) (int, error) { if e.err != nil { return 0, e.err } var n int n, e.err = e.Writer.Write(buf) return n, nil
}
1 2 3 4 5
func WriteResponse(w io.Writer, st Status, headers []Header, body io.Reader) error { ew := &errWriter{Writer: w} fmt.Fprintf(ew, "HTTP/1.1 %d %s\r\n", st.Code, st.Reason) for _, h := range headers { fmt.Fprintf(ew, "%s: %s\r\n", h.Key, h.Value)
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
In this example if an error occurs during , a line will be written to a log file, noting the file and line that the error occurred, and the error is also returned to the caller, who possibly will log it, and return it, all the way back up to the top of the program.
if err := WriteAll(w, buf); err != nil { log.Println("could not write config: %v", err) return err
}
return nil }
GO
So you get a stack of duplicate lines in your log file,
but at the top of the program you get the original error without any context.
I want to dig into this a little further because I don’t see the problems with logging and returning as just a matter of personal preference.
1 2 3 4 5 6 7 8 9 10 11 12 13
unable to write: io.EOF could not write config: io.EOF err := WriteConfig(f, &conf) fmt.Println(err) // io.EOF func WriteConfig(w io.Writer, conf *Config) error { buf, err := json.Marshal(conf) if err != nil { log.Printf("could not marshal config: %v", err) // oops, forgot to return } if err := WriteAll(w, buf); err != nil { log.Println("could not write config: %v", err) return err
}
return nil }
GO
The problem I see a lot is programmers forgetting to return from an error. As we talked about earlier, Go style is to use guard clauses, checking preconditions as the function progresses and returning early.
In this example the author checked the error, logged it, but forgot to return. This has caused a subtle bug.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
The contract for error handling in Go says that you cannot make any assumptions about the contents of other return values in the presence of an error. As the JSON marshalling failed, the contents of buf are unknown, maybe it contains nothing, but worse it could contain a 1/2 written JSON fragment.
Because the programmer forgot to return after checking and logging the error, the corrupt buffer will be passed to WriteAll , which will probably succeed and so the config file will be written incorrectly. However the function will
return just fine, and the only indication that a problem happened will be a single log line complaining about marshalling JSON, not a failure to write the config.
7.2.1. Adding context to errors
The bug occurred because the author was trying to add context to the error message. They were trying to leave themselves a breadcrumb to point them back to the source of the error.
Let’s look at another way to do the same thing using fmt.Errorf .
1 2 3 4 5 6 7
func WriteConfig(w io.Writer, conf *Config) error { buf, err := json.Marshal(conf) if err != nil { return fmt.Errorf("could not marshal config: %v", err) } if err := WriteAll(w, buf); err != nil { return fmt.Errorf("could not write config: %v", err)
By combining the annotation of the error with returning onto one line there it is harder to forget to return an error and avoid continuing accidentally.
If an I/O error occurs writing the file, the error’s `Error() method will report something like this; could not write config: write failed: input/output error
7.2.2. Wrapping errors with github.com/pkg/errors
The fmt.Errorf pattern works well for annotating the error message, but it does so at the cost of obscuring the type of the original error. I’ve argued that treating errors as opaque values is important to producing software which is loosely coupled, so the face that the type of the original error should not matter if the only thing you do with an error value is
\1. Check that it is not nil . 2. Print or log it.
However there are some cases, I believe they are infrequent, where you do need to recover the original error. In that case you can use something like my errors package to annotate errors like this
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Using the errors package gives you the ability to add context to error values, in a way that is inspectable by both a human and a machine. If you came to my presentation yesterday you’ll know that wrapping is moving into the standard library in an upcoming Go release.
\8. Concurrency
Often Go is chosen for a project because of its concurrency features. The Go team have gone to great lengths to make concurrency in Go cheap (in terms of hardware resources) and performant, however it is possible to use Go’s concurrency features to write code which is neither performent or reliable. With the time I have left I want to leave you with some advice for avoid some of the pitfalls that come with Go’s concurrency features.
Go features first class support for concurrency with channels, and the select and go statements. If you’ve learnt Go formally from a book or training course, you might have noticed that the concurrency section is always one of the last you’ll cover. This workshop is no different, I have chosen to cover concurrency last, as if it is somehow additional to the regular the skills a Go programmer should master.
There is a dichotomy here; Go’s headline feature is our simple, lightweight concurrency model. As a product, our language almost sells itself on this on feature alone. On the other hand, there is a narrative that concurrency isn’t actually that easy to use, otherwise authors wouldn’t make it the last chapter in their book and we wouldn’t look back on our formative efforts with regret.
This section discusses some pitfalls of naive usage of Go’s concurrency features.
8.1. Keep yourself busy or do the work yourself
What is the problem with this program?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
original error: *os.PathError open /Users/dfc/.settings.xml: no such file or directory stack trace: open /Users/dfc/.settings.xml: no such file or directory open failed main.ReadFile /Users/dfc/devel/practical-go/src/errors/readfile2.go:16 main.ReadConfig /Users/dfc/devel/practical-go/src/errors/readfile2.go:29 main.main /Users/dfc/devel/practical-go/src/errors/readfile2.go:35 runtime.main /Users/dfc/go/src/runtime/proc.go:201 runtime.goexit /Users/dfc/go/src/runtime/asm_amd64.s:1333 could not read config
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
The program does what we intended, it serves a simple web server. However it also does something else at the same time, it wastes CPU in an infinite loop. This is because the for{} on the last line of main is going to block the main goroutine because it doesn’t do any IO, wait on a lock, send or receive on a channel, or otherwise communicate with the scheduler.
As the Go runtime is mostly cooperatively scheduled, this program is going to spin fruitlessly on a single CPU, and may eventually end up live-locked.
How could we fix this? Here’s one suggestion.
package main
1 2 3
import ( "fmt" "log"
“net/http”
“runtime” )
1 2 3 4 5 6 7 8
func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintln(w, "Hello, GopherCon SG") }) go func() { if err := http.ListenAndServe(":8080", nil); err != nil { log.Fatal(err) }
}()
1 2
for { runtime.Gosched()
} }
GO
package main
GO
1 2 3
import ( "fmt" "log"
“net/http” )
1 2 3 4 5 6 7 8
func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintln(w, "Hello, GopherCon SG") }) go func() { if err := http.ListenAndServe(":8080", nil); err != nil { log.Fatal(err) }
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
This might look silly, but it’s a common common solution I see in the wild. It’s symptomatic of not understanding the underlying problem.
Now, if you’re a little more experienced with go, you might instead write something like this.
package main
1 2 3
import ( "fmt" "log"
“net/http” )
1 2 3 4 5 6 7 8
func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintln(w, "Hello, GopherCon SG") }) go func() { if err := http.ListenAndServe(":8080", nil); err != nil { log.Fatal(err) }
}()
select {} }
GO
An empty select statement will block forever. This is a useful property because now we’re not spinning a whole CPU just to call runtime.GoSched() . However, we’re only treating the symptom, not the cause.
I want to present to you another solution, one which has hopefully already occurred to you. Rather than run in a goroutine, leaving us with the problem of what to do with the main goroutine, simply run
1 2
http.ListenAndServe http.ListenAndServe
TIP
on the main goroutine itself.
If the main.main function of a Go program returns then the Go program will unconditionally exit no matter what other goroutines started by the program over time are doing.
So this is my first piece of advice: if your goroutine cannot make progress until it gets the result from another, oftentimes it is simpler to just do the work yourself rather than to delegate it.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
This often eliminates a lot of state tracking and channel manipulation required to plumb a result back from a goroutine to its initiator.
TIP
Many Go programmers overuse goroutines, especially when they are starting out. As with all things in life, moderation is the key the key to success.
8.2. Leave concurrency to the caller
What is the difference between these two APIs?
1 2 3 4 5 6
// ListDirectory returns the contents of dir. func ListDirectory(dir string) ([]string, error) // ListDirectory returns a channel over which // directory entries will be published. When the list // of entries is exhausted, the channel will be closed. func ListDirectory(dir string) chan string
Firstly, the obvious differences; the first example reads a directory into a slice then returns the whole slice, or an error if something went wrong. This happens synchronously, the caller of ListDirectory blocks until all directory entries have been read. Depending on how large the directory, this could take a long time, and could potentially allocate a lot of memory building up the slide of directory entry names.
Lets look at the second example. This is a little more Go like, ListDirectory returns a channel over which directory entries will be passed. When the channel is closed, that is your indication that there are no more directory entries. As the population of the channel happens after ListDirectory returns, ListDirectory is probably starting a goroutine to populate the channel.
NOTE
Its not necessary for the second version to actually use a Go routine; it could allocate a channel sufficient to hold all the directory entries without blocking, fill the channel, close it, then return the channel to the caller. But this is unlikely, as this would have the same problems with consuming a large amount of memory to buffer all the results in a channel.
The channel version of ListDirectory has two further problems:
By using a closed channel as the signal that there are no more items to process there is no way for ListDirectory to tell the caller that the set of items returned over the channel is incomplete because an error was encountered partway through. There is no way for the caller to tell the difference between an empty directory and an error to read from the directory entirely. Both result in a channel returned from ListDirectory which appears to be closed immediately.
The caller must continue to read from the channel until it is closed because that is the only way the caller can know that the goroutine which was started to fill the channel has stopped. This is a serious limitation on the use of
ListDirectory , the caller has to spend time reading from the channel even though it may have received the answer it wanted. It is probably more efficient in terms of memory usage for medium to large directories, but this method is no faster than the original slice based method.
The solution to the problems of both implementations is to use a callback, a function that is called in the context of each directory entry as it is executed.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Not surprisingly this is how the filepath.WalkDir function works.
If your function starts a goroutine you must provide the caller with a way to explicitly stop that TIP goroutine. It is often easier to leave decision to execute a function asynchronously to the caller of
that function.
8.3. Never start a goroutine without when it will stop.
The previous example showed using a goroutine when one wasn’t really necessary. But one of the driving reasons for using Go is the first class concurrency features the language offers. Indeed there are many instances where you want to exploit the parallelism available in your hardware. To do so, you must use goroutines.
This simple application serves http traffic on two different ports, port 8080 for application traffic and port 8001 for access to the /debug/pprof endpoint.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
By breaking the serveApp and serveDebug handlers out into their own functions we’ve decoupled them from main.main . We’ve also followed the advice from above and make sure that serveApp and serveDebug leave their
concurrency to the caller.
But there are some operability problems with this program. If serveApp returns then main.main will return causing the program to shutdown and be restarted by whatever process manager you’re using.
TIP
Just as functions in Go leave concurrency to the caller, applications should leave the job of monitoring their status and restarting them if they fail to the program that invoked them. Do not make your applications responsible for restarting themselves, this is a procedure best handled from outside the application.
However, serveDebug is run in a separate goroutine and if it returns just that goroutine will exit while the rest of the program continues on. Your operations staff will not be happy to find that they cannot get the statistics out of your application when they want too because the /debug handler stopped working a long time ago.
What we want to ensure is that if any of the goroutines responsible for serving this application stop, we shut down the application.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Now serverApp and serveDebug check the error returned from ListenAndServe and call if required. Because both handlers are running in goroutines, we park the main goroutine in a .
This approach has a number of problems:
\1. If ListenAndServer returns with a nil error, log.Fatal won’t be called and the HTTP service on that port will shut down without stopping the application.
\2. log.Fatal calls os.Exit which will unconditionally exit the program; defers won’t be called, other goroutines won’t be notified to shut down, the program will just stop. This makes it difficult to write tests for those functions.
TIP Only use log.Fatal from main.main or init functions.
What we’d really like is to pass any error that occurs back to the originator of the goroutine so that it can know why the goroutine stopped, can shut down the process cleanly.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
We can use a channel to collect the return status of the goroutine. The size of the channel is equal to the number of goroutines we want to manage so that sending to the done channel will not block, as this will block the shutdown the of goroutine, causing it to leak.
As there is no way to safely close the done channel we cannot use the for range idiom to loop of the channel until all goroutines have reported in, instead we loop for as many goroutines we started, which is equal to the capacity of the channel.
Now we have a way to wait for each goroutine to exit cleanly and log any error they encounter. All that is needed is a way to forward the shutdown signal from the first goroutine that exits to the others.
It turns out that asking a http.Server to shut down is a little involved, so I’ve spun that logic out into a helper function. The serve helper takes an address and http.Handler , similar to http.ListenAndServe , and also a stop channel which we use to trigger the Shutdown method.
2018/10/21 Practical Go: Real world advice for writing maintainable Go programs
Now, each time we receive a value on the channel, we close the stop channel which causes all the goroutines waiting on that channel to shut down their . This in turn will cause all the remaining ListenAndServe goroutines to return. Once all the goroutines we started have stopped, main.main returns and the process stops cleanly.
done
http.Server
TIP
Writing this logic yourself is repetitive and subtle. Consider something like this package, https://github.com/heptio/workgroup which will do most of the work for you.
]]>
对于《图解HTTP》一书进行言简意赅的总结
python apscheduler - skipped: maximum number of running instances reachedhttps://cloudsjhan.github.io/2018/09/28/python-apscheduler-skipped-maximum-number-of-running-instances-reached/2018-09-28T08:04:43.000Z2018-09-28T08:14:25.410Z
WARNING:apscheduler.scheduler:Execution of job "runsync (trigger: interval[0:00:01], next run at: 2015-12-01 11:50:42 UTC)" skipped: maximum number of running instances reached (1)
分析
apscheduler这个模块,在你的代码运行时间大于interval的时候,就会报错
也就是说,你的代码运行时间超出了你的定时任务的时间间隔。
解决
增大时间间隔即可
###
]]>
python apscheduler - skipped: maximum number of running instances reached
python 的logging模块实现json格式的日志输出https://cloudsjhan.github.io/2018/09/27/python-的logging模块实现json格式的日志输出/2018-09-27T08:28:21.000Z2018-09-29T01:14:39.201Z
ping 命令是基于 ICMP 协议来工作的,「 ICMP 」全称为 Internet 控制报文协议( Internet Control Message Protocol)。ping 命令会发送一份ICMP回显请求报文给目标主机,并等待目标主机返回ICMP回显应答。因为ICMP协议会要求目标主机在收到消息之后,必须返回ICMP应答消息给源主机,如果源主机在一定时间内收到了目标主机的应答,则表明两台主机之间网络是可达的。
今天在CentOS下安装docker-compose,遇到了Cannot uninstall ‘requests’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. 错误的原因是requests默认版本为2.6.0,但是docker-compose要2.9以上才支持,但是无法正常卸载2.9版本,是pip10对包的管理存在变化。
解决方案:
pip install -l requests==2.9
]]>
CentOS下安装Docker-compose时出现了 Cannot uninstall 'requests'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
技术周刊之解析Python中的赋值、浅拷贝、深拷贝https://cloudsjhan.github.io/2018/09/09/技术周刊之解析Python中的赋值、浅拷贝、深拷贝/2018-09-09T06:39:05.000Z2018-09-09T08:03:48.727Z
]]>
常用的Python模块,即查即用
Mysql无法连接[MySql Host is blocked because of many connection errors]https://cloudsjhan.github.io/2018/09/01/Mysql无法连接/2018-09-01T05:20:54.000Z2018-09-01T05:38:58.657Z
测试环境,发现数据库(MySQL数据库)无法登录,报错如下:
Host is blocked because of many connection errors; unblock with ‘mysqladmin flush-hosts’
]]>
mysql 出现[MySql Host is blocked because of many connection errors]的错误
mysql 开启远程连接https://cloudsjhan.github.io/2018/08/29/mysql-开启远程连接/2018-08-29T03:17:20.000Z2018-09-01T05:35:43.913Z
]]>
<p class="description"></p>
<p><img src="https://" alt="" style="width:100%"></p>
Mac os 环境配置ruby on rails 及其Hello worldhttps://cloudsjhan.github.io/2018/08/26/Mac-os-配置-ruby-on-rails-md/2018-08-26T15:20:33.000Z2018-08-27T15:39:24.975Z
今天在Mac OS环境中倒腾ruby on rails,遇到一些坑并排坑后总结一个搭建过程,供大家参考。
大纲
本着IT届能用最新的就不用前面的版本的宗旨,在进行之前必须将你的Mac升级到最新的macOS High Sierra
安装 XCode Command Line Tools
配置Git
安装Homebrew
安装GPG
安装RVM
安装ruby
升级RubyGems
安装rails
基本MVC探究之Hello world
Ruby On rails for mac os High Sierra
Mac OS是自带ruby的,但是这些ruby的版本都不是最新的,我们也不要用这些过时的版本
首先,升级你的Mac OS到10.13
查看是否安装xcode command line tool:
1 2 3 4
$:xcode-select -p 如果你看到: xcode-select: error: unable to get active developer directory... 说明你没有安装xcode command line tool,需要按照下面的步骤安装。
1 2 3
如果你看到: $:/Applications/Xcode.app/Contents/Developer 或者/Library/Developer/CommandLineTools 恭喜你,xcode command line tool你已经安装好了
1 2 3
But,如果你很不幸运地看到了这句话: $: /Applications/Apple Dev Tools/Xcode.app/Contents/Developer 那么你就要卸掉xcode重新安装了,具体原因看
// Prepare the command to execute. cmd := exec.Command(args[0], args[1:]...)
// Set the correct output device. cmd.Stderr = os.Stderr cmd.Stdout = os.Stdout
// Execute the command and save it's output. err := cmd.Run() if err != nil { return err } returnnil }
1 2
//执行并测试 go run main.go
暂时不支持tab键自动补全命令,只是提供一种简单的思路。
]]>
使用go实现UNIX环境下的命令行工具
iterm2 突然报很奇怪的错误-Error No user exists for uid 501https://cloudsjhan.github.io/2018/08/21/iterm2-strange-err-md-md/2018-08-21T15:18:21.000Z2018-08-21T15:33:12.206Z
1 2 3
No user exists for uid 501 fatal: Could not read from remote repository. Please make sure you have the correct access rightsand the repository exists.
上午还好好的,刚刚连接GitHub报这个错误,排查后了解到是iterm2的神坑。
重启iterm终端就好 系统有更新的话 需要重启终端 更新。
]]>
iterm2 突然报很奇怪的错误-Error No user exists for uid 501
golang中interface的通用设计方法https://cloudsjhan.github.io/2018/08/21/golang通用接口设计方法/2018-08-21T14:18:58.000Z2018-08-21T15:10:30.131Zgolang中接口设计的通用方法
]]>
golang中interface的通用设计方法
python3中遇到'TypeError Unicode-objects must be encoded before hashing'https://cloudsjhan.github.io/2018/08/20/python-md5-err-md/2018-08-20T14:18:58.000Z2018-09-28T02:06:52.282ZPython3中进行MD5加密,遇到编码问题
]]>
Python中进行md5加密时遇到的编码问题
Hello Worldhttps://cloudsjhan.github.io/2018/08/18/hello-world/2018-08-18T14:05:08.000Z2018-08-18T14:05:08.000ZWelcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.




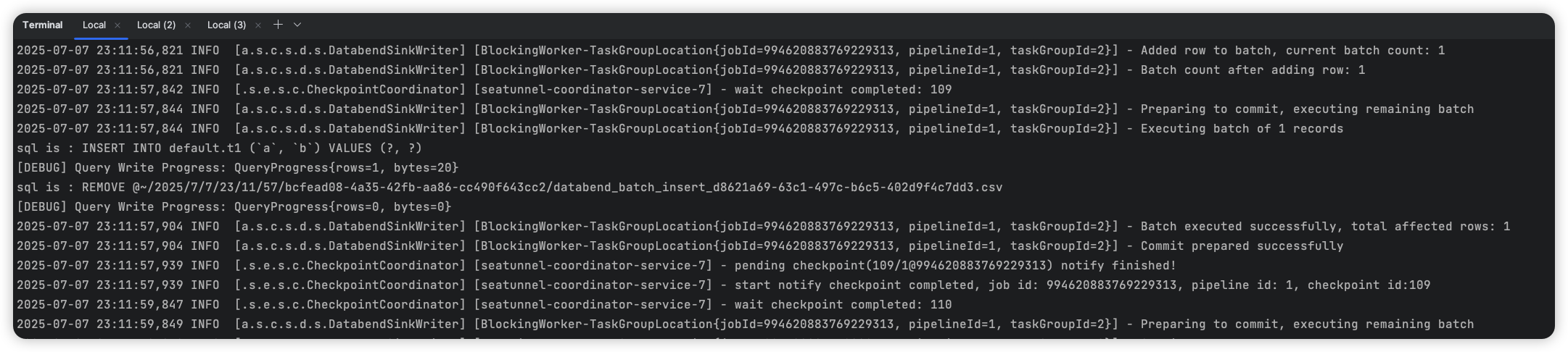
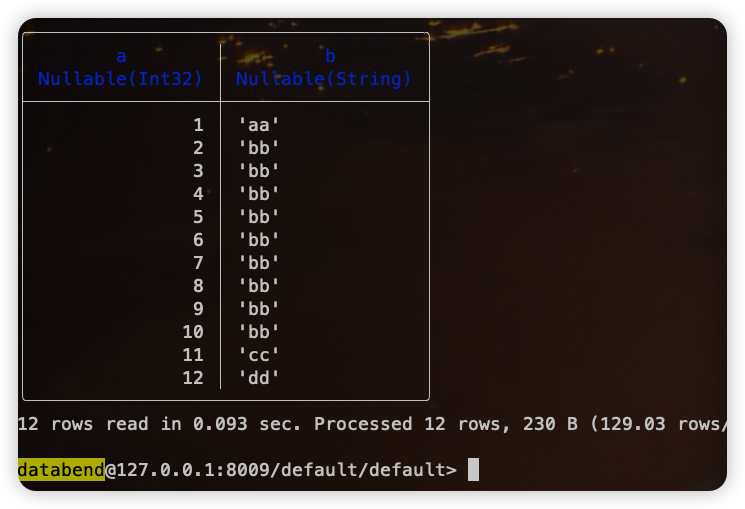






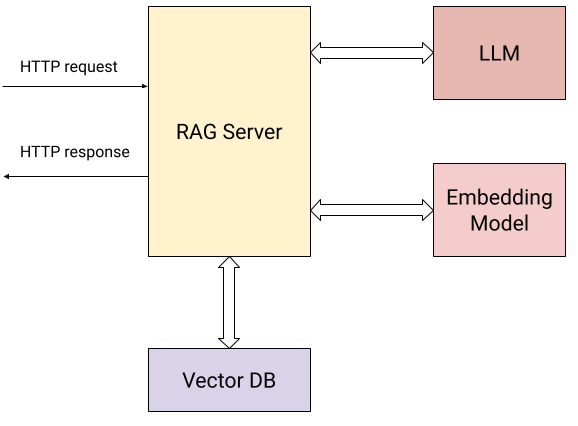


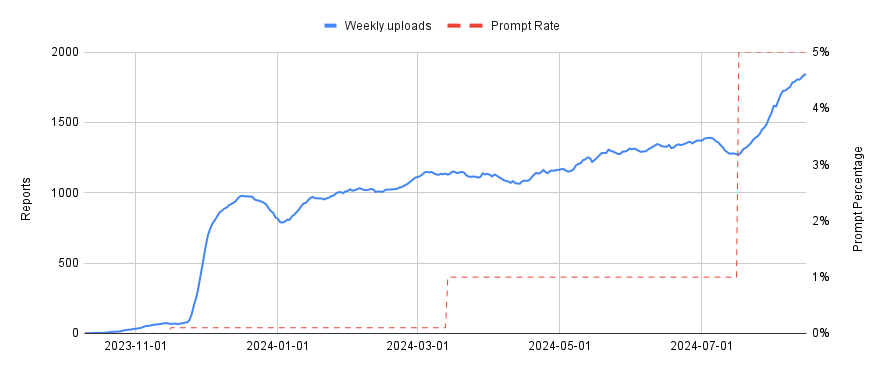
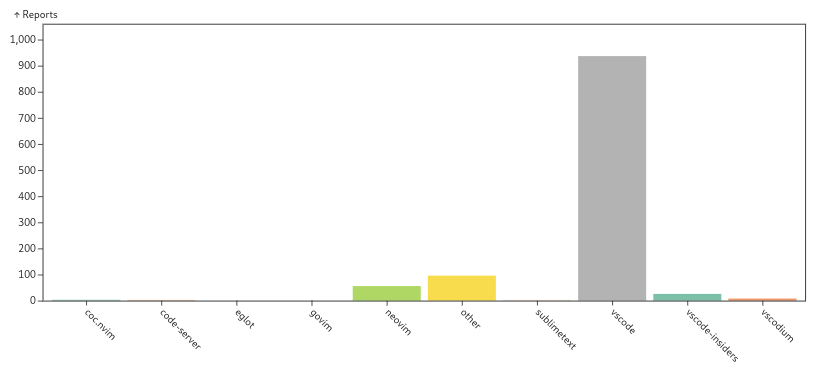






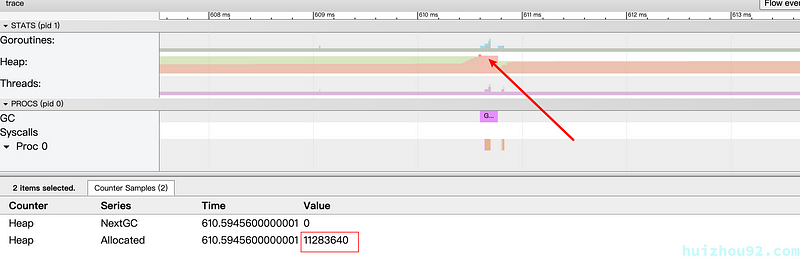
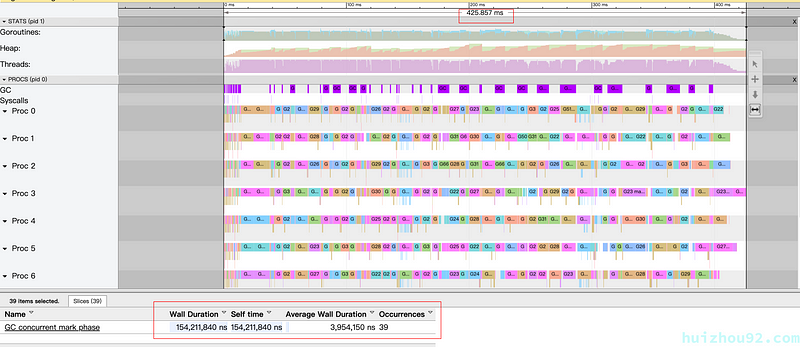

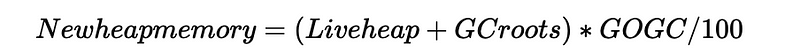
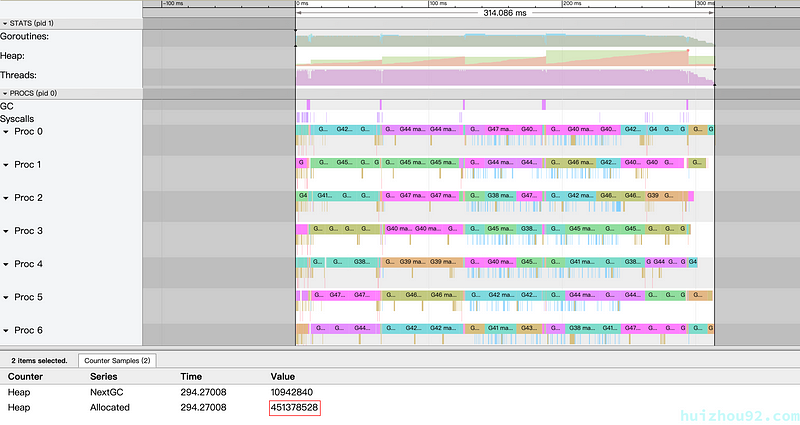


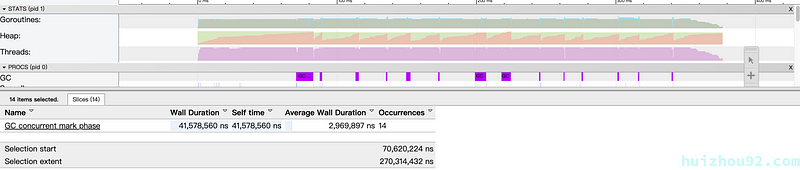
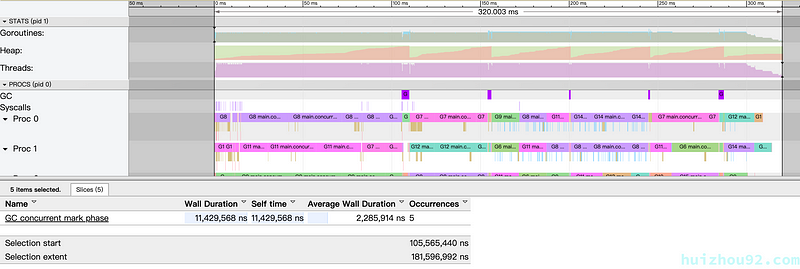


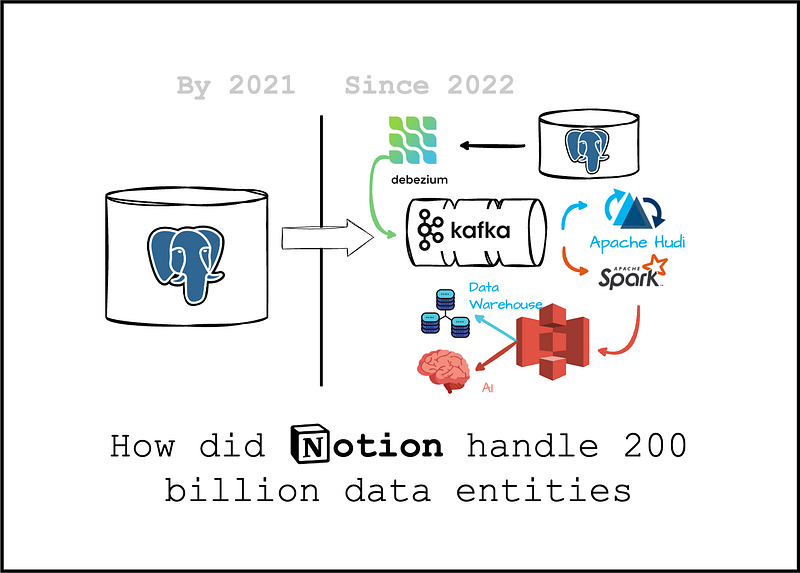
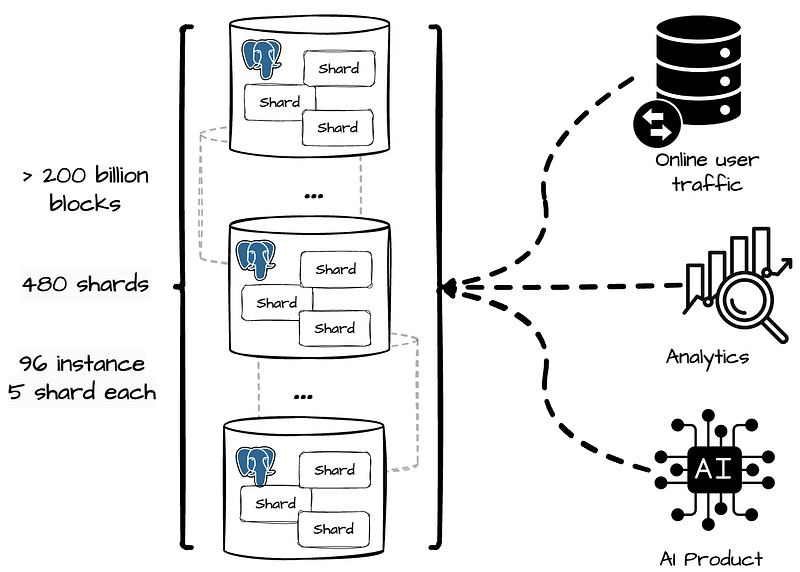
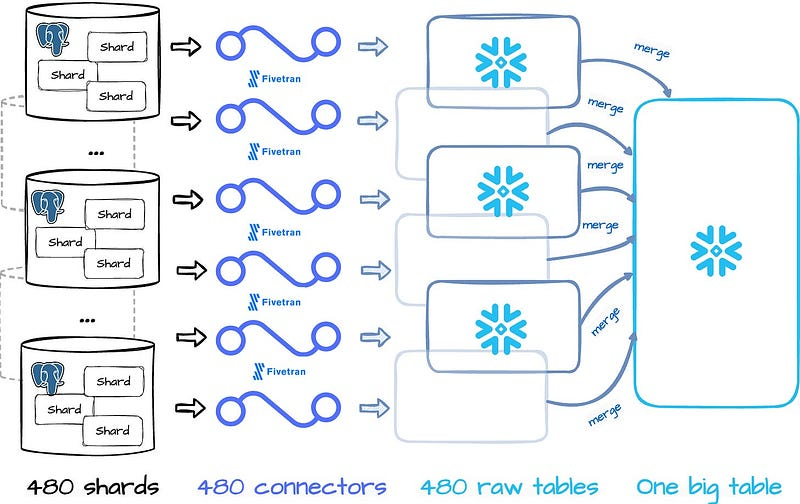
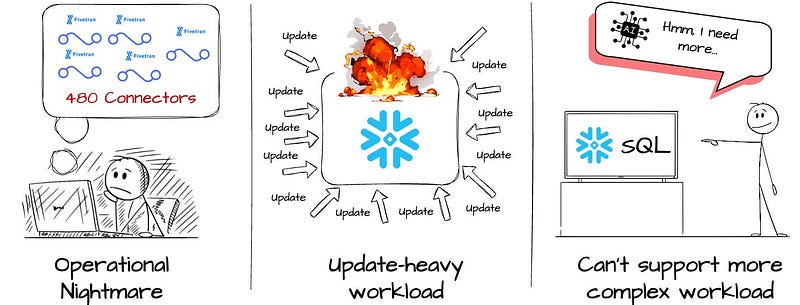
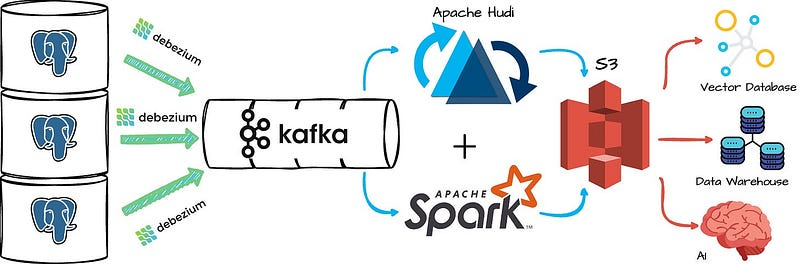
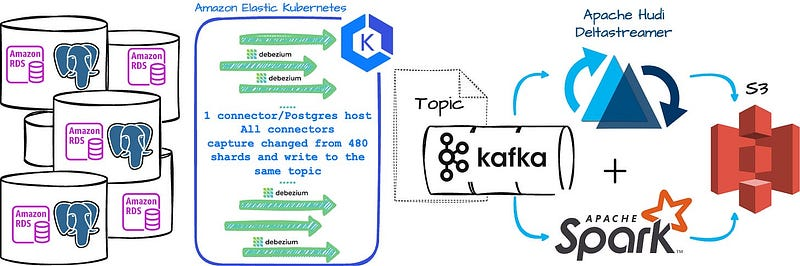








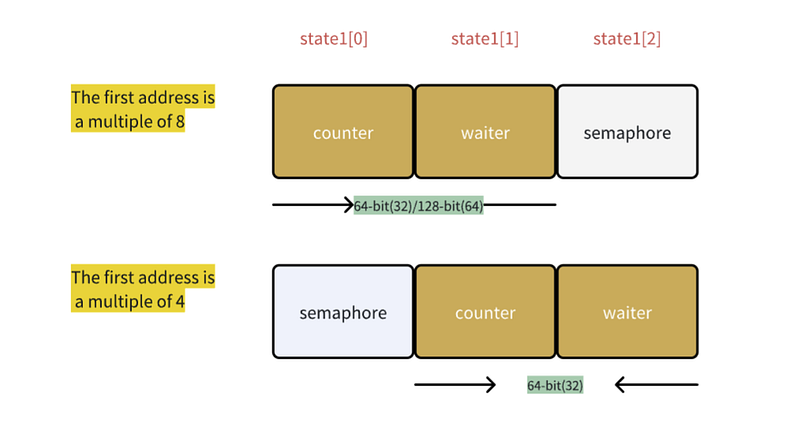

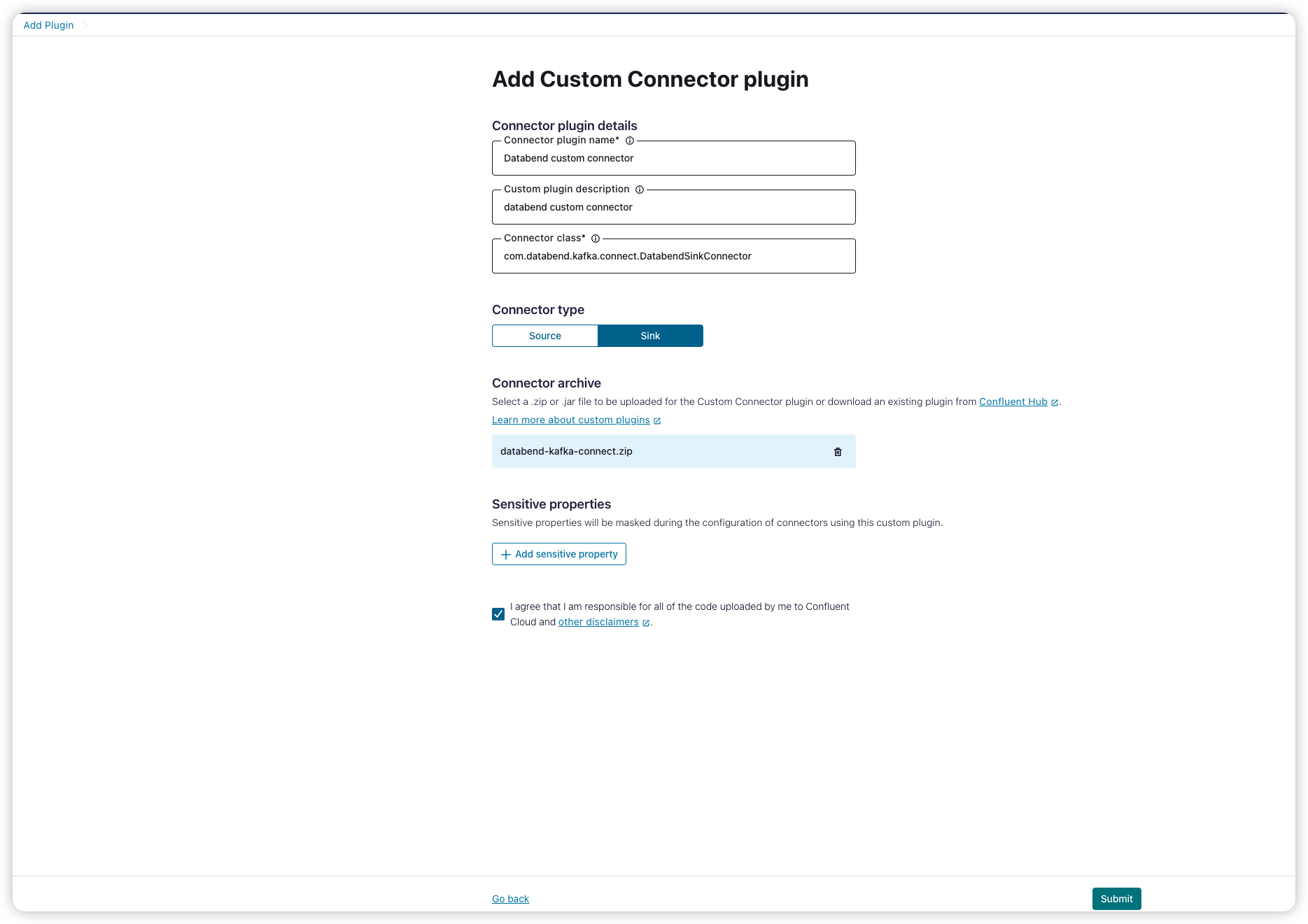

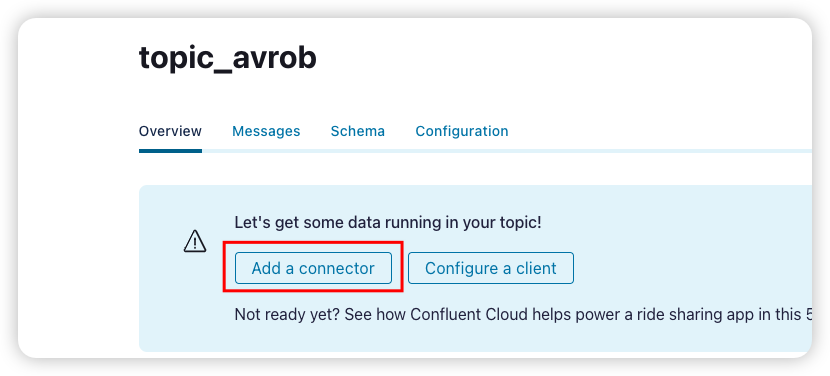
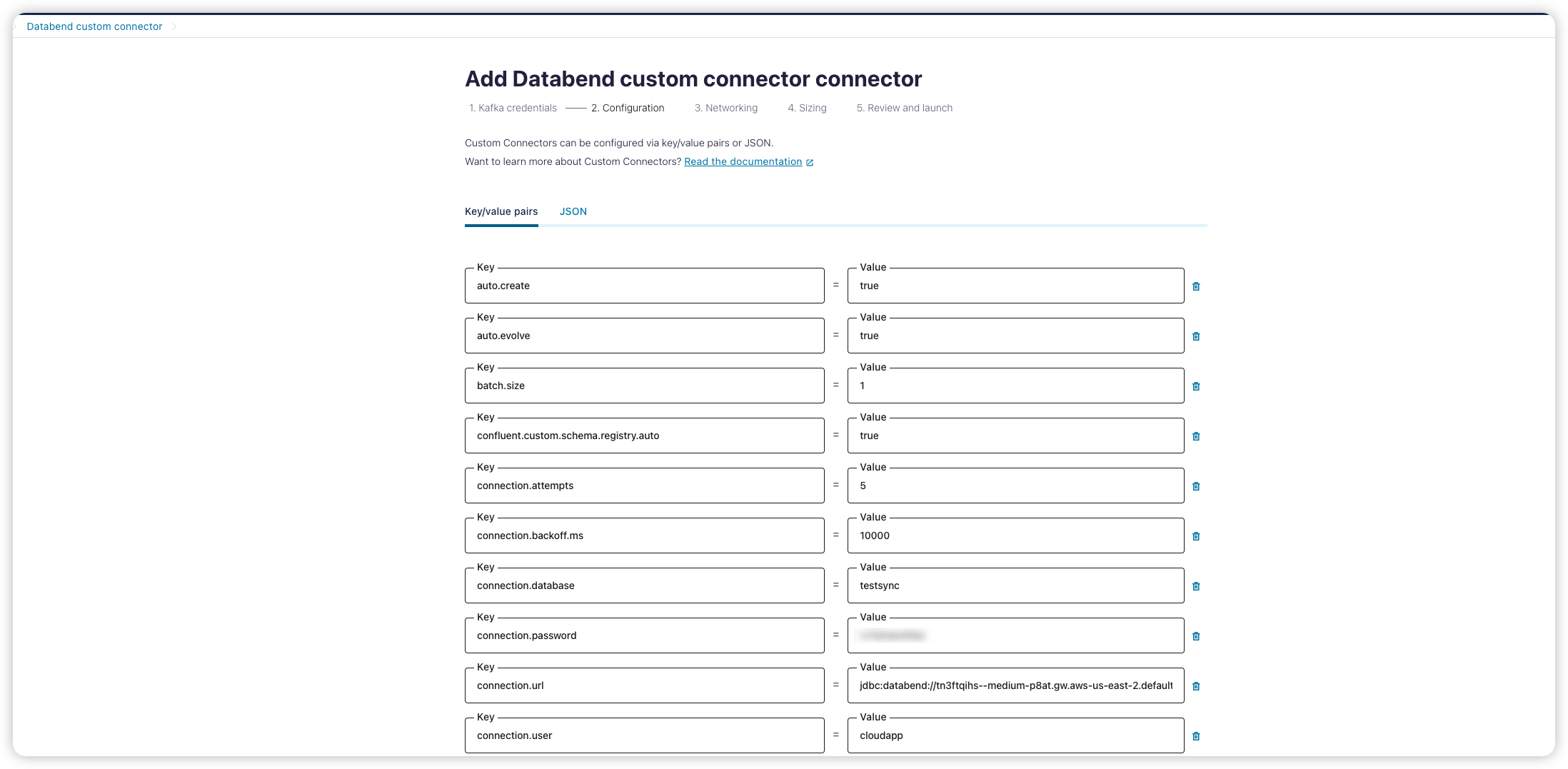
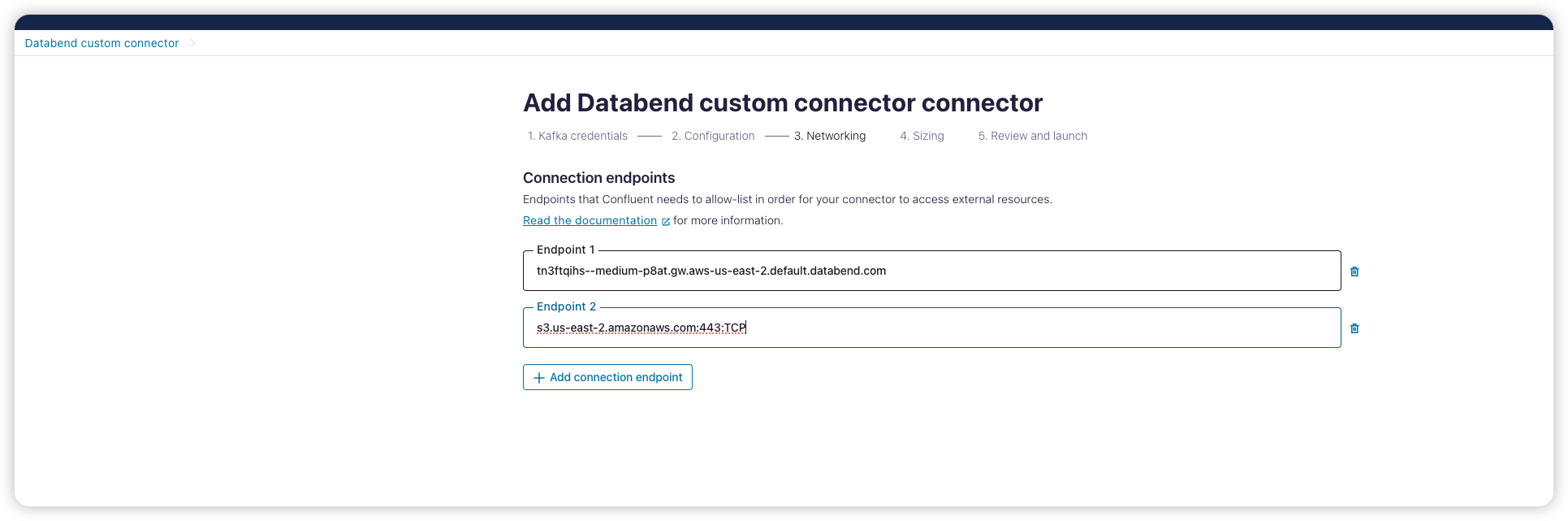
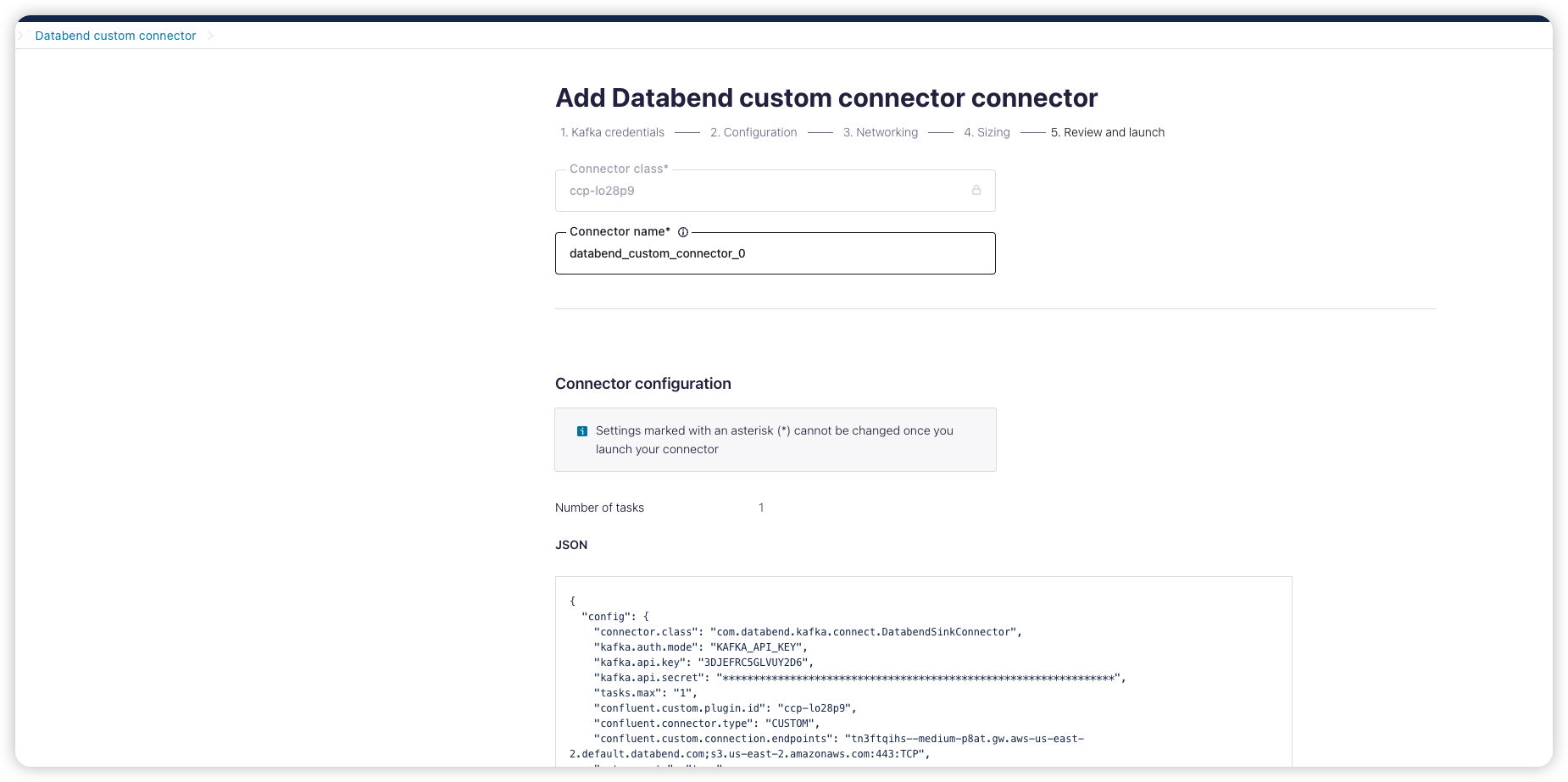


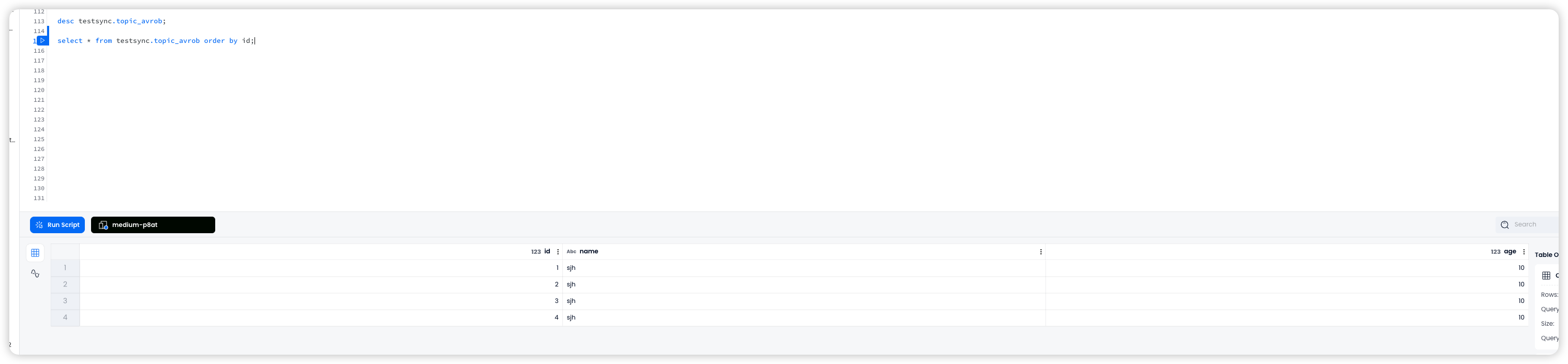
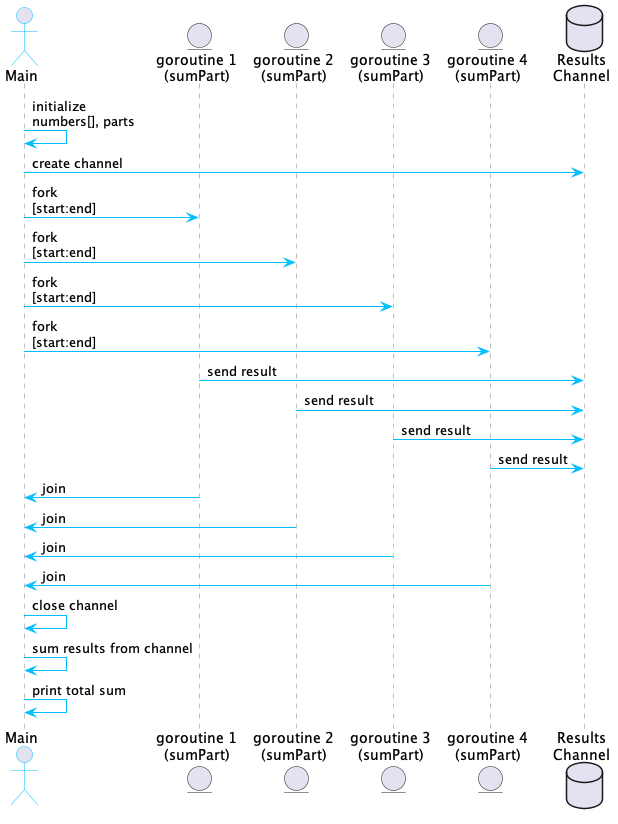
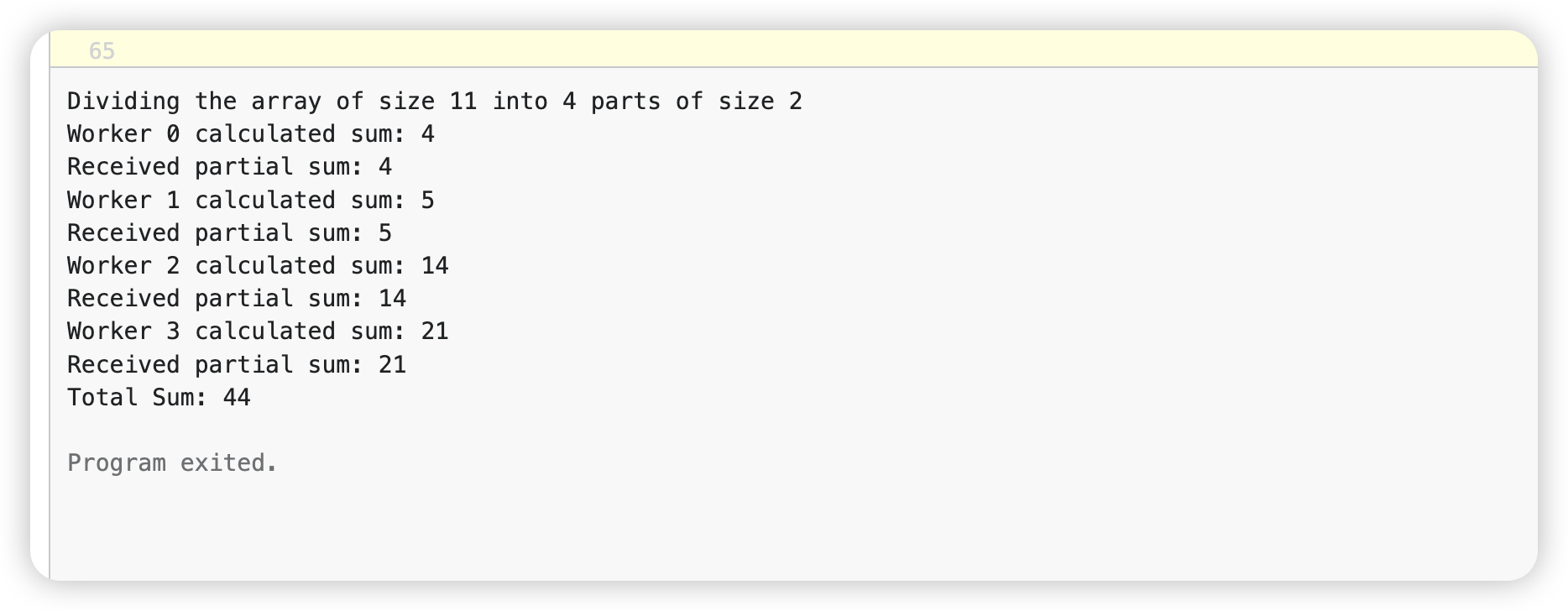





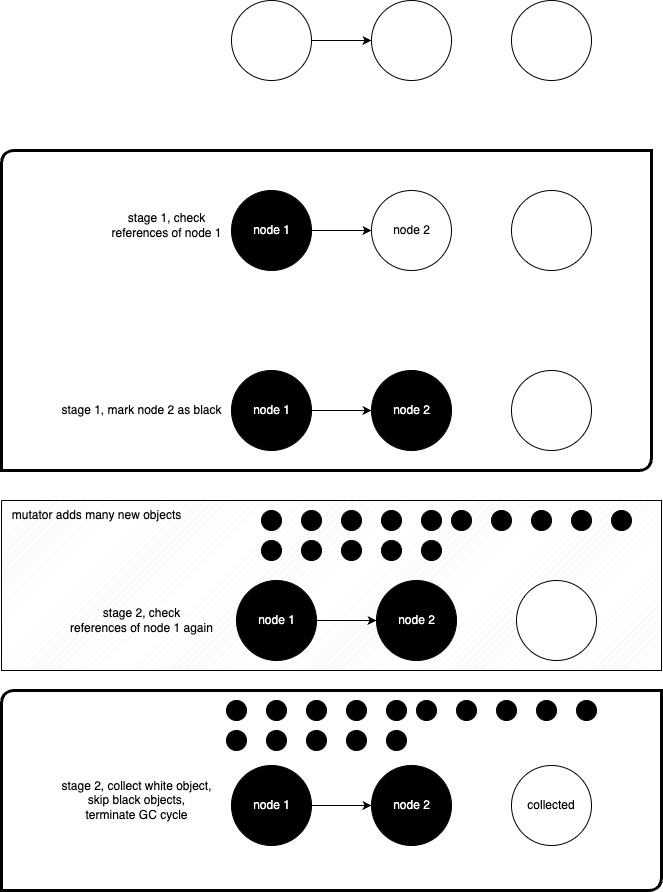
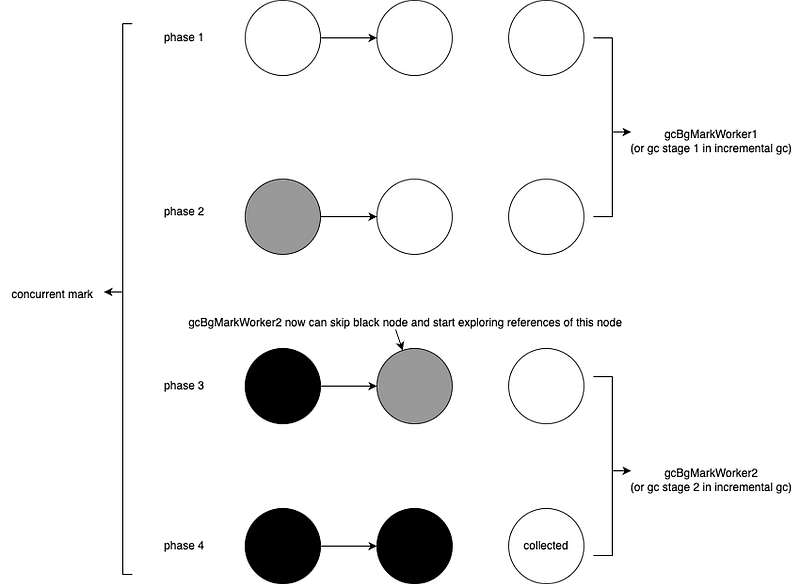
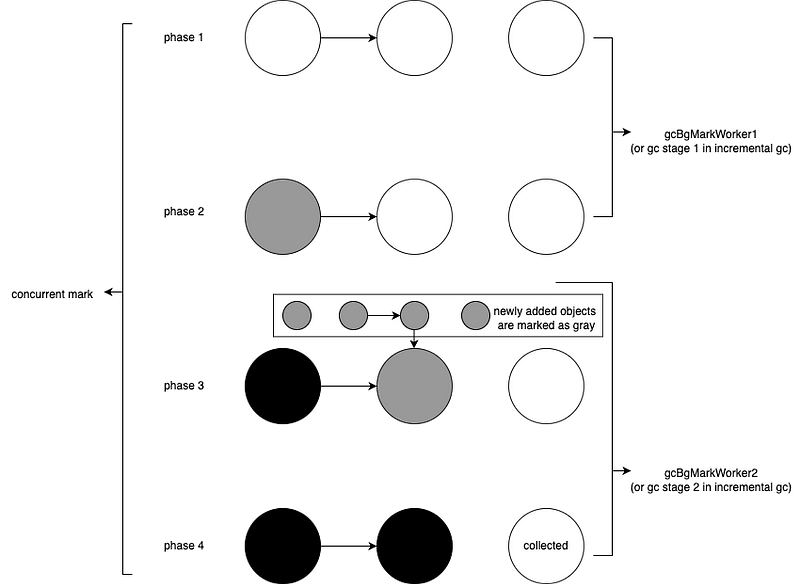
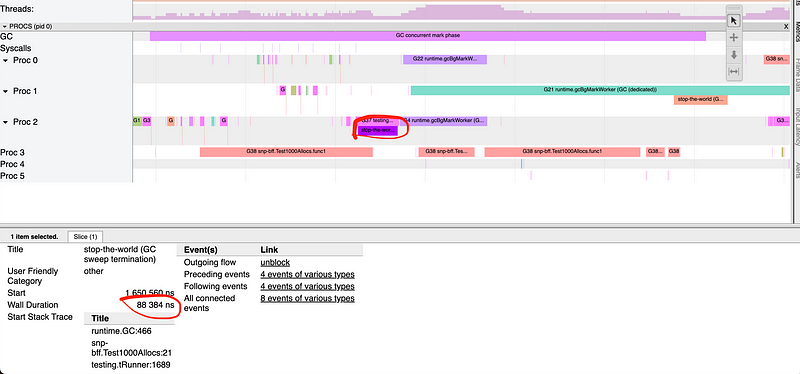
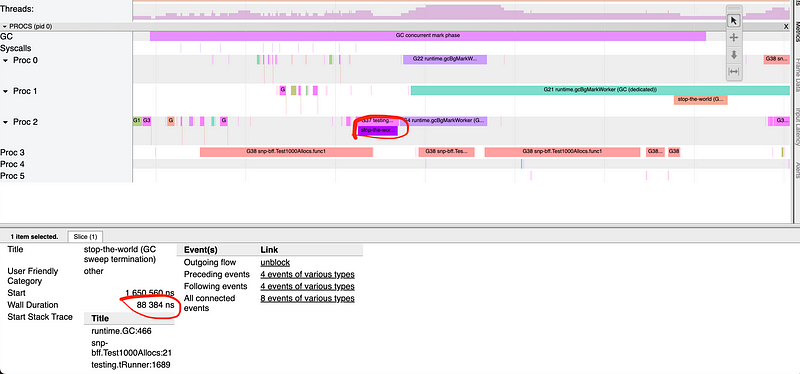
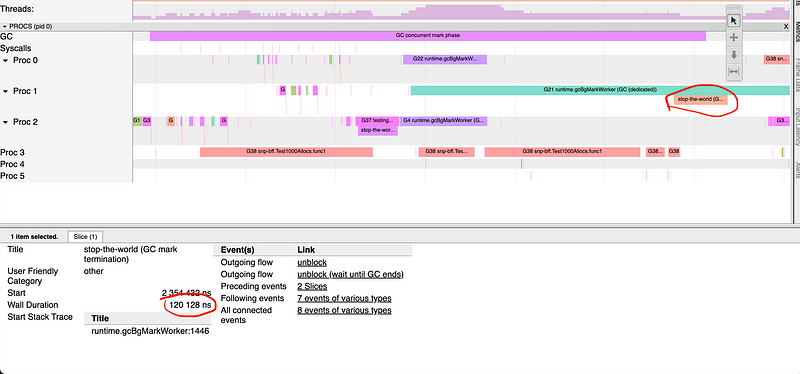
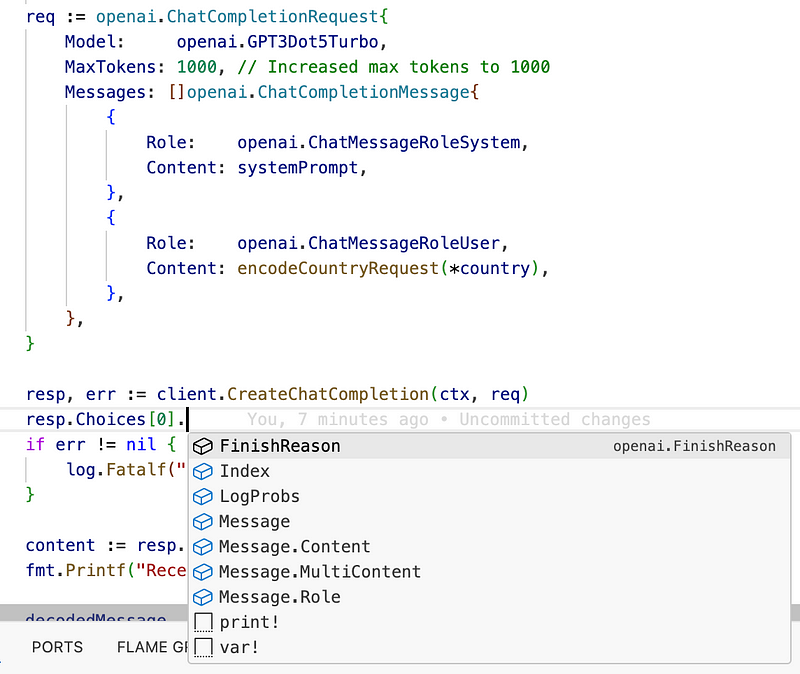





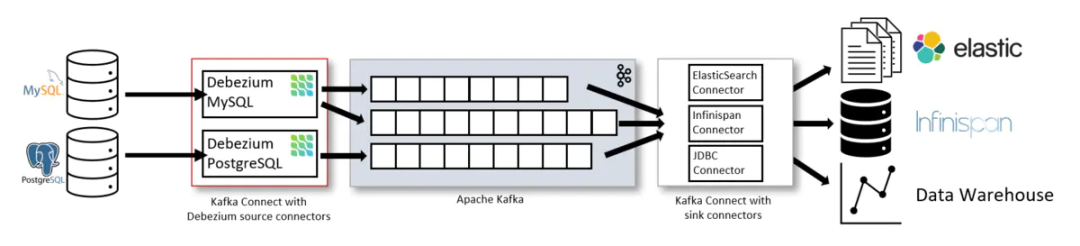
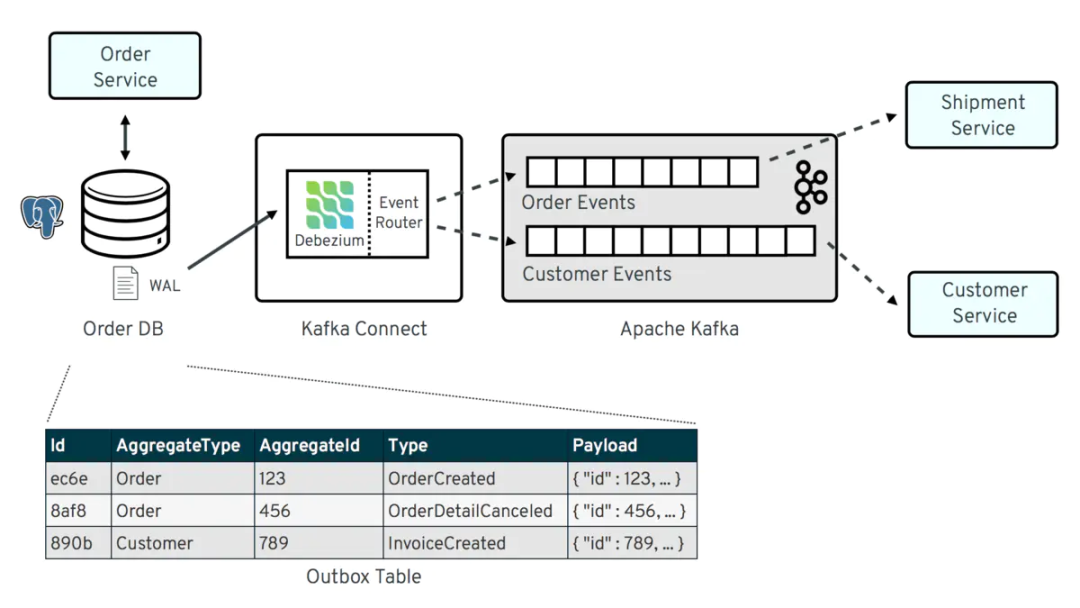
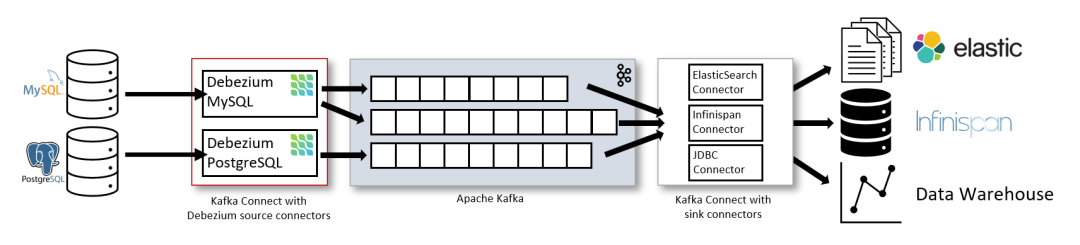

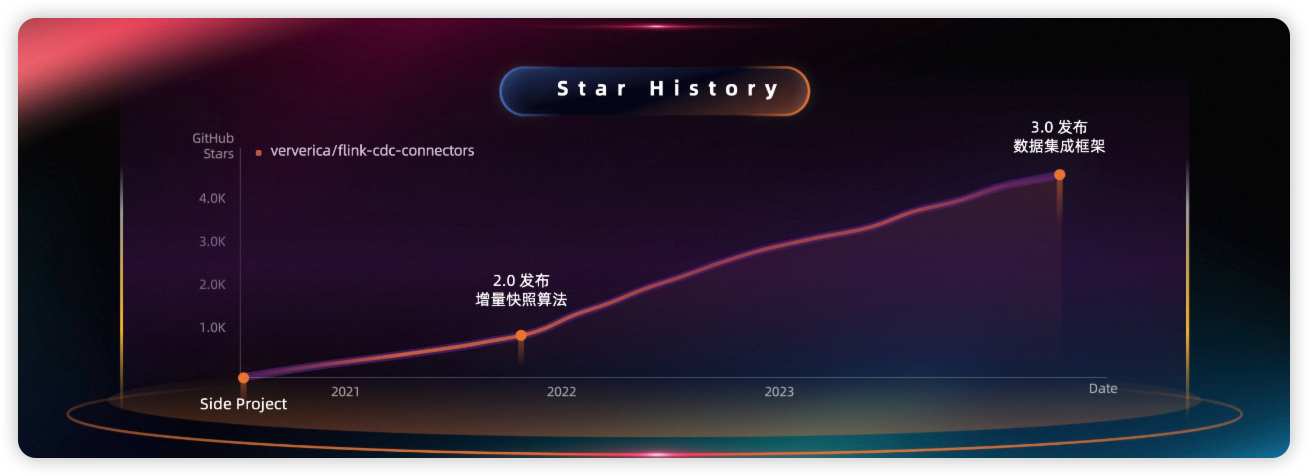
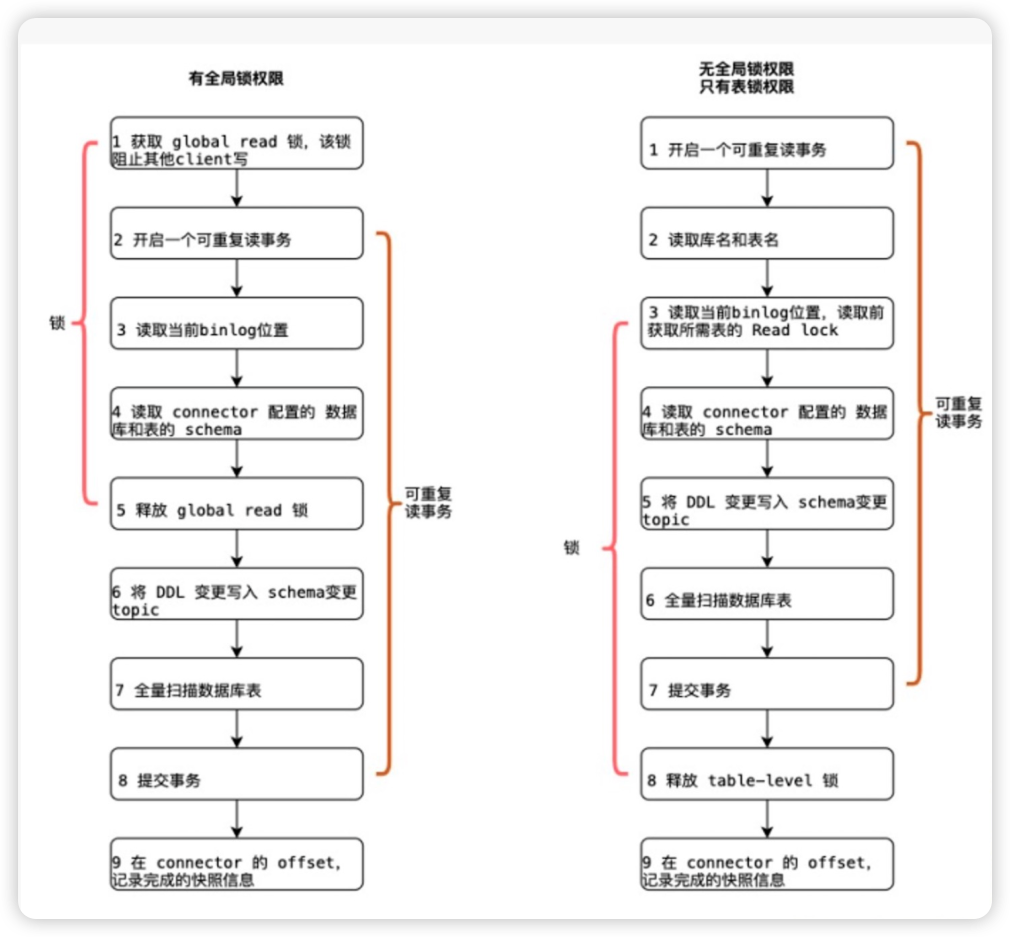
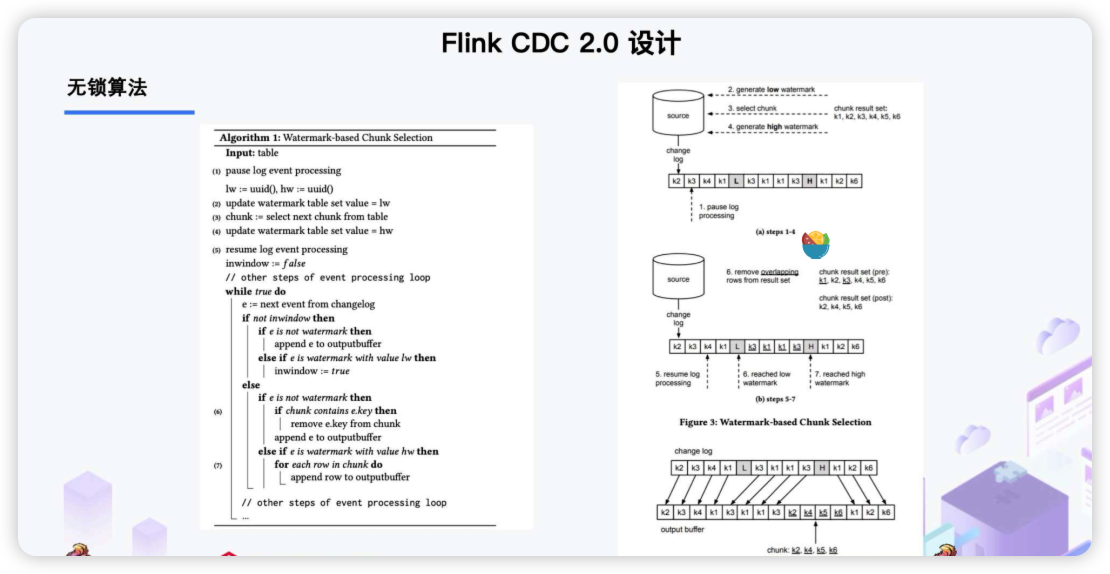
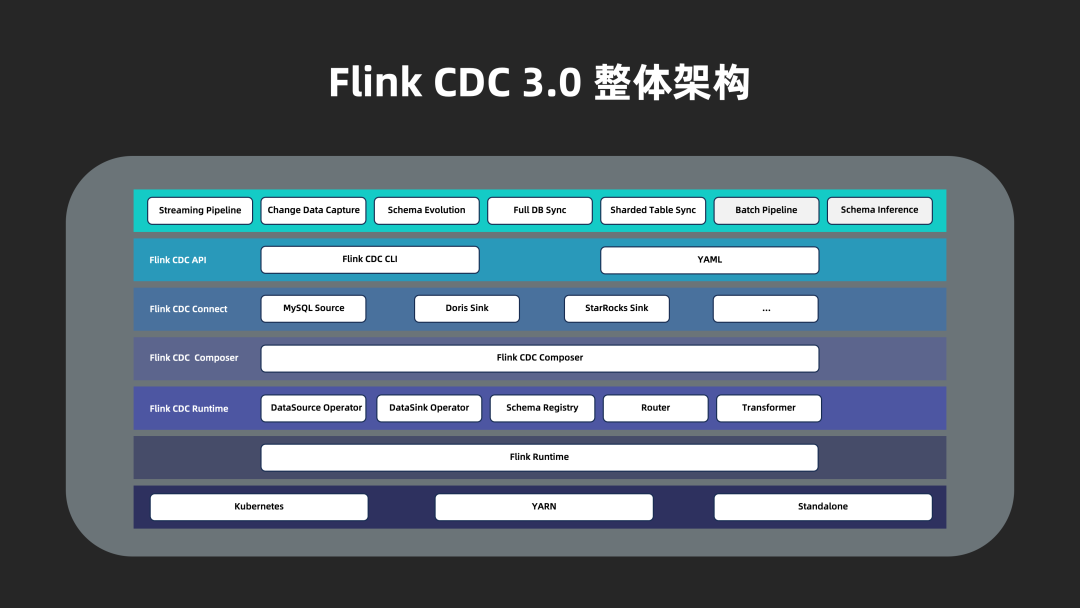
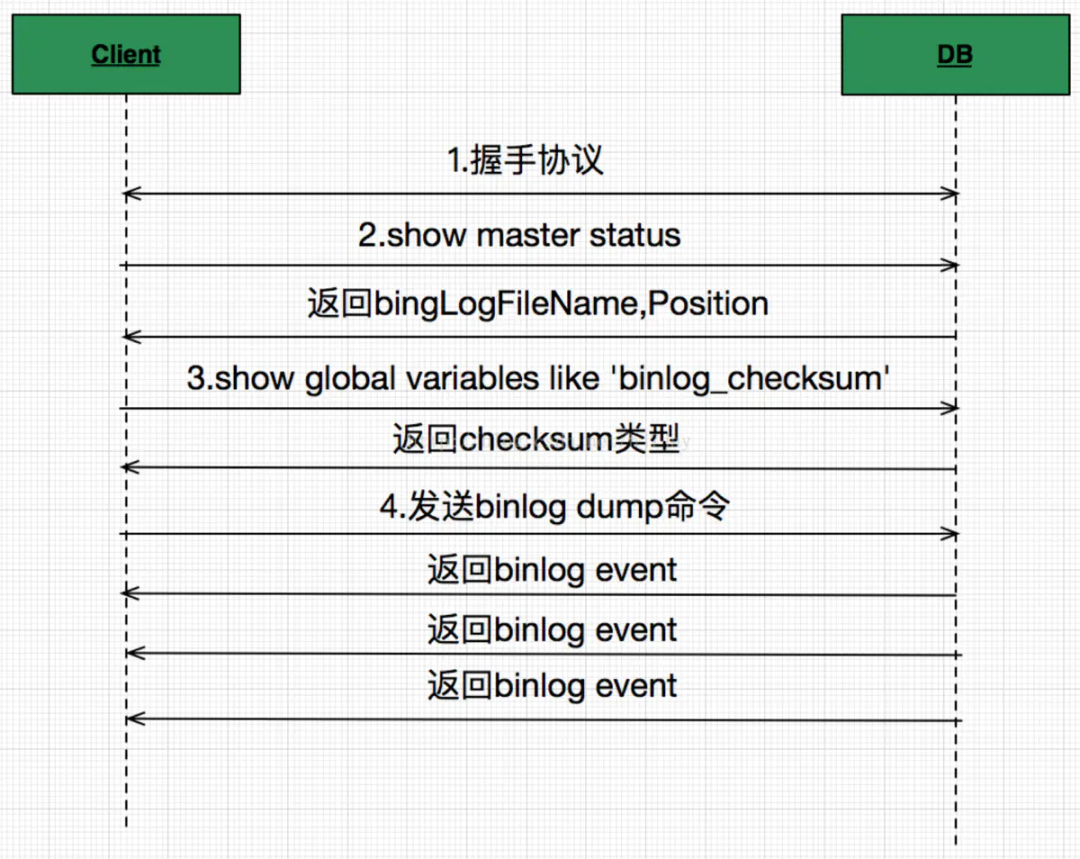

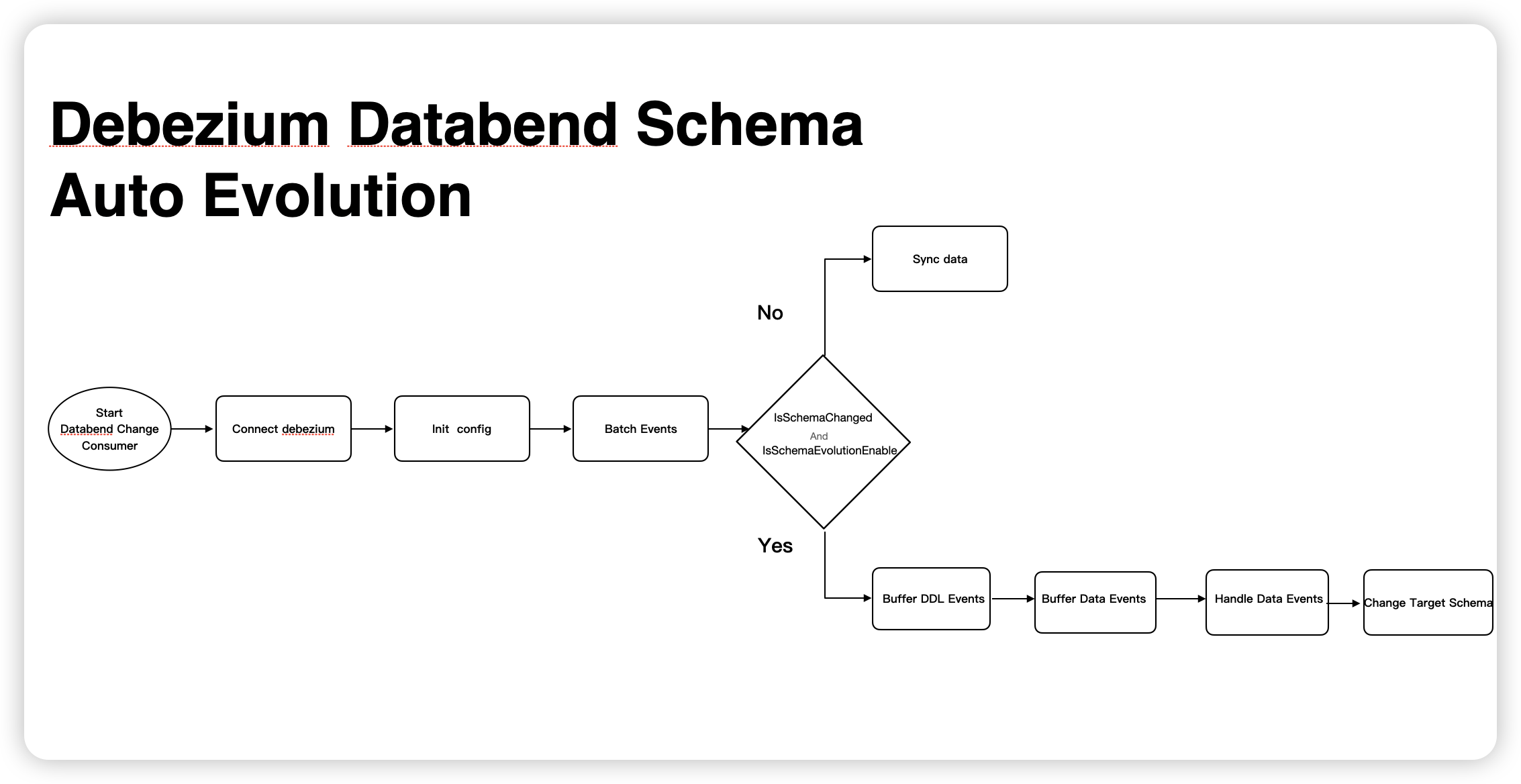
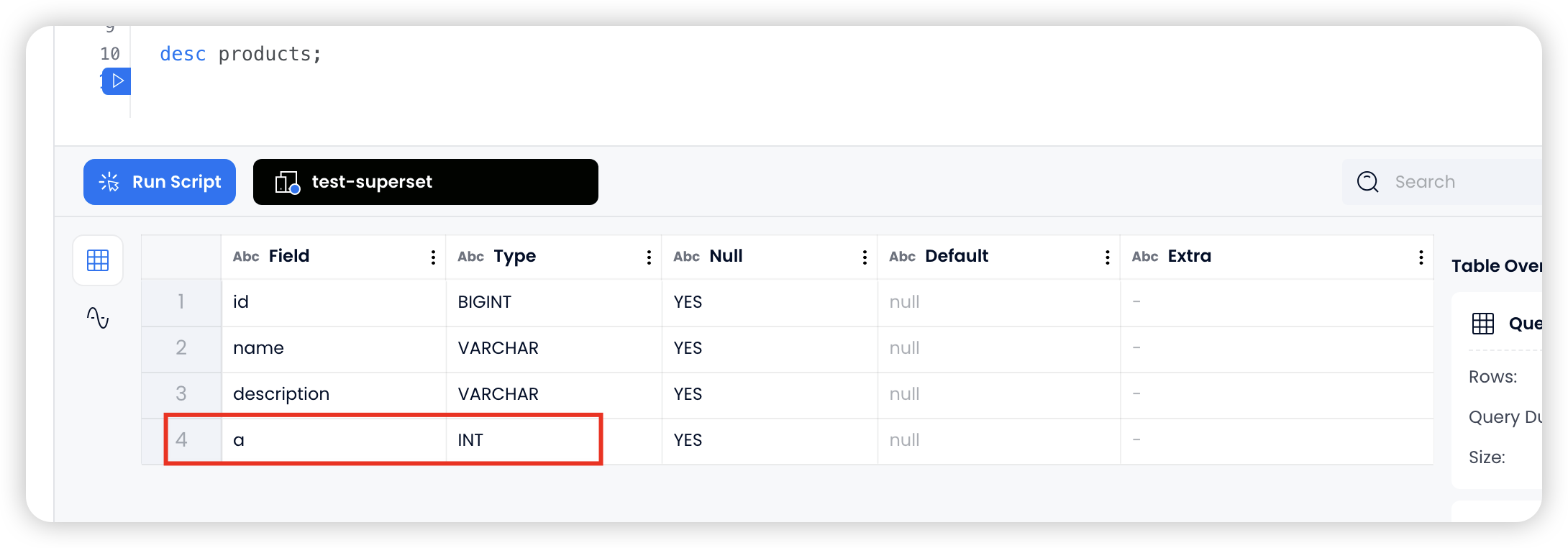
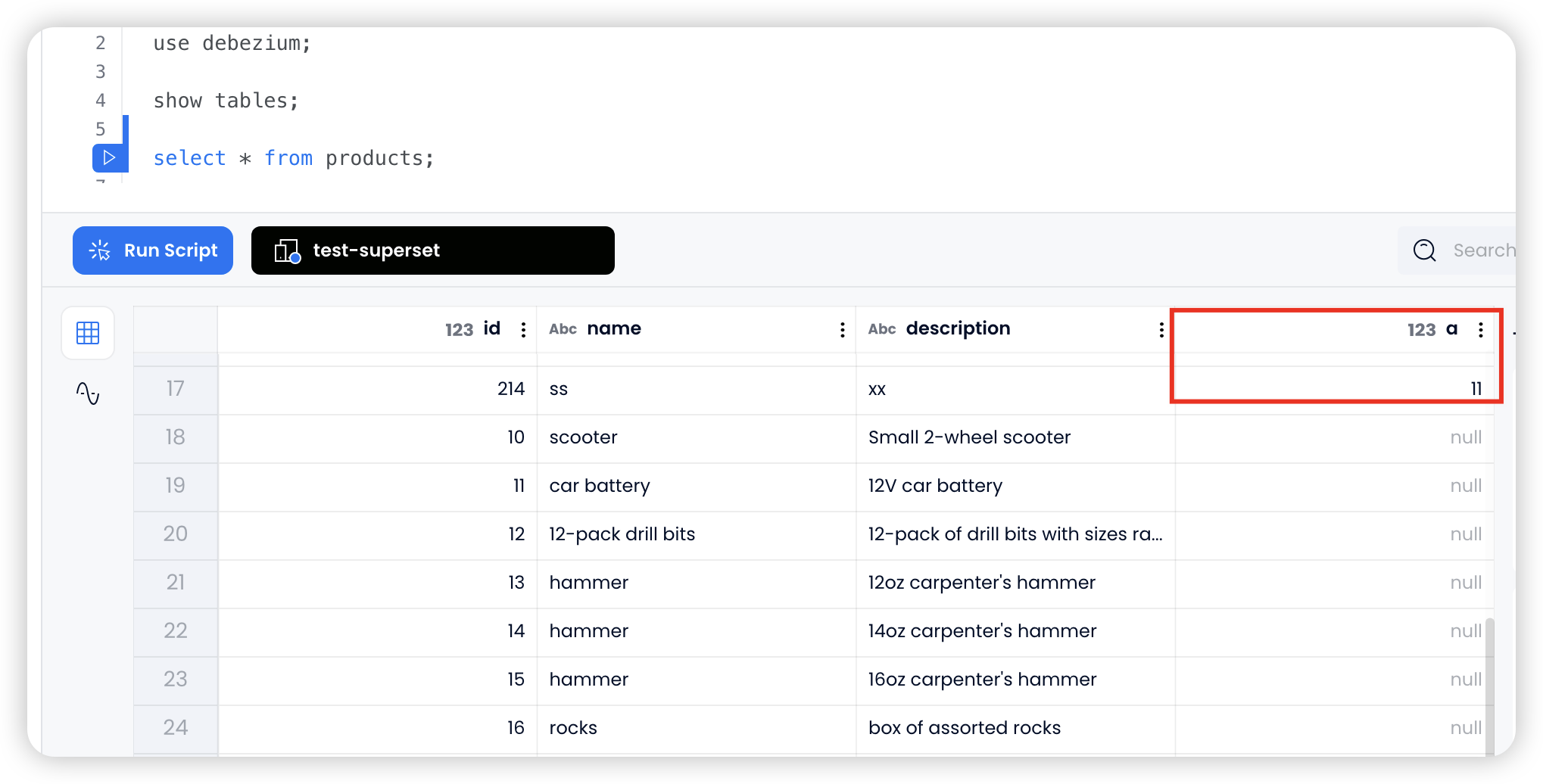



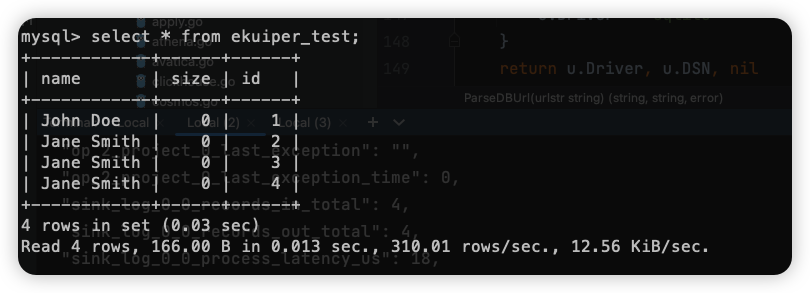
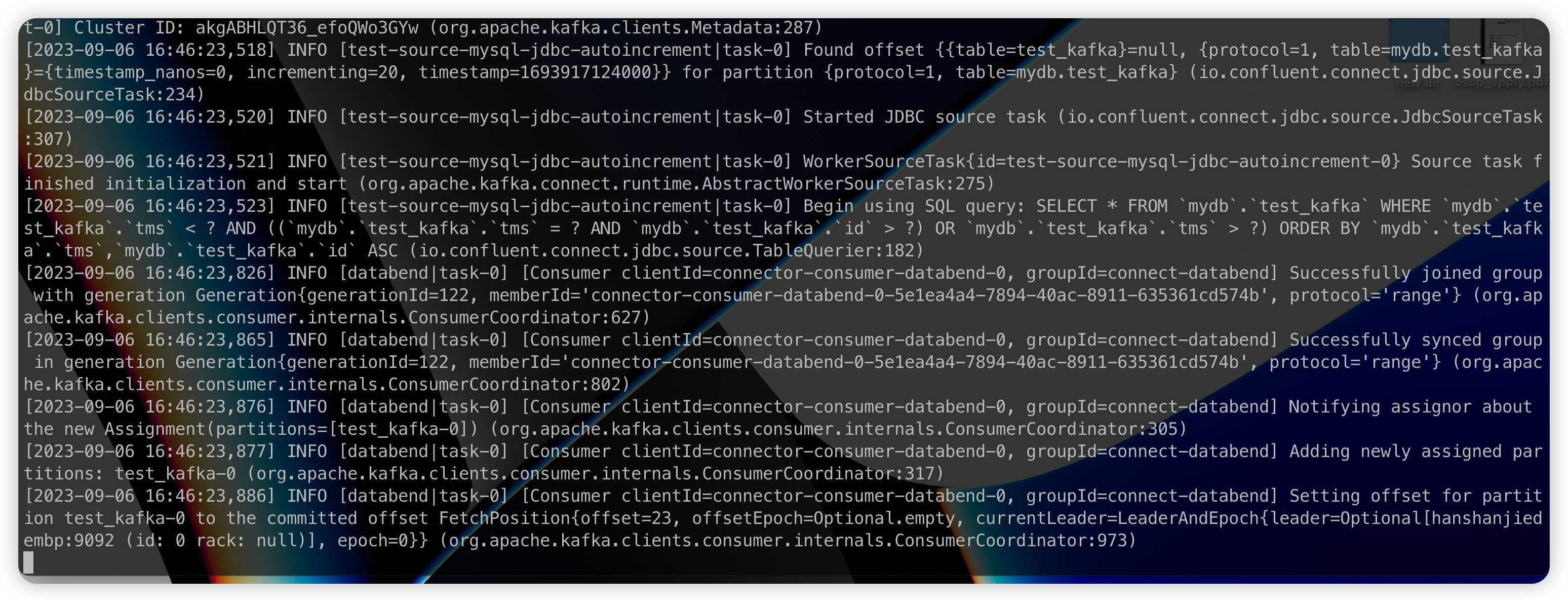
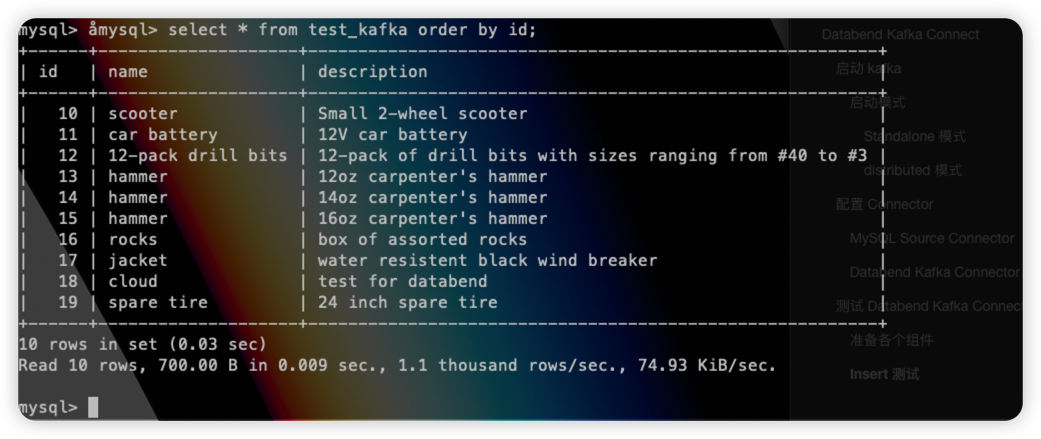
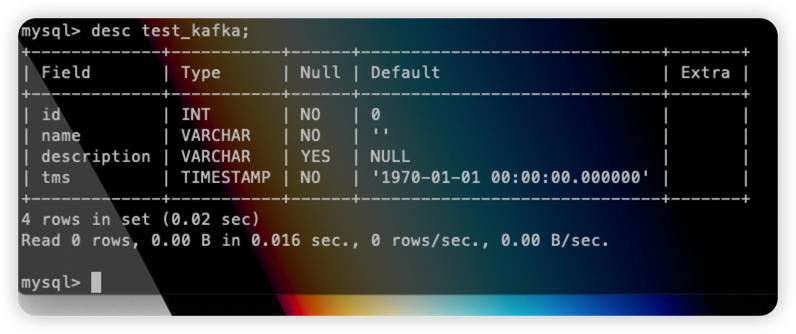
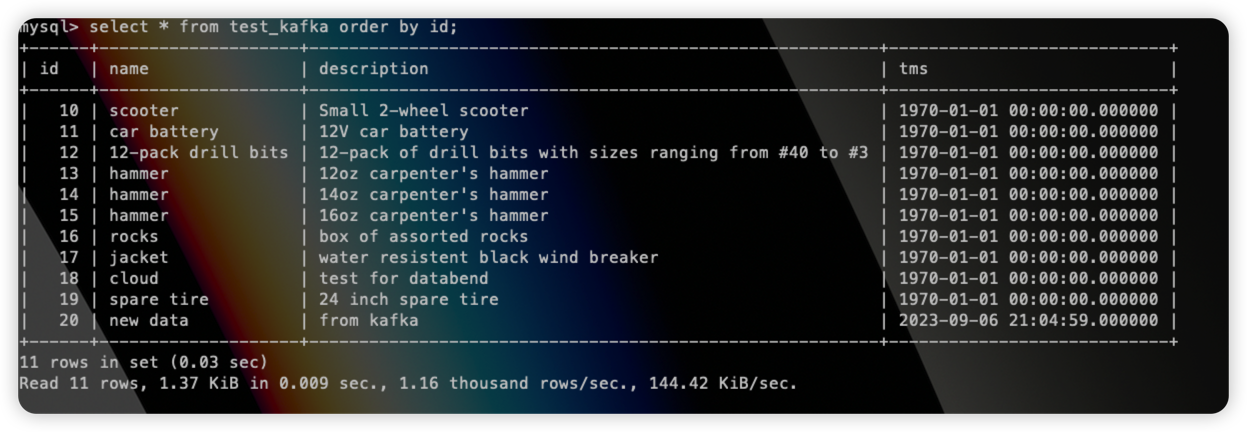
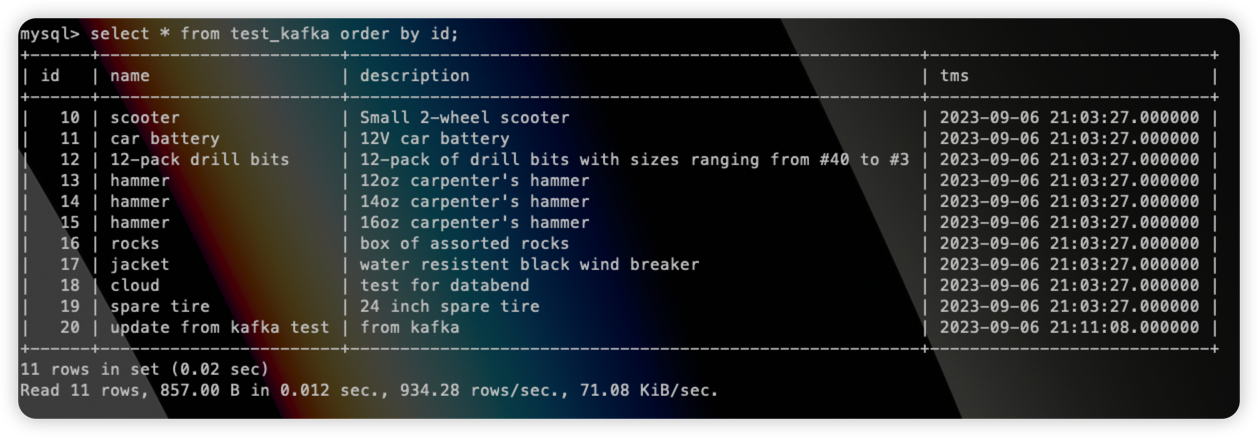
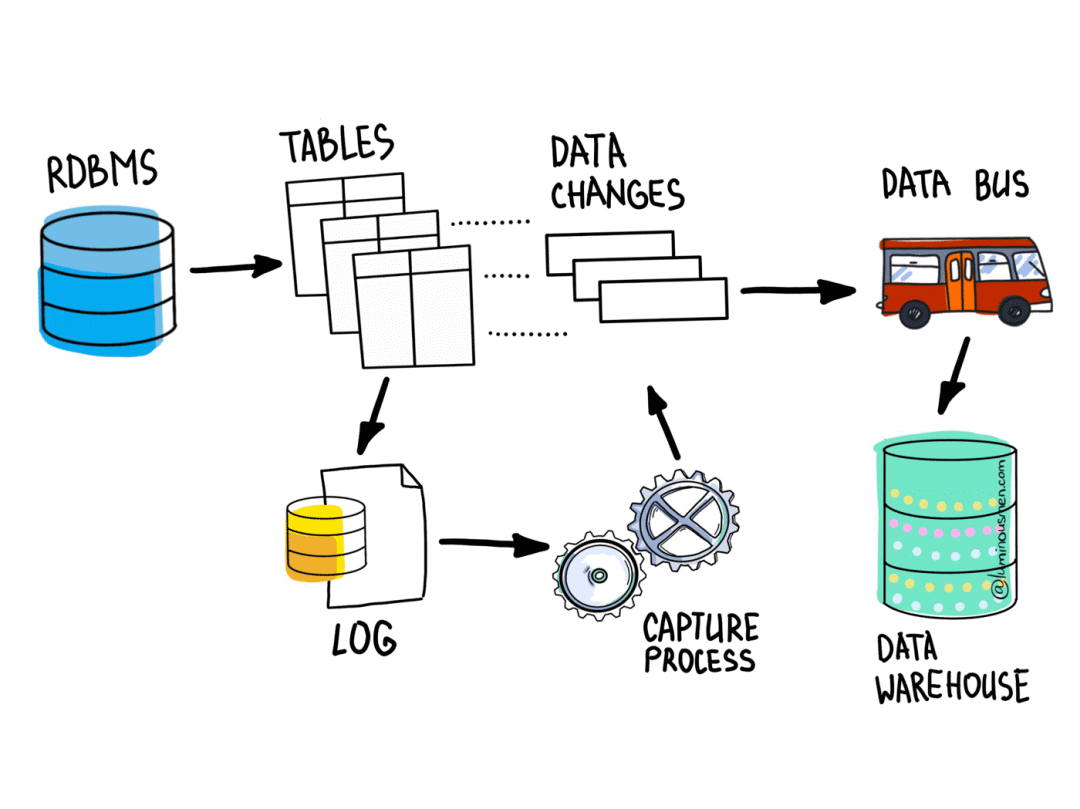
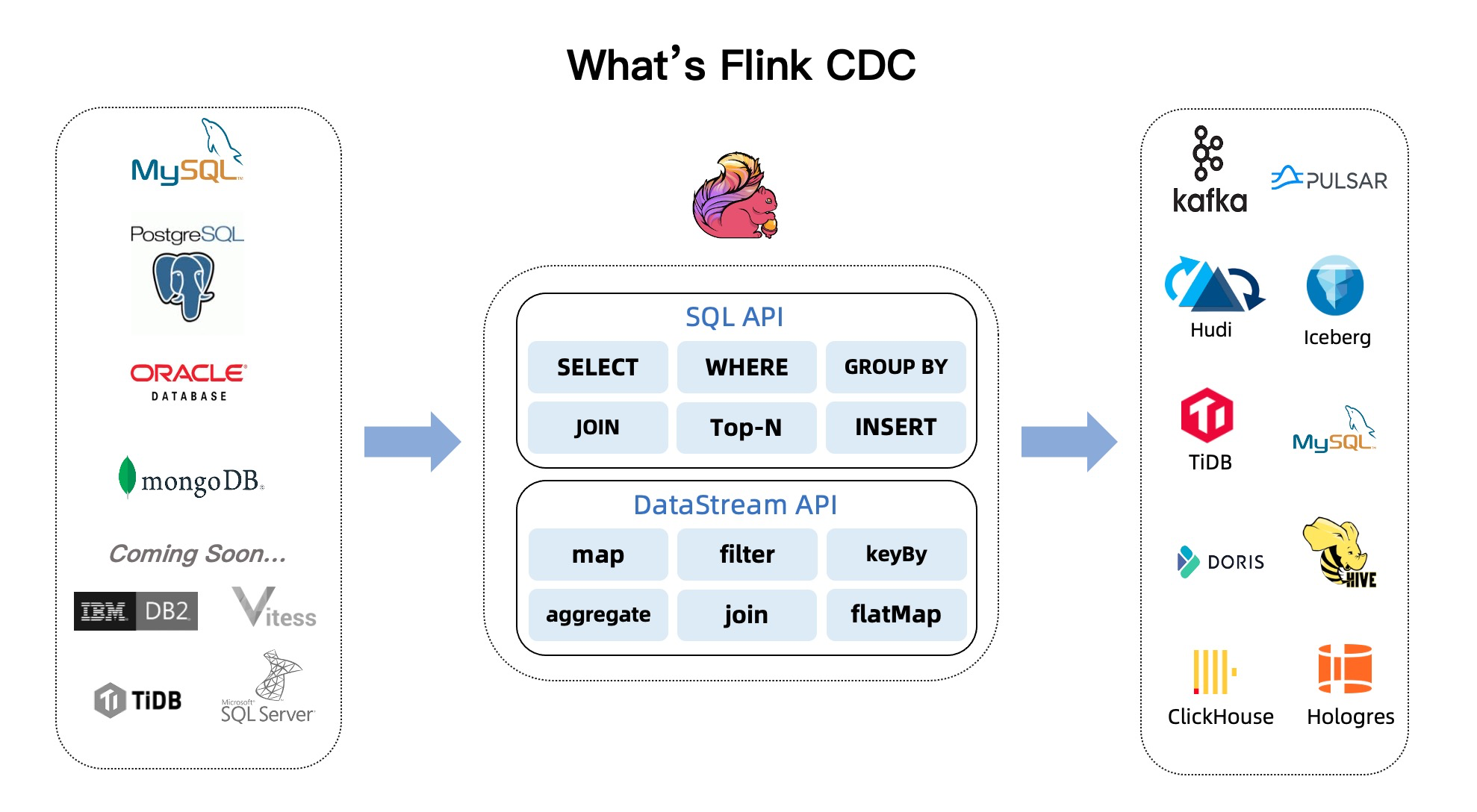
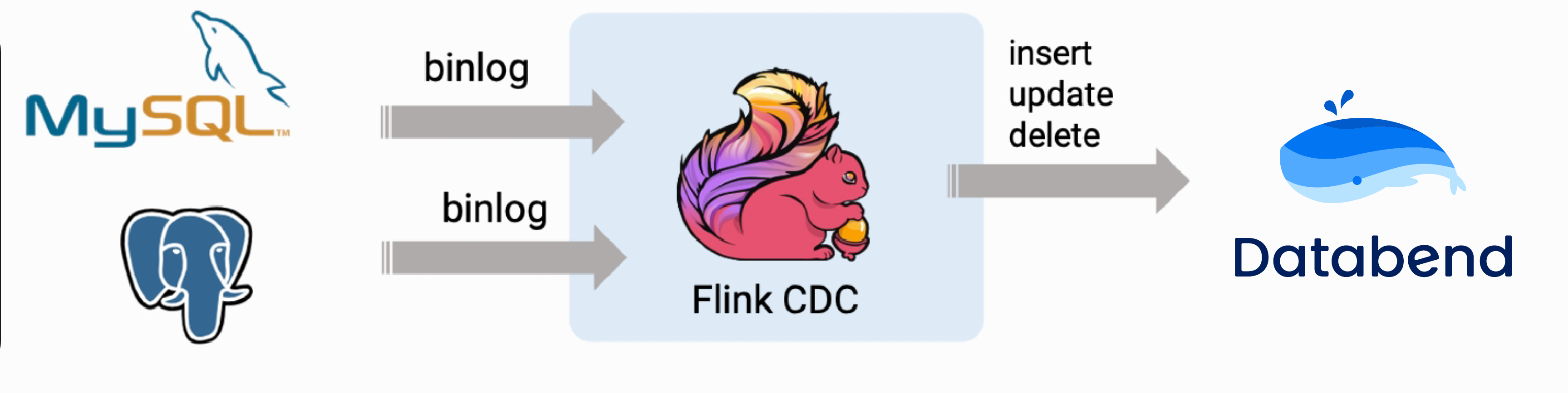
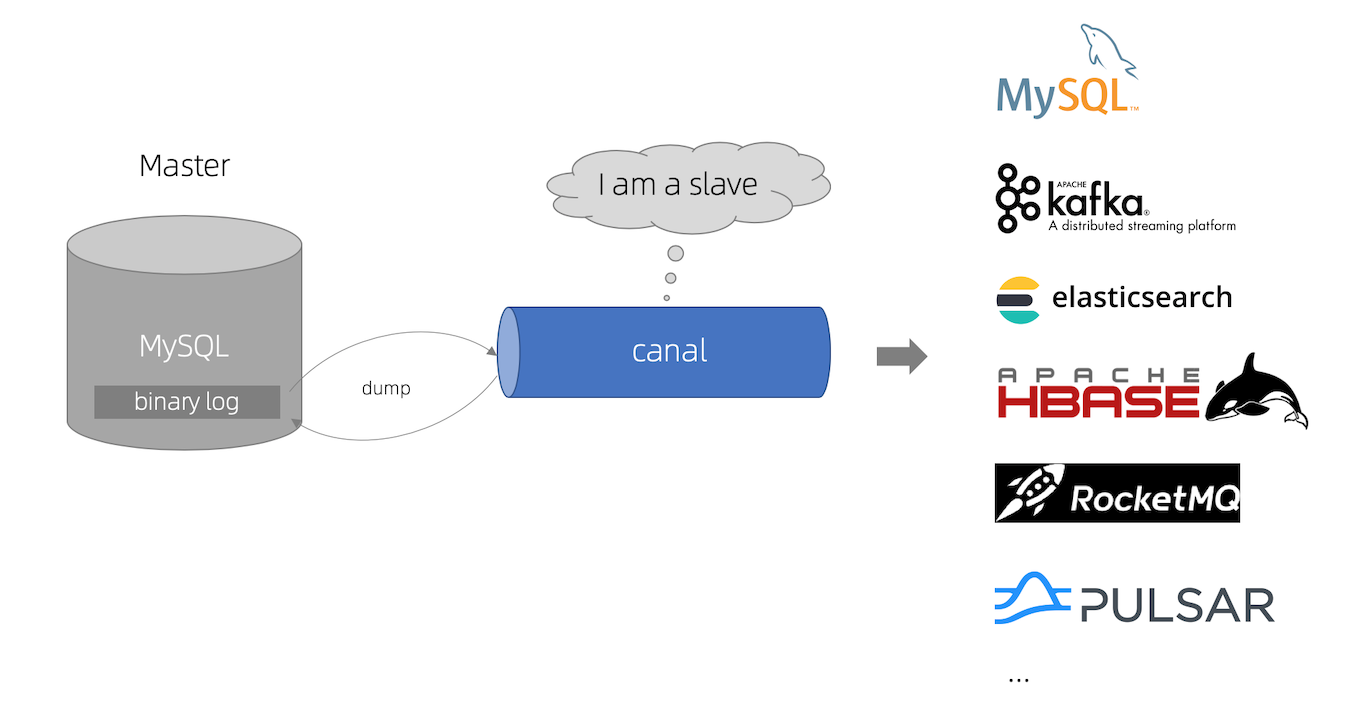
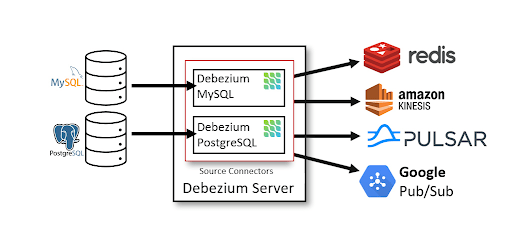
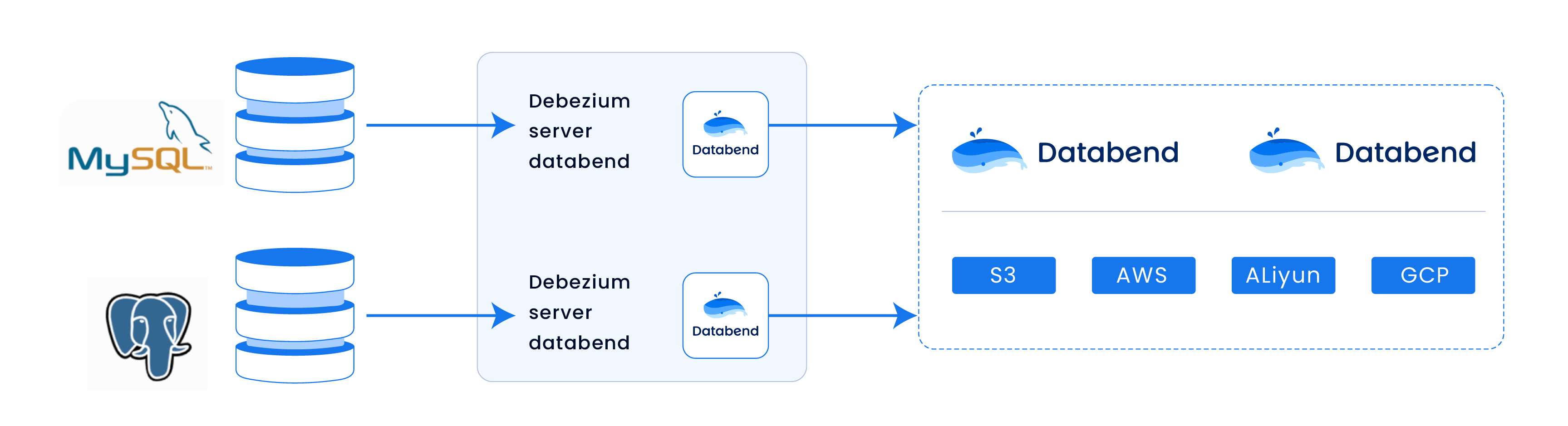
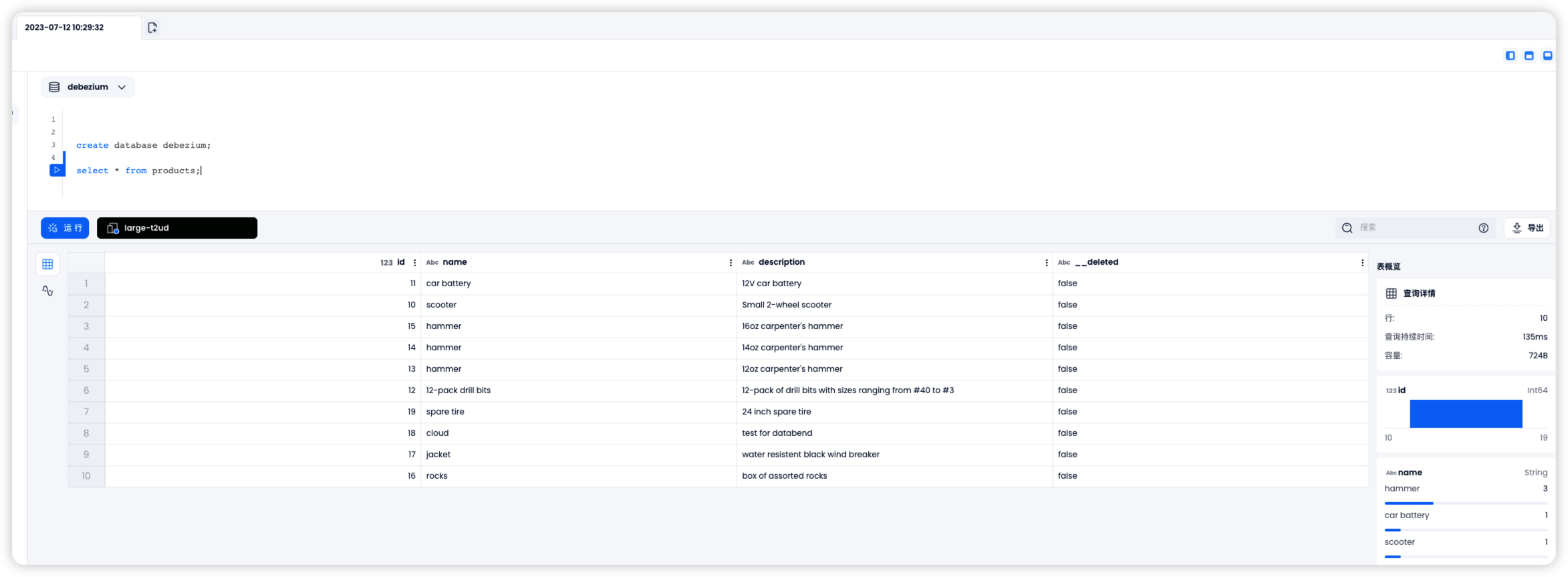

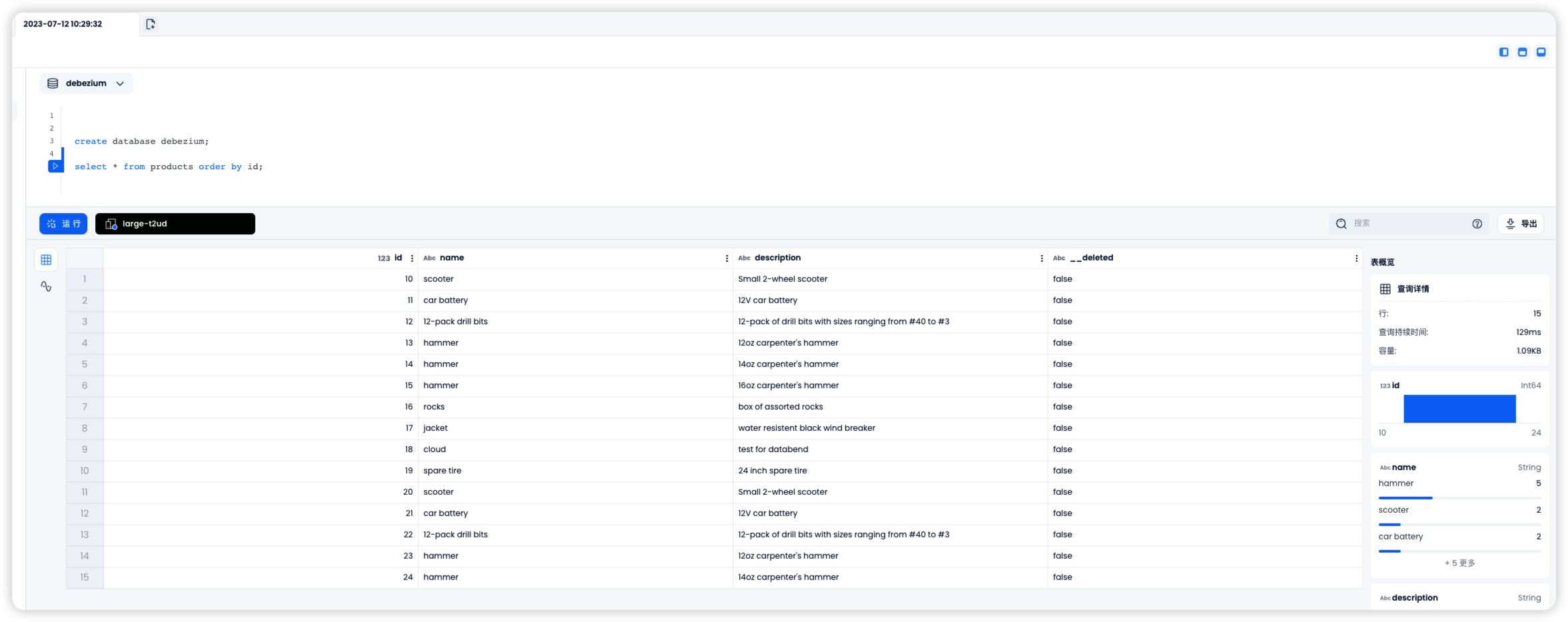
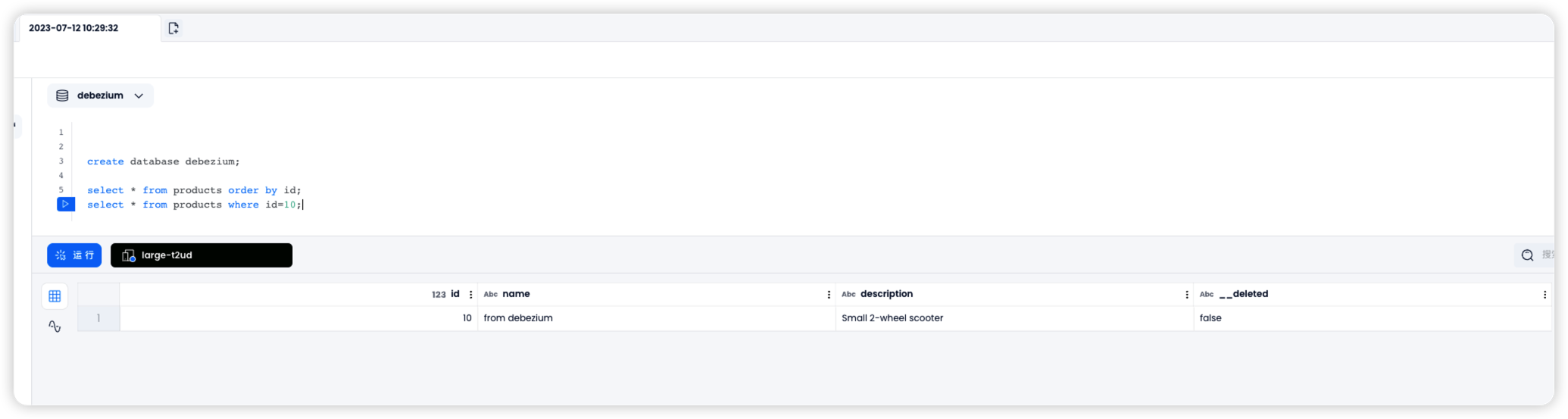

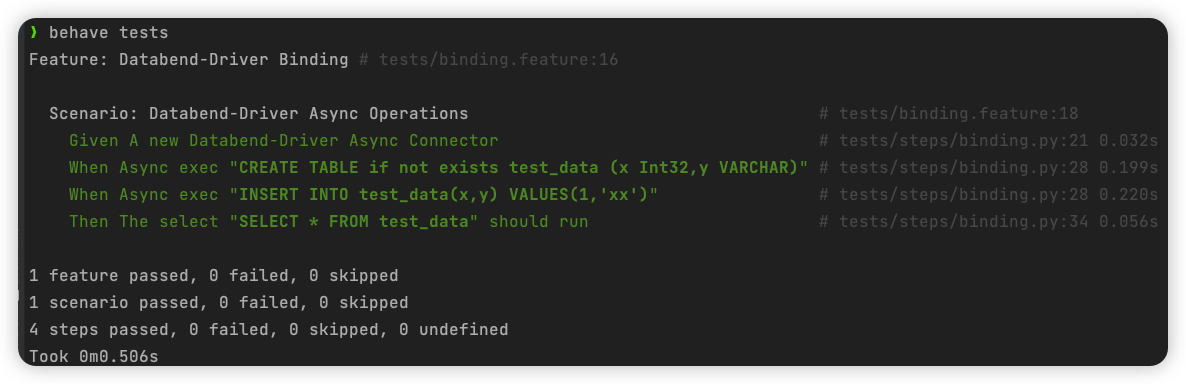
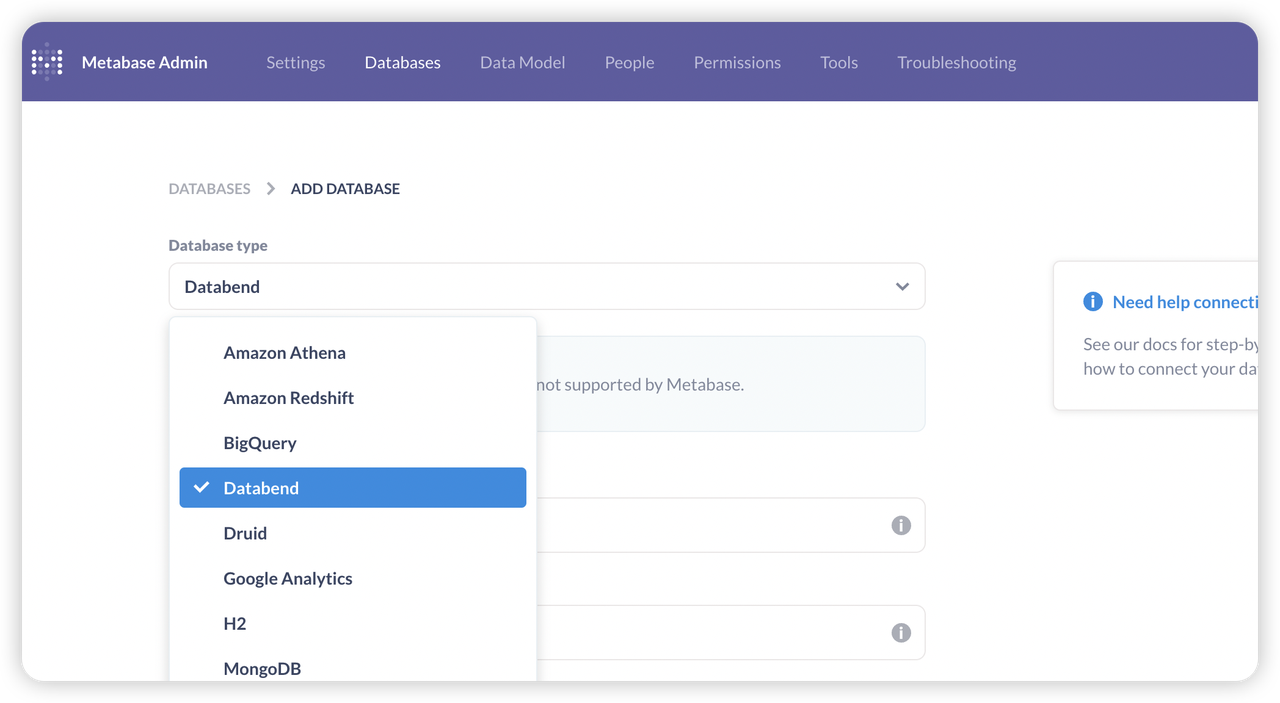
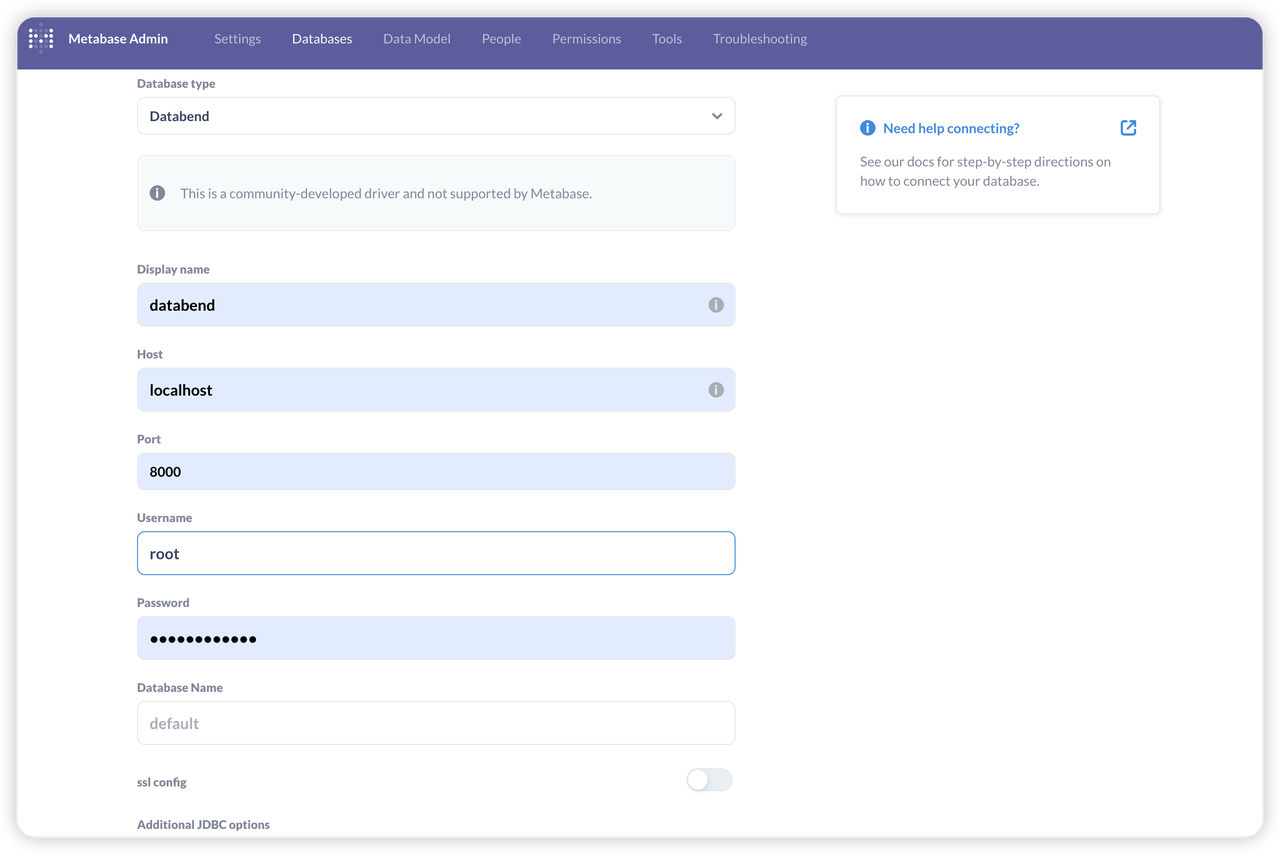
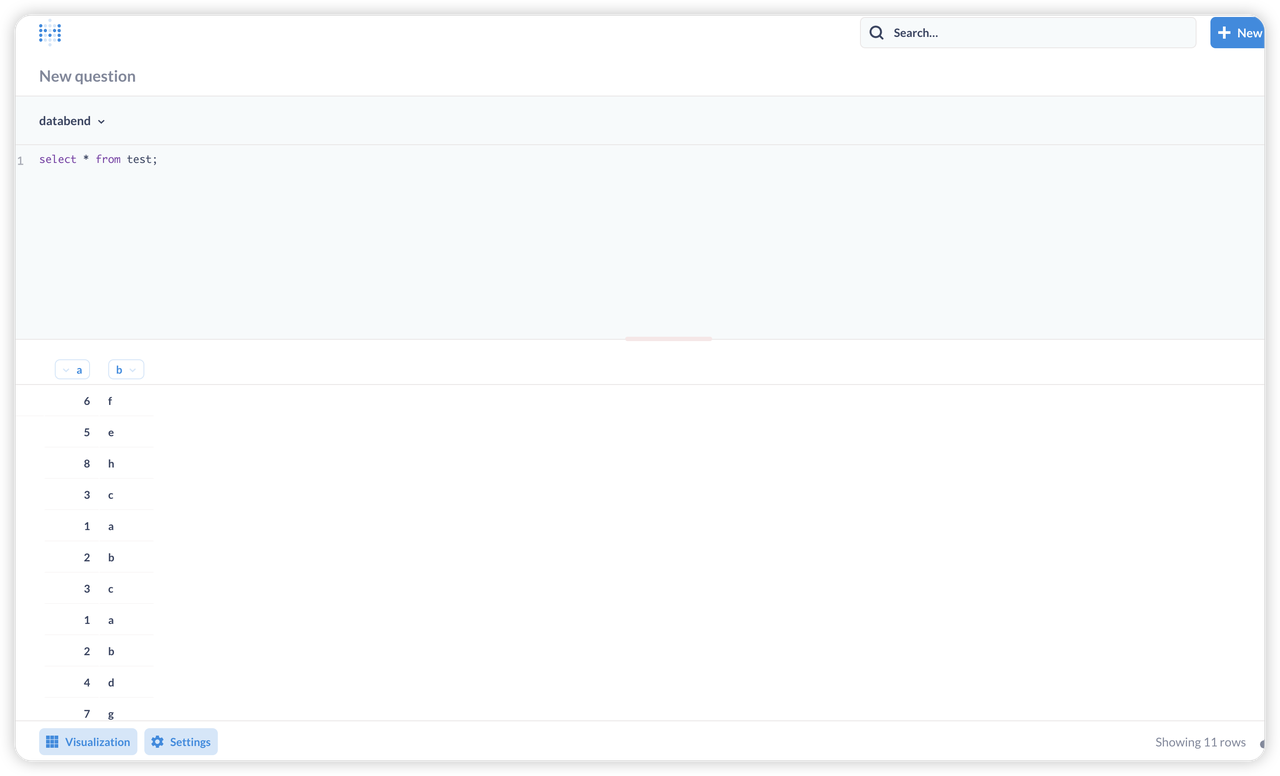






















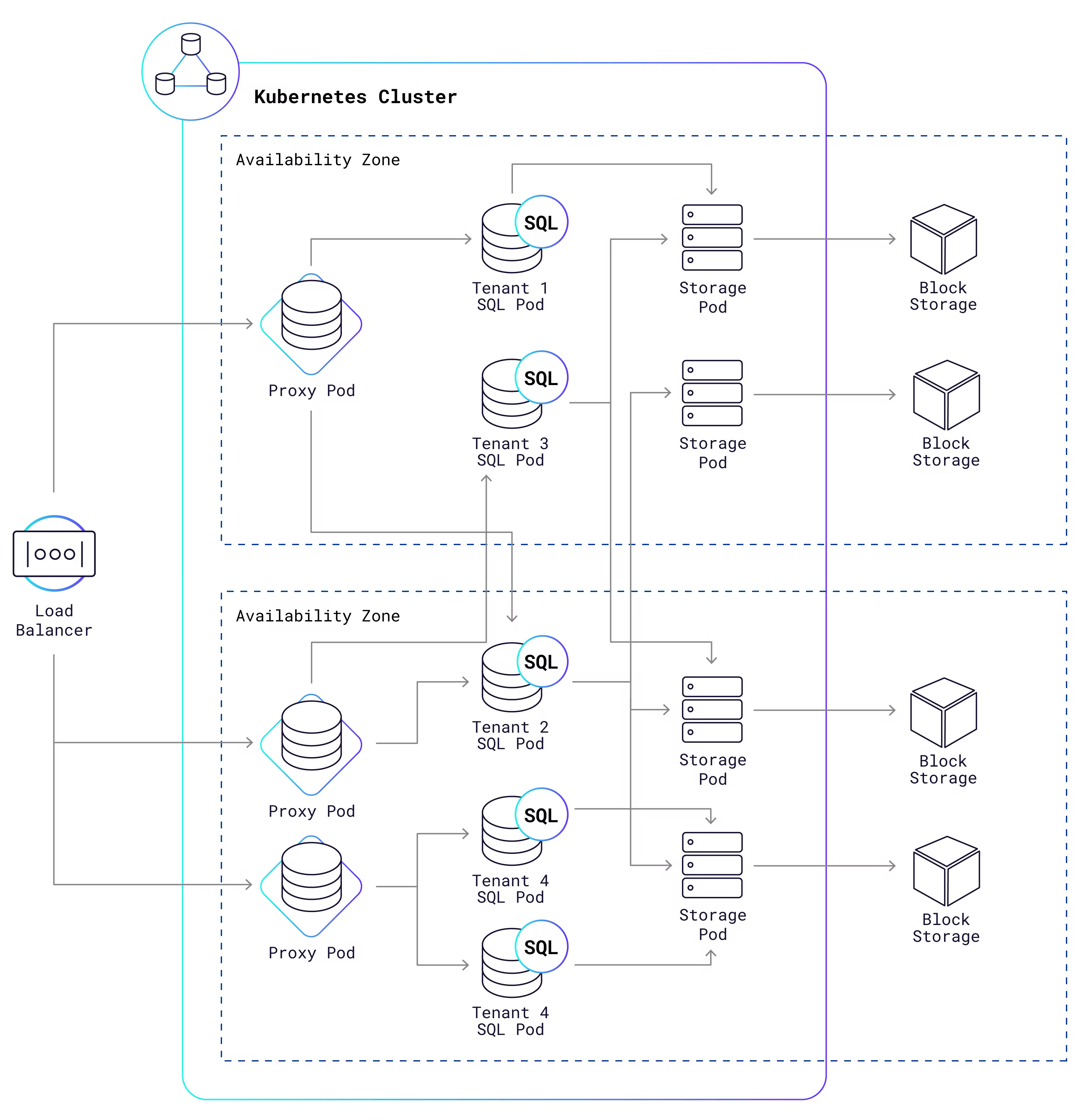































































































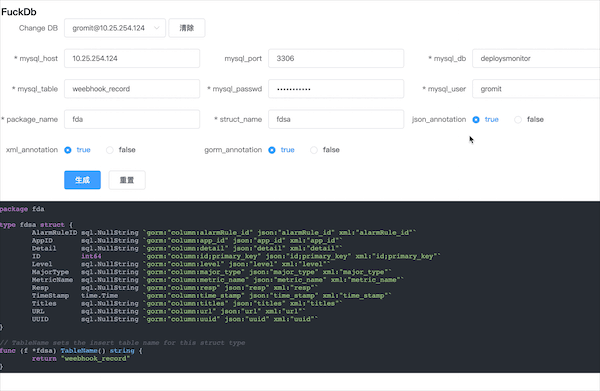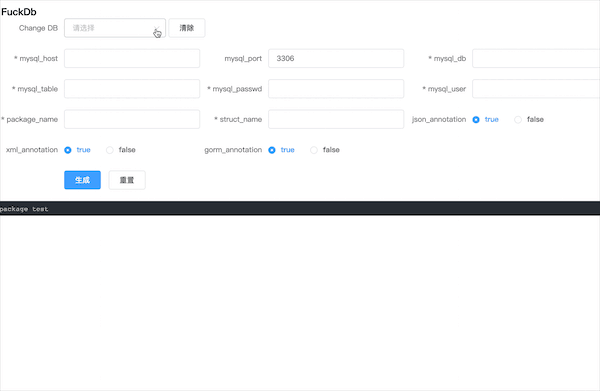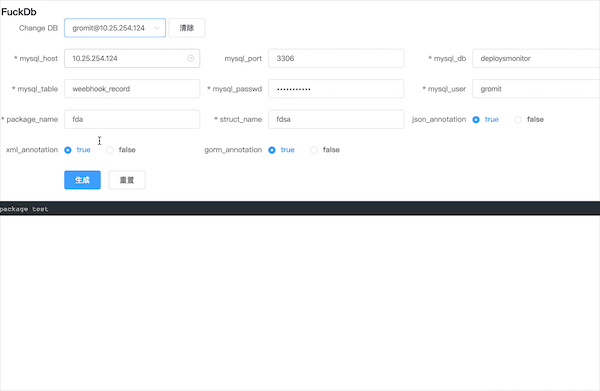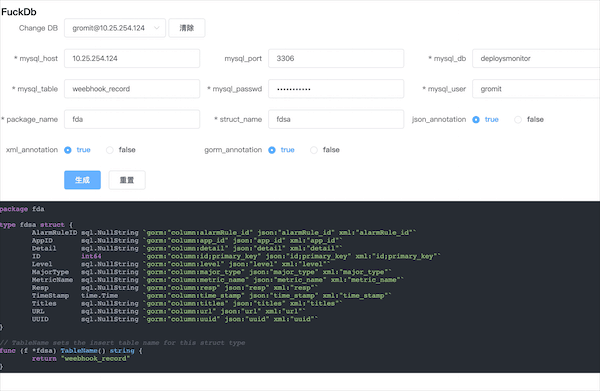















 v
v



 我要评论
我要评论