面试官:SFT训练到什么程度,才值得做RL?

面试官:SFT训练到什么程度,才值得做RL?

烟雨平生
发布于 2026-04-14 19:00:01
发布于 2026-04-14 19:00:01
这个问题挺有意思。因为这个问题看似简单,但要答好其实得把整个对齐流程的底层逻辑理清楚。
先给出答案:当你的模型已经 “会答”(指令稳定、Reward 分布均匀),但还需要 “答得更好” 时,就值得做 RL。
下面我们就来拆解下这个题目。
先来对齐下这几个概念:
什么是SFT?Supervised Fine-Tuning,有监督的微调训练。
什么是RL?Reinforcement Learning,强化学习。
什么是RLHF?Reinforcement Learning from Human Feedback,人类反馈强化学习,通过将人类的反馈纳入训练过程,为机器提供了一种互动学习方式。
对齐这几个概念后,我们来进一步分析这个问题。
一、先看数据:你有 “标准答案” 吗?
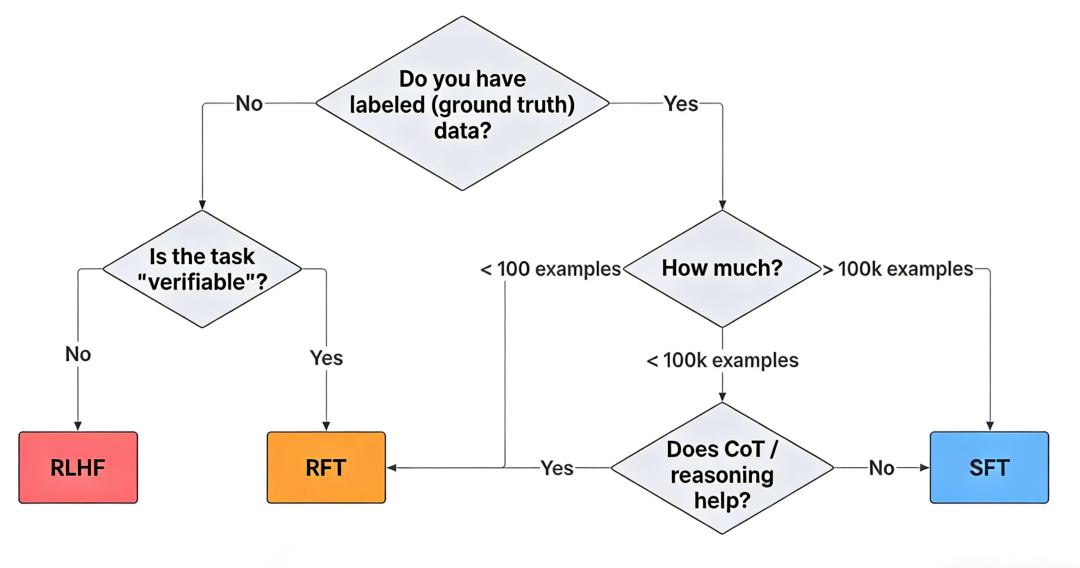
有标注数据(Ground Truth)?
- 数据量 > 100k: 直接上 SFT。数据够多,模型能直接学到 “正确答案”,这时候 SFT 是最高效的。
- 数据量 < 100k: 再看任务。
- 任务需要推理(CoT 有帮助)? 用 RFT(拒绝采样微调),让模型自己生成多个答案,再选对的学。
- 任务不需要推理? 继续用少量数据做 SFT。
没有标注数据?
- 任务是 “可验证” 的? 比如解数学题,答案对不对一眼就能看出来。用 RFT,让模型自己算,然后挑对的。
- 任务不可验证? 比如写文案、做对话,好不好很主观。这时候就该上 RLHF 了。
我们先从根源上理解,为什么会有“训练到什么程度”这种问题,这背后其实涉及到两次对齐的过程。
两次对齐过程:
第一次对齐:为什么必须先做SFT?将互联网语言模型对齐成对话语言模型。预训练模型优化的是 completion 而非对话,直接用 RLHF 存在 reward 分布极度偏向负反馈、模型学不起来的问题,所以需用SFT让模型学会基本对话格式和指令跟随。
第二次对齐:从对话到可用。从对话语言模型对齐到可用性强且安全的语言模型,此时适合用 RL,因为模型已会回答,且 RL 可对不同回答打分、利用用户反馈、在 TOKEN 级别的 credit assignment 上有优势。
二、再看模型:SFT练到“及格线”了吗?
光看数据还不够,你得摸一摸模型的 “底”:
2.1 指令跟随稳不稳?
SFT 的核心目标,是把一个只会 “续写” 的预训练模型,调教成一个 “听话” 的对话模型。
- 及格线: 你问它什么,它都能按你的要求来,格式正确,答非所问的情况很少。
- 不及格: 它还在自顾自地续写文本,或者经常跑偏,那 SFT 还没到位,继续练。
譬如,Deepseek 团队在 SFT 阶段使用了 150 万条高质量数据,其中包含 120 万条 “有益” 对话数据和 30 万条 “安全” 对齐数据。他们让模型跑了 2 个 Epoch,学习率控制在 5e-6 这个量级。
结果:模型形成了稳定的对话能力,输出分布对齐到了对话语言模型上,不再做无意义的文本补全,这才具备了切换到 RL 的基础。
2.2 Reward 分布均不均匀?
这是最硬核的判断标准。用 SFT 后的模型对同一个问题采样多个回答,然后用 Reward Model 打分:
- 可以切 RL: 分数分布比较均匀,有高分也有低分。这说明模型已经 “会答” 了,但 “答得好不好” 有差异,RL 正好可以用来 “择优”,把高分答案的概率拉高。
- 继续 SFT: 所有回答的 Reward 都很低,说明模型根本还 “不会答”,这时候上 RL 就是在垃圾堆里挑金子,纯属浪费算力。
案例:某电商客服机器人
某团队在训练电商客服机器人时,SFT 后发现,对于 “如何退换货” 这类问题,模型的回答 Reward 分布非常集中,且都在低分区间。
- 分析: 这说明模型还没真正理解退换货的流程,只是在复述模板。
- 决策: 他们没有急着上 RL,而是补充了大量真实的客服对话数据,重新进行 SFT。当 Reward 分布开始变得分散,出现了高分回答后,才启动了 RLHF,让模型学习如何更自然、更有帮助地回答用户问题。
2.3 数据规模够不够?
参考 Deepseek V2 的实践:用 150 万条高质量 SFT 数据(120 万有益 + 30 万安全),跑 2 个 Epoch,学习率在 5e-6 量级,就能让模型形成稳定的对话能力。你可以把这个当成一个参考基准。
三、最后看成本:什么时候RL更划算?
从 “性价比” 角度看,RL的优势在后期才会显现:
SFT 阶段:
成本高。每一条数据都需要人工标注完整的 “问题 - 答案” 对,数据越标越贵,边际效益递减。
RL 阶段:
效率高。模型自己生成候选答案,人只需要做偏好排序(A 比 B 好),甚至可以用 Reward Model 自动打分,标注成本和难度都大大降低。
所以,当你发现继续用 SFT 提升模型质量的成本越来越高,而效果越来越不明显时,就是切换到 RL 的最佳时机。
案例:某内容创作 AI
一家公司在训练文案生成模型时,初期 SFT 效果很好,但当他们想让文案更有 “网感” 和 “情绪价值” 时,发现 SFT 的边际效益急剧下降。
- 痛点: 要标注出 “更有网感” 的标准答案非常困难且昂贵。
- 决策: 他们切换到了 RLHF,让模型先自己生成多条文案,再由运营人员进行 “这条比那条好” 的简单排序。
- 结果: 标注成本降低了 70%,模型产出的文案质量却得到了显著提升。
四、小结
当你的模型已经 “会答”(指令稳定、Reward 分布均匀),但还需要 “答得更好” 时,就值得做 RL。
如果它连 “答” 都还没学会,先回去好好打磨 SFT 吧。
图片
大语言模型训练范式入门课:LLM都是如何训练出来的?干货满满,一文讲清楚!

https://www.bilibili.com/video/BV1EfPkzmECS/?vd_source=028ee6e6a7217b4a4237d439b7fd348d
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号