




前言
办公过程中,总是会遇到一些大量重复做的事情,通过生成一些小程序,提高办公效率。
一、批量html文件转化为pdf
1. 问题描述
我需要将若干的html文件转换为pdf,要求:
- 自主选择源文件和输出文件。
- 新文件命名方式,要么根据文件名重新生成学号+姓名,要么保持原文件名,至于更复杂的命名方式后续碰到了再增加。
2.代码
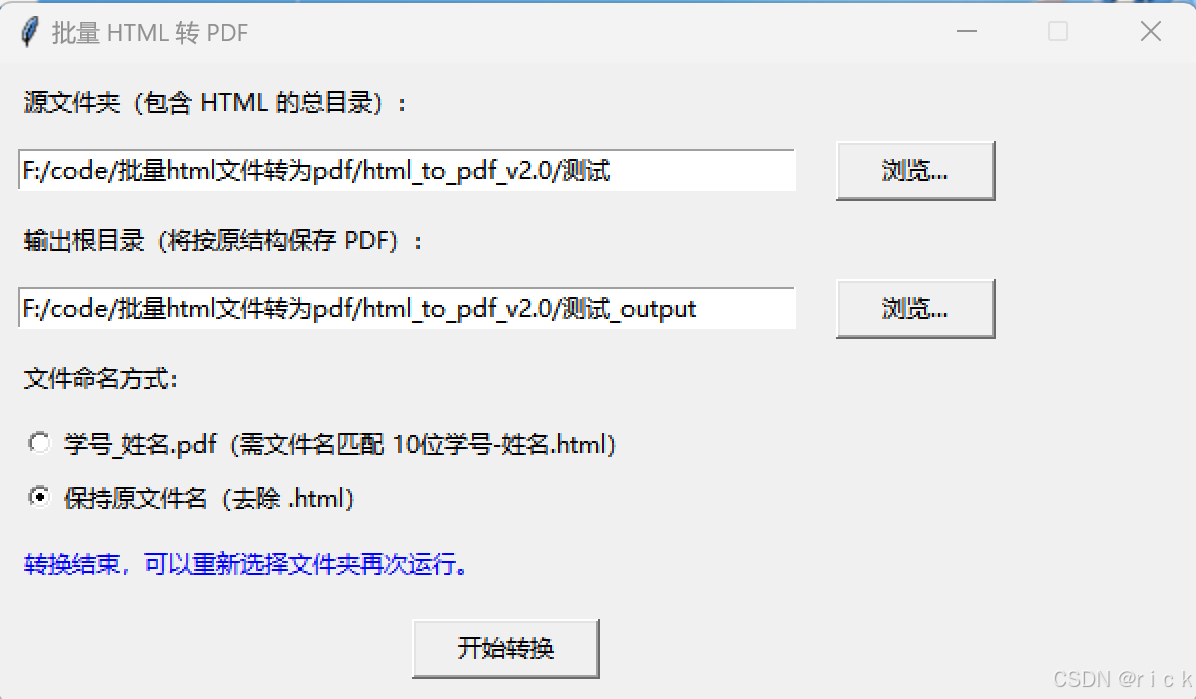
一共是两个版本,版本1是加了谷歌浏览器进去,可能有700MB;版本2是用的Edge浏览器,不到50MB。代码也贴出来,可以直接拿来运行,同时也生成了.exe文件,下载后双击直接运行即可。
版本1,使用谷歌,运行过程中差的包通过pip下载即可。
import os
import re
import asyncio
from pathlib import Path
from playwright.async_api import async_playwright
# GUI 相关
import tkinter as tk
from tkinter import filedialog, messagebox
# 3. 文件命名规则:10位学号 + 姓名
# - 支持前面有任意前缀,例如:PJDS2022443948-张三.html,ZRDS2023444591-李四.html
# - 如果你想要“学号-姓名.pdf”,把下面 new_filename 那一行改一下即可
# 支持前缀的正则:前面可以有任意非数字字符,然后 10 位数字,再“-姓名.html”
HTML_NAME_PATTERN = re.compile(r"\D*(\d{10})-([^.]+)\.html$", re.IGNORECASE)
async def convert_all(source_folder: str, output_root: str, filename_mode: str = "student"):
"""
filename_mode:
- "student": 使用 10 位学号+姓名,格式:学号_姓名.pdf
- "original": 保留原 html 文件名(去掉扩展名)
"""
if not os.path.exists(source_folder):
print(f"源路径不存在,请检查: {source_folder}")
return
# 确保输出根目录存在
Path(output_root).mkdir(parents=True, exist_ok=True)
total_html = 0 # 找到的 html 总数
matched_html = 0 # 文件名匹配“学号+姓名”的 html 数
converted = 0 # 实际成功转换的数量
unmatched_samples = [] # 未匹配样例,最多展示 5 个,方便你检查命名
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
src_root = Path(source_folder).resolve()
for root, _, files in os.walk(source_folder):
for file in files:
if not file.lower().endswith(".html"):
continue
total_html += 1
if filename_mode == "original":
matched_html += 1
new_filename = f"{Path(file).stem}.pdf"
else:
m = HTML_NAME_PATTERN.search(file)
if not m:
# 记录少量未匹配样例,方便你看命名有什么特例
if len(unmatched_samples) < 5:
unmatched_samples.append(Path(root, file).name)
continue
matched_html += 1
sid, name = m.group(1), m.group(2)
# 如需连字符:new_filename = f"{sid}-{name}.pdf"
new_filename = f"{sid}_{name}.pdf"
html_path = Path(root, file).resolve()
input_uri = html_path.as_uri()
# 计算相对“平时作业”的目录结构,在 output_root 中镜像创建
rel_dir = Path(root).resolve().relative_to(src_root)
target_dir = Path(output_root, rel_dir)
target_dir.mkdir(parents=True, exist_ok=True)
output_path = target_dir / new_filename
print(f"处理: {html_path} -> {output_path}")
try:
await page.goto(input_uri)
await page.pdf(path=str(output_path.resolve()))
converted += 1
except Exception as e:
print(f"转换失败: {file}, 异常: {e}")
await browser.close()
print("\n====== 处理完成 ======")
print(f"源目录: {src_root}")
print(f"扫描到 html 总数: {total_html}")
print(f"匹配“10位学号-姓名”规则的 html 数: {matched_html}")
if unmatched_samples:
print("未匹配到学号+姓名规则的示例(最多5个):")
for s in unmatched_samples:
print(" ", s)
print(f"成功转换 pdf 数量: {converted}")
print(f"输出根目录: {Path(output_root).resolve()}")
def run_gui():
"""简单图形界面:选择源文件夹和输出文件夹,然后开始转换"""
root = tk.Tk()
root.title("批量 HTML 转 PDF")
root.geometry("600x320")
root.resizable(False, False)
# 居中窗口
root.update_idletasks()
w = 600
h = 320
ws = root.winfo_screenwidth()
hs = root.winfo_screenheight()
x = int((ws / 2) - (w / 2))
y = int((hs / 2) - (h / 2))
root.geometry(f"{w}x{h}+{x}+{y}")
source_var = tk.StringVar()
output_var = tk.StringVar(value="归档完成_PDF版")
filename_mode_var = tk.StringVar(value="student")
status_var = tk.StringVar(value="请选择源/输出文件夹,选择文件命名方式,然后点击“开始转换”")
def choose_source():
path = filedialog.askdirectory(title="选择包含 HTML 的“平时作业”总目录")
if path:
source_var.set(path)
def choose_output():
path = filedialog.askdirectory(title="选择 PDF 输出根目录(可新建空文件夹)")
if path:
output_var.set(path)
def start_convert():
source = source_var.get().strip()
output = output_var.get().strip()
if not source:
messagebox.showwarning("提示", "请先选择源文件夹")
return
if not os.path.exists(source):
messagebox.showerror("错误", f"源文件夹不存在:\n{source}")
return
if not output:
messagebox.showwarning("提示", "请先选择或填写输出文件夹")
return
# 如果输出目录不存在,可以提前创建
Path(output).mkdir(parents=True, exist_ok=True)
btn_convert.config(state=tk.DISABLED)
status_var.set("正在转换,请稍候……(控制台也会显示详细进度)")
root.update_idletasks()
try:
# 直接在按钮回调中运行异步任务,期间窗口会短暂停止响应,这是正常的
asyncio.run(convert_all(source, output, filename_mode_var.get()))
messagebox.showinfo("完成", "全部转换完成!\n详细信息请查看控制台输出。")
except Exception as e:
messagebox.showerror("错误", f"转换过程中出现异常:\n{e}")
finally:
btn_convert.config(state=tk.NORMAL)
status_var.set("转换结束,可以重新选择文件夹再次运行。")
# ===== 布局 =====
padding_x = 10
padding_y = 8
# 源文件夹
tk.Label(root, text="源文件夹(包含 HTML 的总目录):").grid(
row=0, column=0, sticky="w", padx=padding_x, pady=padding_y
)
tk.Entry(root, textvariable=source_var, width=55).grid(
row=1, column=0, padx=padding_x, pady=0, sticky="w"
)
tk.Button(root, text="浏览...", command=choose_source, width=10).grid(
row=1, column=1, padx=padding_x, pady=0
)
# 输出文件夹
tk.Label(root, text="输出根目录(将按原结构保存 PDF):").grid(
row=2, column=0, sticky="w", padx=padding_x, pady=padding_y
)
tk.Entry(root, textvariable=output_var, width=55).grid(
row=3, column=0, padx=padding_x, pady=0, sticky="w"
)
tk.Button(root, text="浏览...", command=choose_output, width=10).grid(
row=3, column=1, padx=padding_x, pady=0
)
# 文件命名方式
tk.Label(root, text="文件命名方式:").grid(
row=4, column=0, sticky="w", padx=padding_x, pady=padding_y
)
radio_frame = tk.Frame(root)
radio_frame.grid(row=5, column=0, columnspan=2, sticky="w", padx=padding_x, pady=0)
tk.Radiobutton(
radio_frame,
text="学号_姓名.pdf(需文件名匹配 10位学号-姓名.html)",
variable=filename_mode_var,
value="student",
).pack(anchor="w")
tk.Radiobutton(
radio_frame,
text="保持原文件名(去除 .html)",
variable=filename_mode_var,
value="original",
).pack(anchor="w")
# 状态栏
tk.Label(root, textvariable=status_var, fg="blue").grid(
row=6, column=0, columnspan=2, sticky="w", padx=padding_x, pady=padding_y
)
# 开始按钮
btn_convert = tk.Button(root, text="开始转换", command=start_convert, width=12)
btn_convert.grid(row=7, column=0, columnspan=2, pady=padding_y)
root.mainloop()
if __name__ == "__main__":
# 直接运行脚本时,启动 GUI
run_gui()
版本2,使用edge。
import os
import re
import sys
import asyncio
import threading
from pathlib import Path
from playwright.async_api import async_playwright
# GUI 相关
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
# 为脚本/打包后的 exe 固定 Playwright 浏览器存放路径(程序所在目录下的 playwright-browsers)
if getattr(sys, "frozen", False):
# 打包后的 exe
BASE_DIR = Path(sys.executable).parent
else:
# 直接用脚本运行
BASE_DIR = Path(__file__).parent
PLAYWRIGHT_BROWSER_DIR = BASE_DIR / "playwright-browsers"
os.environ.setdefault("PLAYWRIGHT_BROWSERS_PATH", str(PLAYWRIGHT_BROWSER_DIR))
# 3. 文件命名规则:10位学号 + 姓名
# - 支持前面有任意前缀,例如:PJDS2022443948-张三.html,ZRDS2023444591-李四.html
# - 如果你想要“学号-姓名.pdf”,把下面 new_filename 那一行改一下即可
# 支持前缀的正则:前面可以有任意非数字字符,然后 10 位数字,再“-姓名.html”
HTML_NAME_PATTERN = re.compile(r"\D*(\d{10})-([^.]+)\.html$", re.IGNORECASE)
async def convert_all(source_folder: str, output_root: str, filename_mode: str = "student", progress_callback=None):
"""
filename_mode:
- "student": 使用 10 位学号+姓名,格式:学号_姓名.pdf
- "original": 保留原 html 文件名(去掉扩展名)
progress_callback: 进度回调函数,接受 (current, total, message) 参数
"""
if not os.path.exists(source_folder):
error_msg = f"源路径不存在,请检查: {source_folder}"
print(error_msg)
if progress_callback:
progress_callback(0, 0, error_msg)
return
# 确保输出根目录存在
Path(output_root).mkdir(parents=True, exist_ok=True)
total_html = 0 # 找到的 html 总数
matched_html = 0 # 文件名匹配"学号+姓名"的 html 数
converted = 0 # 实际成功转换的数量
unmatched_samples = [] # 未匹配样例,最多展示 5 个,方便你检查命名
if progress_callback:
progress_callback(0, 0, "正在启动浏览器,请稍候...")
async with async_playwright() as p:
# 直接使用本机已安装的 Microsoft Edge(Windows 默认自带),避免打包内置浏览器体积过大
browser = await p.chromium.launch(headless=True, channel="msedge")
page = await browser.new_page()
if progress_callback:
progress_callback(0, 0, "浏览器已启动,正在扫描文件...")
src_root = Path(source_folder).resolve()
# 先扫描一遍,统计总数
html_files = []
for root, _, files in os.walk(source_folder):
for file in files:
if not file.lower().endswith(".html"):
continue
total_html += 1
html_files.append((root, file))
if total_html == 0:
if progress_callback:
progress_callback(0, 0, "未找到任何 HTML 文件")
return
if progress_callback:
progress_callback(0, total_html, f"找到 {total_html} 个 HTML 文件,开始转换...")
# 开始转换
for idx, (root, file) in enumerate(html_files, 1):
if filename_mode == "original":
matched_html += 1
new_filename = f"{Path(file).stem}.pdf"
else:
m = HTML_NAME_PATTERN.search(file)
if not m:
# 记录少量未匹配样例,方便你看命名有什么特例
if len(unmatched_samples) < 5:
unmatched_samples.append(Path(root, file).name)
continue
matched_html += 1
sid, name = m.group(1), m.group(2)
# 如需连字符:new_filename = f"{sid}-{name}.pdf"
new_filename = f"{sid}_{name}.pdf"
html_path = Path(root, file).resolve()
input_uri = html_path.as_uri()
# 计算相对"平时作业"的目录结构,在 output_root 中镜像创建
rel_dir = Path(root).resolve().relative_to(src_root)
target_dir = Path(output_root, rel_dir)
target_dir.mkdir(parents=True, exist_ok=True)
output_path = target_dir / new_filename
if progress_callback:
progress_callback(idx, total_html, f"正在转换: {file} ({idx}/{total_html})")
print(f"处理: {html_path} -> {output_path}")
try:
await page.goto(input_uri)
await page.pdf(path=str(output_path.resolve()))
converted += 1
except Exception as e:
print(f"转换失败: {file}, 异常: {e}")
await browser.close()
print("\n====== 处理完成 ======")
print(f"源目录: {src_root}")
print(f"扫描到 html 总数: {total_html}")
print(f"匹配“10位学号-姓名”规则的 html 数: {matched_html}")
if unmatched_samples:
print("未匹配到学号+姓名规则的示例(最多5个):")
for s in unmatched_samples:
print(" ", s)
print(f"成功转换 pdf 数量: {converted}")
print(f"输出根目录: {Path(output_root).resolve()}")
def run_gui():
"""简单图形界面:选择源文件夹和输出文件夹,然后开始转换"""
root = tk.Tk()
root.title("批量 HTML 转 PDF")
root.geometry("600x380")
root.resizable(False, False)
# 居中窗口
root.update_idletasks()
w = 600
h = 380
ws = root.winfo_screenwidth()
hs = root.winfo_screenheight()
x = int((ws / 2) - (w / 2))
y = int((hs / 2) - (h / 2))
root.geometry(f"{w}x{h}+{x}+{y}")
source_var = tk.StringVar()
output_var = tk.StringVar(value="归档完成_PDF版")
filename_mode_var = tk.StringVar(value="student")
# 修复这里的引号嵌套问题:外单引号,内部使用双引号
status_var = tk.StringVar(value='请选择源/输出文件夹,选择文件命名方式,然后点击"开始转换"')
# 进度条相关
progress_var = tk.DoubleVar()
progress_label_var = tk.StringVar(value="")
def choose_source():
path = filedialog.askdirectory(title="选择包含 HTML 的“平时作业”总目录")
if path:
source_var.set(path)
def choose_output():
path = filedialog.askdirectory(title="选择 PDF 输出根目录(可新建空文件夹)")
if path:
output_var.set(path)
def update_progress(current, total, message):
"""更新进度条和状态(在主线程中调用)"""
if total > 0:
progress_var.set((current / total) * 100)
progress_label_var.set(f"{current}/{total}")
status_var.set(message)
root.update_idletasks()
def run_convert_thread():
"""在后台线程中运行转换任务"""
source = source_var.get().strip()
output = output_var.get().strip()
if not source:
root.after(0, lambda: messagebox.showwarning("提示", "请先选择源文件夹"))
return
if not os.path.exists(source):
root.after(0, lambda: messagebox.showerror("错误", f"源文件夹不存在:\n{source}"))
return
if not output:
root.after(0, lambda: messagebox.showwarning("提示", "请先选择或填写输出文件夹"))
return
# 如果输出目录不存在,可以提前创建
Path(output).mkdir(parents=True, exist_ok=True)
# 禁用按钮
root.after(0, lambda: btn_convert.config(state=tk.DISABLED))
root.after(0, lambda: update_progress(0, 0, "准备开始转换..."))
def progress_callback(current, total, msg):
"""进度回调,在主线程中更新UI"""
root.after(0, lambda: update_progress(current, total, msg))
try:
# 在新的事件循环中运行异步任务
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(convert_all(source, output, filename_mode_var.get(), progress_callback))
loop.close()
root.after(0, lambda: messagebox.showinfo("完成", "全部转换完成!"))
except Exception as e:
root.after(0, lambda: messagebox.showerror("错误", f"转换过程中出现异常:\n{e}"))
finally:
root.after(0, lambda: btn_convert.config(state=tk.NORMAL))
root.after(0, lambda: status_var.set("转换结束,可以重新选择文件夹再次运行。"))
root.after(0, lambda: progress_var.set(0))
root.after(0, lambda: progress_label_var.set(""))
def start_convert():
"""启动转换(在后台线程中运行)"""
# 在新线程中运行,避免阻塞GUI
thread = threading.Thread(target=run_convert_thread, daemon=True)
thread.start()
# ===== 布局 =====
padding_x = 10
padding_y = 8
# 源文件夹
tk.Label(root, text="源文件夹(包含 HTML 的总目录):").grid(
row=0, column=0, sticky="w", padx=padding_x, pady=padding_y
)
tk.Entry(root, textvariable=source_var, width=55).grid(
row=1, column=0, padx=padding_x, pady=0, sticky="w"
)
tk.Button(root, text="浏览...", command=choose_source, width=10).grid(
row=1, column=1, padx=padding_x, pady=0
)
# 输出文件夹
tk.Label(root, text="输出根目录(将按原结构保存 PDF):").grid(
row=2, column=0, sticky="w", padx=padding_x, pady=padding_y
)
tk.Entry(root, textvariable=output_var, width=55).grid(
row=3, column=0, padx=padding_x, pady=0, sticky="w"
)
tk.Button(root, text="浏览...", command=choose_output, width=10).grid(
row=3, column=1, padx=padding_x, pady=0
)
# 文件命名方式
tk.Label(root, text="文件命名方式:").grid(
row=4, column=0, sticky="w", padx=padding_x, pady=padding_y
)
radio_frame = tk.Frame(root)
radio_frame.grid(row=5, column=0, columnspan=2, sticky="w", padx=padding_x, pady=0)
tk.Radiobutton(
radio_frame,
text="学号_姓名.pdf(需文件名匹配 10位学号-姓名.html)",
variable=filename_mode_var,
value="student",
).pack(anchor="w")
tk.Radiobutton(
radio_frame,
text="保持原文件名(去除 .html)",
variable=filename_mode_var,
value="original",
).pack(anchor="w")
# 进度条
progress_frame = tk.Frame(root)
progress_frame.grid(row=6, column=0, columnspan=2, sticky="ew", padx=padding_x, pady=padding_y)
progress_frame.columnconfigure(0, weight=1)
tk.Label(progress_frame, textvariable=progress_label_var, font=("Arial", 9)).grid(
row=0, column=0, sticky="w"
)
progress_bar = ttk.Progressbar(progress_frame, variable=progress_var, maximum=100, length=580)
progress_bar.grid(row=1, column=0, sticky="ew", pady=(5, 0))
# 状态栏
tk.Label(root, textvariable=status_var, fg="blue", wraplength=580, justify="left").grid(
row=7, column=0, columnspan=2, sticky="w", padx=padding_x, pady=padding_y
)
# 开始按钮
btn_convert = tk.Button(root, text="开始转换", command=start_convert, width=12)
btn_convert.grid(row=8, column=0, columnspan=2, pady=padding_y)
root.mainloop()
if __name__ == "__main__":
# 直接运行脚本时,启动 GUI
run_gui()
3.程序下载链接
百度网盘, 提取码: 1234
二、多个pdf合并为一个并加标签
1.问题描述
需要将多个pdf文件合并为一个pdf文件,要求按照学号从小到大排列,标签格式:“序号_学号_姓名”
2.代码
import tkinter as tk
from tkinter import filedialog, messagebox, scrolledtext
from pathlib import Path
from pypdf import PdfReader, PdfWriter
import threading
from PIL import Image, ImageTk
import sys
import os
def get_resource_path(relative_path):
"""获取资源文件的绝对路径,兼容开发环境和打包后的exe"""
try:
# PyInstaller创建临时文件夹,并存储在_MEIPASS中
base_path = sys._MEIPASS
except Exception:
# 开发环境,使用当前文件的目录
base_path = os.path.abspath(os.path.dirname(__file__))
return os.path.join(base_path, relative_path)
def merge_pdfs(folder, output_path, log_callback):
"""合并PDF文件并添加书签"""
try:
writer = PdfWriter()
current_page = 0 # 当前写到第几页,用于书签定位
# 找到该文件夹下所有 .pdf 文件并按文件名排序
pdf_files = sorted(folder.glob("*.pdf"))
if not pdf_files:
log_callback("错误:该文件夹下没有找到任何 .pdf 文件")
return False
# 避免把已生成的合并文件再次合并进去
pdf_files = [p for p in pdf_files if p.name != output_path.name]
if not pdf_files:
log_callback("错误:除了输出文件外,没有其他PDF文件可合并")
return False
log_callback(f"找到 {len(pdf_files)} 个PDF文件,开始合并...")
# 用序号 + 文件名 作为书签名
for idx, pdf_path in enumerate(pdf_files, start=1):
log_callback(f"正在处理 ({idx}/{len(pdf_files)}): {pdf_path.name}")
try:
reader = PdfReader(str(pdf_path))
num_pages = len(reader.pages)
# 追加所有页面
for page in reader.pages:
writer.add_page(page)
# 书签名:序号_文件名(不带 .pdf)
bookmark_title = f"{idx}_{pdf_path.stem}"
writer.add_outline_item(
title=bookmark_title,
page_number=current_page
)
# 更新当前页计数
current_page += num_pages
except Exception as e:
log_callback(f"处理 {pdf_path.name} 时出错: {str(e)}")
return False
# 写出合并后的 PDF
log_callback("正在保存合并后的PDF文件...")
with open(output_path, "wb") as f:
writer.write(f)
log_callback(f"✓ 合并完成!输出文件:{output_path}")
return True
except Exception as e:
log_callback(f"错误:{str(e)}")
return False
class PDFMergerGUI:
def __init__(self, root):
self.root = root
self.root.title("PDF合并加标签工具")
self.root.geometry("700x600")
self.root.resizable(True, True)
# 变量
self.input_folder = tk.StringVar()
self.output_folder = tk.StringVar()
self.logo_image = None # 保存图片引用,防止被垃圾回收
# 创建界面
self.create_widgets()
def create_widgets(self):
# Logo图片区域
frame_logo = tk.Frame(self.root, bg="black", padx=0, pady=0)
frame_logo.pack(fill=tk.X)
try:
# 尝试多种路径来查找logo图片
logo_paths = [
get_resource_path("cbr.png"), # 打包后的路径
Path(__file__).parent / "cbr.png", # 开发环境:同目录
Path(r"F:\code\logo\cbr.png"), # 开发环境:原始路径
]
logo_path = None
for path in logo_paths:
if Path(path).exists():
logo_path = Path(path)
break
if logo_path and logo_path.exists():
# 加载图片
img = Image.open(logo_path)
# 调整图片大小以适应界面宽度(保持宽高比)
img_width = 700
img.thumbnail((img_width, 200), Image.Resampling.LANCZOS)
self.logo_image = ImageTk.PhotoImage(img)
logo_label = tk.Label(frame_logo, image=self.logo_image, bg="black")
logo_label.pack(pady=0)
else:
# 如果图片不存在,显示提示
tk.Label(frame_logo, text="Logo图片未找到", bg="black", fg="white",
font=("微软雅黑", 9)).pack(pady=5)
except Exception as e:
# 如果加载图片失败,显示错误信息
error_frame = tk.Frame(frame_logo, bg="black")
error_frame.pack(pady=5)
tk.Label(error_frame, text=f"加载Logo失败: {str(e)}", bg="black", fg="yellow",
font=("微软雅黑", 9)).pack()
# 输入文件夹选择
frame_input = tk.Frame(self.root, padx=10, pady=10)
frame_input.pack(fill=tk.X)
tk.Label(frame_input, text="请选择需要合并pdf的文件夹:", font=("微软雅黑", 10)).pack(anchor=tk.W)
frame_input_path = tk.Frame(frame_input)
frame_input_path.pack(fill=tk.X, pady=5)
self.entry_input = tk.Entry(frame_input_path, textvariable=self.input_folder,
font=("微软雅黑", 9))
self.entry_input.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=(0, 5))
btn_browse_input = tk.Button(frame_input_path, text="浏览文件夹",
command=self.browse_input_folder,
font=("微软雅黑", 9))
btn_browse_input.pack(side=tk.RIGHT)
# 输出文件夹选择
frame_output = tk.Frame(self.root, padx=10, pady=10)
frame_output.pack(fill=tk.X)
tk.Label(frame_output, text="请选择合并后保存的文件夹:", font=("微软雅黑", 10)).pack(anchor=tk.W)
frame_output_path = tk.Frame(frame_output)
frame_output_path.pack(fill=tk.X, pady=5)
self.entry_output = tk.Entry(frame_output_path, textvariable=self.output_folder,
font=("微软雅黑", 9))
self.entry_output.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=(0, 5))
btn_browse_output = tk.Button(frame_output_path, text="浏览文件夹",
command=self.browse_output_folder,
font=("微软雅黑", 9))
btn_browse_output.pack(side=tk.RIGHT)
# 开始合并按钮
frame_button = tk.Frame(self.root, padx=10, pady=10)
frame_button.pack(fill=tk.X)
self.btn_merge = tk.Button(frame_button, text="开始合并",
command=self.start_merge,
font=("微软雅黑", 12, "bold"),
bg="#4CAF50", fg="white",
relief=tk.RAISED, cursor="hand2")
self.btn_merge.pack(fill=tk.X, pady=5)
# 日志显示区域
frame_log = tk.Frame(self.root, padx=10, pady=10)
frame_log.pack(fill=tk.BOTH, expand=True)
tk.Label(frame_log, text="处理日志:", font=("微软雅黑", 10)).pack(anchor=tk.W)
self.log_text = scrolledtext.ScrolledText(frame_log,
font=("Consolas", 9),
wrap=tk.WORD,
state=tk.DISABLED)
self.log_text.pack(fill=tk.BOTH, expand=True, pady=(5, 0))
def browse_input_folder(self):
"""选择输入文件夹"""
folder = filedialog.askdirectory(title="请选择需要合并pdf的文件夹")
if folder:
self.input_folder.set(folder)
# 如果输出文件夹未设置,自动设置为输入文件夹
if not self.output_folder.get():
self.output_folder.set(folder)
def browse_output_folder(self):
"""选择输出文件夹"""
folder = filedialog.askdirectory(title="请选择合并后保存的文件夹")
if folder:
self.output_folder.set(folder)
def log(self, message):
"""添加日志消息"""
self.log_text.config(state=tk.NORMAL)
self.log_text.insert(tk.END, message + "\n")
self.log_text.see(tk.END)
self.log_text.config(state=tk.DISABLED)
self.root.update_idletasks()
def start_merge(self):
"""开始合并PDF"""
# 验证输入
input_path = self.input_folder.get().strip()
output_folder_path = self.output_folder.get().strip()
if not input_path:
messagebox.showerror("错误", "请选择需要合并pdf的文件夹!")
return
if not output_folder_path:
messagebox.showerror("错误", "请选择合并后保存的文件夹!")
return
folder = Path(input_path)
if not folder.exists():
messagebox.showerror("错误", f"输入文件夹不存在:{input_path}")
return
output_folder = Path(output_folder_path)
if not output_folder.exists():
messagebox.showerror("错误", f"输出文件夹不存在:{output_folder_path}")
return
# 在输出文件夹中生成合并后的PDF文件
output_file_path = output_folder / "merged_with_bookmarks.pdf"
# 清空日志
self.log_text.config(state=tk.NORMAL)
self.log_text.delete(1.0, tk.END)
self.log_text.config(state=tk.DISABLED)
# 禁用按钮
self.btn_merge.config(state=tk.DISABLED, text="处理中...")
# 在新线程中执行合并,避免界面冻结
def merge_thread():
success = merge_pdfs(folder, output_file_path, self.log)
# 在主线程中更新UI
self.root.after(0, lambda: self.merge_completed(success))
thread = threading.Thread(target=merge_thread, daemon=True)
thread.start()
def merge_completed(self, success):
"""合并完成后的回调"""
self.btn_merge.config(state=tk.NORMAL, text="开始合并")
if success:
messagebox.showinfo("成功", "PDF合并完成!")
else:
messagebox.showerror("失败", "PDF合并失败,请查看日志了解详情。")
def main():
root = tk.Tk()
app = PDFMergerGUI(root)
root.mainloop()
if __name__ == "__main__":
main()
3.下载链接
百度网盘 提取码: 1234
总结
1.增加html批量转pdf的程序。2025-12-16





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











