




22 机器学习
词汇
| 函数 | 说明 |
|---|---|
LanguageIdentify[text] | 识别文本的语言 |
ImageIdentify[image] | 识别图像内容 |
TextRecognize[text] | 从图像中识别文本(OCR) |
Classify[training,data] | 根据训练示例对数据进行分类 |
Nearest[list,item] | 查找列表中最接近 item 的元素 |
FindClusters[list] | 找到相似项的簇 |
NearestNeighborGraph[list,n] | 将列表元素与其 n 个最近邻连接 |
Dendrogram[list] | 绘制项之间关系的分层树状图 |
FeatureSpacePlot[list] | 在推断的“特征空间”中绘制元素 |
除了通过编写代码明确指示,Wolfram 语言还能通过观察示例数据来学习完成任务,这正体现了机器学习的核心思想。
预训练函数
先看一些已经用大量示例预训练好的内置函数。
注
Wolfram 语言的机器学习函数会随每次版本更新而改进,所以运行结果可能会与示例略有不同。
多语言识别
LanguageIdentify 可以识别文本所使用的语言。
识别以下每个短语的语言:
In[]:=LanguageIdentify[{ "thank you", "merci", "dar las gracias", "感謝", "благодарить"}]
![]()
文本识别
TextRecognize 可以从图像中识别文本。
先生成一段模糊的文本图像。
创建单词 hello 的图像并对其进行模糊:
In[]:= Blur[Rasterize[Style["hello", 30]], 3]
![]()
尝试识别图像中的文本:

图像识别
ImageIdentify函数能识别图像内容。

注
如果文本或图片很模糊,TextRecognize,ImageIdentify可能无法正确识别。
监督学习
最接近
为了了解分类工作原理先介绍一下最接近函数。
回顾在地理计算一章中曾使用GeoNearest函数,用于查找最近的地理实体。
Nearest函数与GeoNearest函数类似,且更通用,它用于查找列表中最接近所提供项的元素,相当于sklearn中的最近邻knn。
数字
找出列表中最接近 22 的数字:
In[]:= Nearest[{10, 20, 30, 40, 50, 60, 70, 80}, 22]
Out[]={20}
找出最接近的3个数字:
In[]:=Nearest[{10, 20, 30, 40, 50, 60, 70, 80}, 22, 3]
Out[]={20, 30, 10}
单词
它也适用于单词。
在词表中找出与 good 最接近的 10 个单词:
In[]:= Nearest[WordList[ ], "good", 10]
Out[]={good, food, goad, god, gold, goo, goody, goof, goon, goop}
颜色
Nearest 也可以用于颜色。
找出列表中与所给颜色最接近的 3 个颜色:

图像
图像也有“接近性”的概念。
在某种程度上,这就是 ImageIdentify 使用的部分基础。
分类器
通用 Classify函数被训练用于各种类型的分类。
情感识别
例如,可以对文本的进行情感分类。
积极的文本会被判定为正面情感:
In[]:=Classify["Sentiment", "I'm excited"]
Out[]=Positive
消极的文本会被判定为负面情感:
In[]:=Classify["Sentiment", "I'm disapointed"]
Out[]=Negative
注
分类器支持三元情感识别,对于既非正面也非负面的,将被判定为中性Neutral
国旗识别

年龄估计
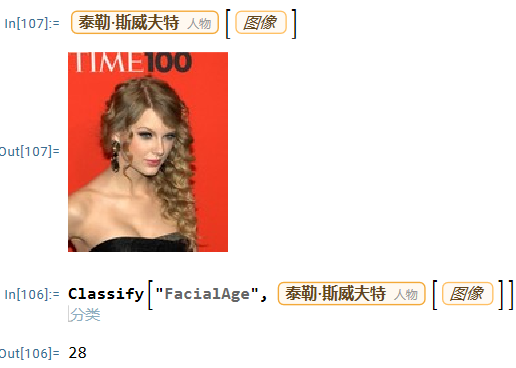
注
以上只展示了Classify的部分功能。
Classify底层使用的并不是单一算法,它会在逻辑回归、朴素贝叶斯、随机森林、支持向量机和神经网络等方法间自动选择。
分类器训练
也可以自己训练 Classify。
下面是一个将手写数字分类为 0 或 1 的简单示例。
给 Classify 一组训练示例,然后给出某个手写数字,它会告诉你该数字是 0 还是 1。
使用训练示例,Classify 正确识别出手写的 0:
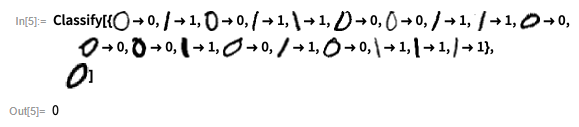
无监督学习
在机器学习中,人们经常给出诸如“猎豹”,“狮子”这样的训练标签。
但有时也会遇到在没有标签的情况下需要把东西分成不同类别的情景。
一种做法是取一组对象(例如颜色),然后找到相似对象的簇。
聚类
FindClusters 可以用找到相似对象的簇。
这把相似颜色聚类到不同列表中:

近邻图
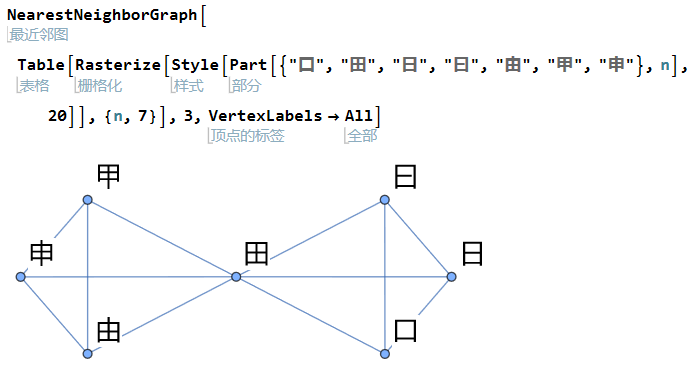
另一种表现方式是把每个颜色连接到列表中最相似的三个颜色,然后把这些连接构造成图(graph)。
NearestNeighborGraph将列表元素与其 n 个最近邻连接。
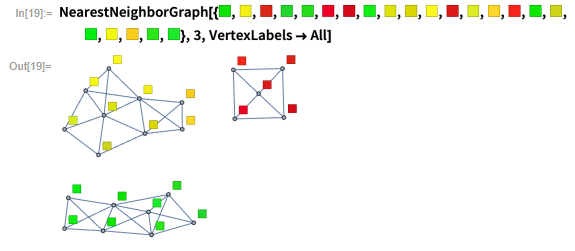
在本示例中,基于“颜色空间”中的接近关系创建,最终得到三个不相连的子图。
以下展示了英语26个字母大小写的字形近邻图。
| 小写字母近邻图 | 大写字母近邻图 |
|---|---|
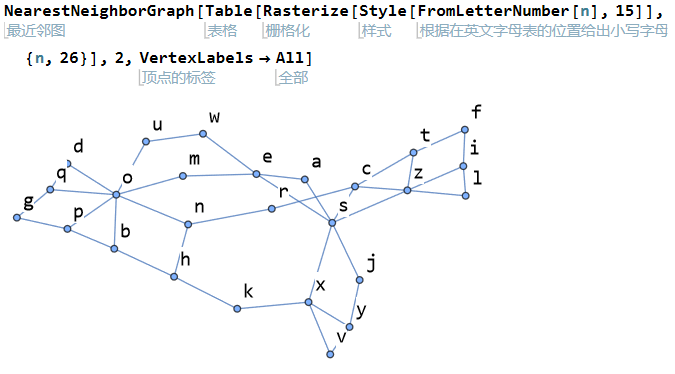 |  |
也可以用近邻图分析汉字字形。
树状图
树状图(dendrogram)是一种树形图,便于查看对象之间的层次接近关系。
Dendrogram绘制项之间关系的分层树状图。
按顺序显示逐步合并的相近颜色:
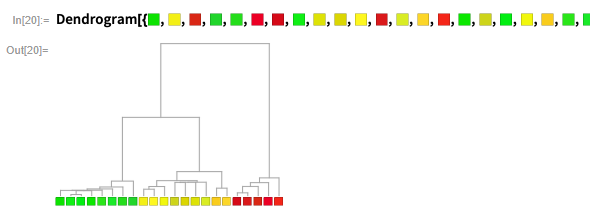
Dendrogram 做分层聚类,可用于生物信息学或历史语言学中的进化树重构。
以下对汉字字形做分层聚类。

特征空间图
当我们比较事物(无论是颜色还是动物照片)时,可以想到识别一些特征以区分它们。
对颜色而言,特征可能是亮度或红色含量;
对动物照片而言,特征可能是毛发的多少或耳朵的尖锐程度。
FeatureSpacePlot 函数对集合中的对象尝试找到它认为“最佳”的区分性特征,然后使用这些特征的数值在图中定位对象。
FeatureSpacePlot 并不直接说明它使用了哪些特征——这些通常很难用语言描述。
但最终结果是 FeatureSpacePlot 会把具有相似特征的对象绘制在相近位置。
颜色
如果使用例如 100 个完全随机选择的颜色,FeatureSpacePlot 同样会把它认为相似的颜色放在一起:
100 个随机颜色经 FeatureSpacePlot 布局:
In[]:=FeatureSpacePlot[RandomColor[100]]

文本
也可以对字母图像做同样的事。
| 小写字母特征空间 | 大写字母特征空间 |
|---|---|
 |  |
结果是外观相近的小写字母(如 y 与 v,或 e 与 c)会聚在一起。而大写字母会有不一样的聚集方式。
对比字母近邻图,可以看到y 与 v是近邻,但 e 与 c却不是。说明特征会聚和近邻有一定的区别。
图片
下面是对猫、汽车和椅子图片的同样处理。

FeatureSpacePlot 会立即把不同种类的物体分离开来,将不同种类的照片放得很远。
FeatureSpacePlot 底层使用了PCA和t-SNE多种降维算法。可以将高维参数表示的数据投影到二维以便可视化。

















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









