关注
关注











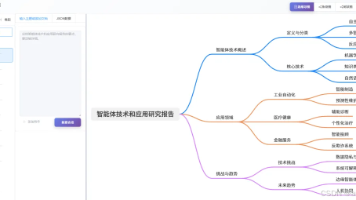
智能体开发实战:用Deepseek做一个生成思维导图的智能体
【摘要】在信息过载时代,一款基于ZAI智能体平台的"智能图表"工具应运而生。该工具利用大语言模型分析文档/网页内容,一键生成思维导图、鱼骨图或树状图,可视化呈现核心观点与逻辑结构。用户可通过上传文档、输入网址或主题三种方式快速获取内容精华,大幅提升阅读效率。该工具仅用一天开发完成,依托Antv/G6框架实现前端渲染,现已在ZAI平台开放体验,帮助用户从海量信息中高效提取关键内容。(150字)
 AI应用探索
AI应用探索  leveldb从入门到精通
leveldb从入门到精通  CUDA并行编程
CUDA并行编程  微信小程序开发
微信小程序开发  信息安全
信息安全  C++开发
C++开发  浏览器插件开发
浏览器插件开发  HTML5从菜鸟到高手 上位机编程
HTML5从菜鸟到高手 上位机编程  C/C++
C/C++  IT视界
IT视界  LDAP协议
LDAP协议  数据库
数据库  职业发展
职业发展  安全认证 驱动开发
安全认证 驱动开发  Aix/Linux
Aix/Linux  研发管理 MFC/QT error解决 性能优化
研发管理 MFC/QT error解决 性能优化  网络协议 图像处理 架构设计 boost学习 逆向工程 人工智能 STL学习 读书笔记 技术创业 PHP入门 远程控制 界面美化 透明加解密 项目管理 CSP Windows开发 虚拟现实
网络协议 图像处理 架构设计 boost学习 逆向工程 人工智能 STL学习 读书笔记 技术创业 PHP入门 远程控制 界面美化 透明加解密 项目管理 CSP Windows开发 虚拟现实  前端开发 互联网 HTML5 生活随想 微信小程序 搞定C++面试 C++设计模式 视频教程
前端开发 互联网 HTML5 生活随想 微信小程序 搞定C++面试 C++设计模式 视频教程 TA关注的专栏 6
TA关注的收藏夹 0
TA关注的社区 3
TA参与的活动 1


AI 镜像开发实战征文活动
随着人工智能技术的飞速发展,AI 镜像开发逐渐成为技术领域的热点之一。Stable Diffusion 3.5 FP8 作为强大的文生图模型,为开发者提供了更高效的图像生成解决方案。为了推动 AI 镜像开发技术的交流与创新,我们特此发起本次征文活动,诚邀广大开发者分享在 Stable Diffusion 3.5 FP8 文生图方向的实战经验和创新应用 本次征文活动鼓励开发者围绕 Stable Diffusion 3.5 FP8 文生图方向,分享以下方面的内容: 1. 技术实践与优化 - Stable Diffusion 3.5 FP8 模型架构解析与优化技巧 - 文生图生成效果的提升方法与技巧 - 模型部署与加速策略,例如使用 Hugging Face、Diffusers 等工具 - 针对特定场景(例如二次元、写实风)的模型微调与定制化开发 2. 应用场景探索 - Stable Diffusion 3.5 FP8 在不同领域的应用案例分享,例如游戏设计、广告创意、艺术创作等 - 利用 Stable Diffusion 3.5 FP8 实现图像编辑、图像修复、图像增强等功能的探索 - 结合其他 AI 技术(例如 NLP、语音识别)构建更强大的应用 3. 创新应用与思考 - 基于 Stable Diffusion 3.5 FP8 的创新应用场景设计 - AI 镜像开发的未来发展方向的思考与展望 - 对 AI 镜像开发伦理、安全等问题的探讨