关注
关注















































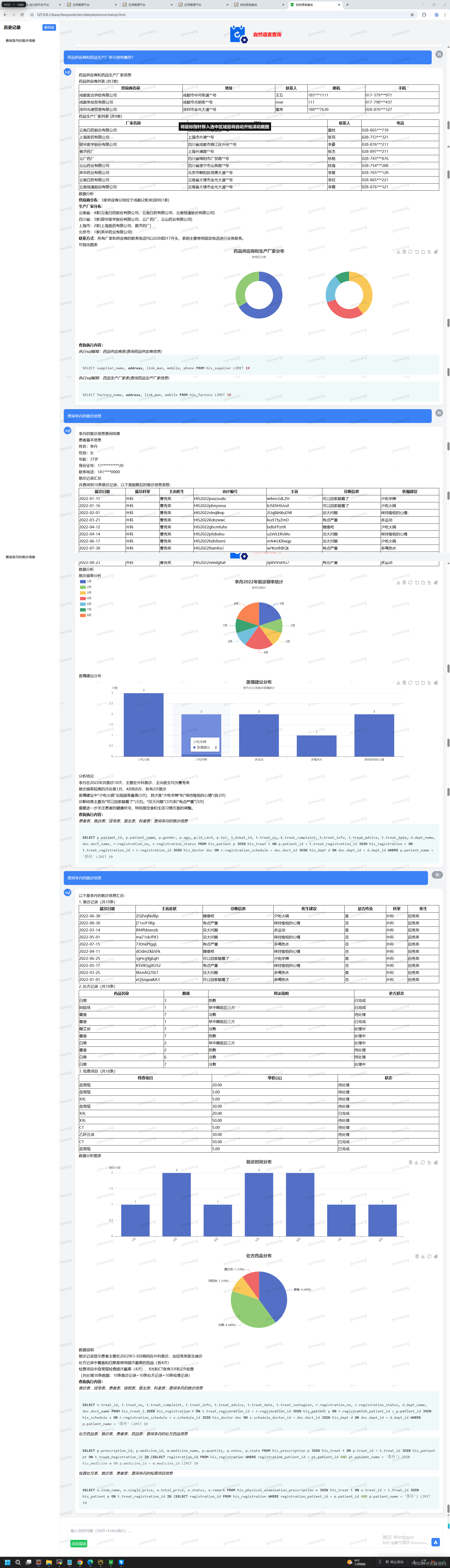
智能语义搜索核心算法:全链路技术解析与工程实践,将rag向量检索准确率提升到98%以上……
智能语义搜索算法全链路解析 本文系统性地介绍了一套面向数据查询的智能语义搜索算法,从数据准备到检索执行完整链路。该算法采用"数据准备为基础、智能语义搜索为核心、动态学习为迭代动力"的设计理念,包含数据准备层和检索执行层两大核心架构。 数据准备层通过构建向量库、领域词典、数据特征和关联关系,为检索提供高质量输入。检索执行层采用四步核心流程:1)查询扩展,通过同义词扩展提升召回率;2)向量生成与搜索,将文本意图转化为高维向量进行高效召回;3)智能重排序,基于多维度相关性得分提升精准率;4)动