关注
关注
















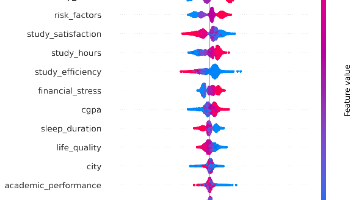
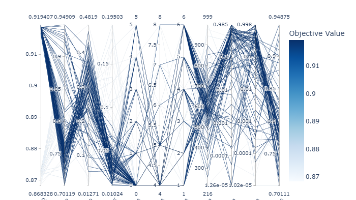
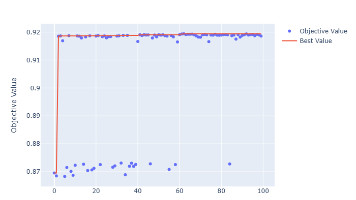
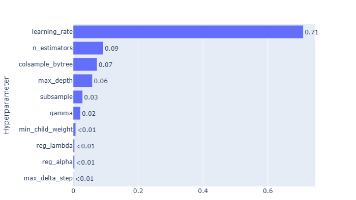
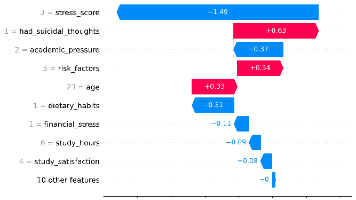
模型理解与可解释性图表案例解读
观察点结论🔥 最关键特征是最核心预测因子📈 主要驱动因素心理压力(学业、经济)是主要风险来源🧍♂️ 人口属性年龄、性别、城市等基本无关紧要🧩 模型合理性符合医学逻辑,具备良好可解释性⚠️ 潜在问题过度依赖自杀意念,需警惕漏诊“本模型识别出‘是否有过自杀念头’为最具影响力的预测因子,占比超过65%,表明该变量在抑郁症筛查中具有决定性作用。其次,学业压力、经济压力和整体压力水平也显著影响预测结果,而性别、年龄等人格特征则贡献微弱。
 机器学习
机器学习  clickhouse
clickhouse  深入浅出JVM虚拟机
深入浅出JVM虚拟机  分布式应用架构
分布式应用架构  SpringBoot
SpringBoot  SpringCloud
SpringCloud  Redis/Memcache
Redis/Memcache  ZooKeeper
ZooKeeper  Elasticsearch/MongoDB
Elasticsearch/MongoDB  Kafka/ActiveMQ/RabbitMQ
Kafka/ActiveMQ/RabbitMQ  多线程并发Thread Linux全面入门 Linux - 软件安装
多线程并发Thread Linux全面入门 Linux - 软件安装  Apache - Tomcat
Apache - Tomcat  Docker
Docker  Nginx
Nginx  MySQL
MySQL  MySQL高级
MySQL高级  Oracle
Oracle  Vue | 小程序
Vue | 小程序  数据结构 | 算法
数据结构 | 算法  Spring 设计模式-REST
Spring 设计模式-REST  Spring Data JPA
Spring Data JPA  SpringMVC
SpringMVC  MyBatis / Plus
MyBatis / Plus  Hibernate
Hibernate  Shiro-SpringSecurity logger
Shiro-SpringSecurity logger  WebService JAVA
WebService JAVA  JavaSE-File-POI IO-NIO-Netty Java网络编程
JavaSE-File-POI IO-NIO-Netty Java网络编程  信息安全与加密解密
信息安全与加密解密  HTML5 | Thymeleaf | Freemarker
HTML5 | Thymeleaf | Freemarker  系统运维 Maven | Jenkins | Gradle SVN/Git/IDEA
系统运维 Maven | Jenkins | Gradle SVN/Git/IDEA  Python | PHP | PLSQL
Python | PHP | PLSQL TA关注的专栏 1
TA关注的收藏夹 0
TA关注的社区 1
TA参与的活动 0


AI 镜像开发实战征文活动
随着人工智能技术的飞速发展,AI 镜像开发逐渐成为技术领域的热点之一。Stable Diffusion 3.5 FP8 作为强大的文生图模型,为开发者提供了更高效的图像生成解决方案。为了推动 AI 镜像开发技术的交流与创新,我们特此发起本次征文活动,诚邀广大开发者分享在 Stable Diffusion 3.5 FP8 文生图方向的实战经验和创新应用 本次征文活动鼓励开发者围绕 Stable Diffusion 3.5 FP8 文生图方向,分享以下方面的内容: 1. 技术实践与优化 - Stable Diffusion 3.5 FP8 模型架构解析与优化技巧 - 文生图生成效果的提升方法与技巧 - 模型部署与加速策略,例如使用 Hugging Face、Diffusers 等工具 - 针对特定场景(例如二次元、写实风)的模型微调与定制化开发 2. 应用场景探索 - Stable Diffusion 3.5 FP8 在不同领域的应用案例分享,例如游戏设计、广告创意、艺术创作等 - 利用 Stable Diffusion 3.5 FP8 实现图像编辑、图像修复、图像增强等功能的探索 - 结合其他 AI 技术(例如 NLP、语音识别)构建更强大的应用 3. 创新应用与思考 - 基于 Stable Diffusion 3.5 FP8 的创新应用场景设计 - AI 镜像开发的未来发展方向的思考与展望 - 对 AI 镜像开发伦理、安全等问题的探讨