I learn about cryptographic vulnerabilities all the time, and they generally fill me with some combination of jealousy (“oh, why didn’t I think of that”) or else they impress me with the brilliance of their inventors. But there’s also another class of vulnerabilities: these are the ones that can’t possibly exist in important production software, because there’s no way anyone could still do that in 2025.
Today I want to talk about one of those ridiculous ones, something Microsoft calls “low tech, high-impact”. This vulnerability isn’t particularly new; in fact the worst part about it is that it’s had a name for over a decade, and it’s existed for longer than that. I’ll bet most Windows people already know this stuff, but I only happened to learn about it today, after seeing a letter from Senator Wyden to Microsoft, describing how this vulnerability was used in the May 2024 ransomware attack on the Ascension Health hospital system.
The vulnerability is called Kerberoasting, and TL;DR it relies on the fact that Microsoft’s Active Directory is very, very old. And also: RC4. If you don’t already know where I’m going with this, please read on.
A couple of updates: The folks on HN pointed out that I was using some incorrect terms in here (sorry!) and added some good notes, so I’m updating below. Also, Tim Medin, who discovered and named the attack, has a great post on it here.
What’s Kerberos, and what’s Active Directory?
Microsoft’s Active Directory (AD) is a many-tentacled octopus that controls access to almost every network that runs Windows machines. The system uses centralized authentication servers to determine who gets access to which network resources. If an employee’s computer needs to access some network Service (a file server, say), an Active Directory server authenticates the user and helps them get securely connected to the Service.
This means that AD is also the main barrier ensuring that attackers can’t extend their reach deeper into a corporate network. If an attacker somehow gets a toehold inside an enterprise (for example, because an employee clicks on a malicious Bing link), they should absolutely not be able to move laterally and take over critical network services. That’s because any such access would require the employee’s machine to have access to specialized accounts (called “Service accounts”) with privileges to fully control those machines. A well-managed network obviously won’t allow this. This means that AD is the “guardian” that stands between most companies and total disaster.
Unfortunately, Active Directory is a monster dragged from the depths of time. It uses the Kerberos protocol, which was first introduced in early 1989. A lot of things have happened since 1989! In fairness to Microsoft, Active Directory itself didn’t actually debut until about 1999; but (in less fairness), large portions of its legacy cryptography from that time period appear to still be supported in AD. This is very bad, because the cryptography is exceptionally terrible.
Let me get specific.
When you want to obtain access to some network resource (a “Service” in AD parlance), you first contact an AD server (called a KDC) to obtain a “ticket” that you can send to the Service to authenticate. This ticket is encrypted using a long-term Service “password” established at the KDC and the Service itself, and it’s handed to the user making the call.
Now, ideally, this Service password is not really a password at all: it’s actually a randomly-generated cryptographic key. Microsoft even has systems in place to generate and rotate these keys regularly. This means the encrypted ticket will be completely inscrutable to the user who receives it, even if they’re malicious. But occasionally network administrators will make mistakes, and one (apparently) somewhat common mistake is to set up a Service that’s connected to an ordinary user account, complete with a human-generated password.
Since human passwords probably are not cryptographically strong, the tickets encrypted using them are extremely vulnerable to cracking. This is very bad, since any random user — including our hypothetical laptop malware hacker — can now obtain a copy of such a ticket, and attempt to crack the Service’s password offline by trying many candidate passwords using a dictionary attack. The result of this is that the user learns an account password that lets them completely control that essential Service. And the result of that (with a few extra steps) is often ransomware.
Isn’t that cute?
That doesn’t actually seem very cute?
Of course, it’s not. It’s actually a terrible design that should have been done away with decades ago. We should not build systems where any random attacker who compromises a single employee laptop can ask for a message encrypted under a critical password! This basically invites offline cracking attacks, which do not need even to be executed on the compromised laptop — they can be exported out of the network to another location and performed using GPUs and other hardware.
There are a few things that can stop this attack in practice. As we noted above, if the account has a long enough (random!) password, then cracking it should be virtually impossible. Microsoft could prevent users from configuring services with weak human-generated passwords, but apparently they don’t — at least because this is something that’s happened many times (including at Ascension Health.)
So let’s say you did not use a strong cryptographic key as your Service’s password. Where are you?
Your best hope in this case is that the encrypted tickets are extremely challenging for an attacker to crack. That’s because at this point, the only thing preventing the attacker from accessing your Service is computing power. But — and this is a very weak “but” — computing power can still be a deterrent! In the “standard” authentication mode, tickets are encrypted with AES, using a key derived using 4,096 iterations of PBKDF2 hashing, based on the Service password and a per-account salt (Update: which is not truly random salt, it’s a combination of domain and principal name.) The salt means an attacker cannot easily pre-compute a dictionary of hashed passwords, and while the PBKDF2 (plus AES) isn’t an amazing defense, it puts some limits on the number of password guesses that can be attempted in a given unit of time.
This page by Chick3nman gives some excellent password cracking statistics computed using an RTX 5090. It implies that a hacker can try 6.8 million candidate passwords every second, using AES-128 and PBKDF2.
So that’s not great. But also not terrible, right?
This isn’t the end of the story. In fact it’s self-evident that this is not the end of the story, because Active Directory was invented in 1999, which means at some point we’ll have to deal with RC4.
Here’s the thing. Anytime you see cryptography born in the 1990s and yet using AES, you cannot be dealing with the original. What you’re looking at is the modernized, “upgraded” version of the original. The original probably used an abacus and witchcraft, or (failing that) at least some combination of unsalted hash functions and RC4. And here’s the worst part: it turns out that in Active Directory, when a user does not configure a Service account to use a more recent mode, then Kerberos will indeed fall back to RC4, combined with unsalted NT hashes (basically, one iteration of MD4.)
The main implication of using RC4 (and NT hashing) is that tickets encrypted this way become hilariously, absurdly fast to crack. According to our friend Chick3nman, the same RTX 5090 can attempt 4.18 billion (with a “b”) password guesses every second. That’s roughly 1000x faster than the AES variant.
As an aside, the NT hashes are not salted, which means they’re vulnerable to pre-computation attacks that involve rainbow tables. I had been meaning to write about rainbow tables recently on this blog, but had convinced myself that they mostly don’t matter, given that these ancient unsalted hash functions are going away. I guess maybe I spoke too soon? Update: see Tom Tervoort’s excellent comment below, which mentions that there is a random 8-byte “confounder” acting as a saltduring key derivation.
So what is Microsoft doing about this?
Clearly not enough. These “Kerberoasting” attacks have been around for ages: the technique and name is credited to Tim Medin who presented it in 2014 (and many popular blogs followed up on it) but the vulnerabilities themselves are much older. The fact that there are practical ransomware attacks using these ideas in 2024 indicates that (1) system administrators aren’t hardening things enough, but more importantly, (2) Microsoft is still not turning off the unsafe options that make these attacks possible.
The recommendations are all kind of dismal. They recommend that administrators should use proper automated key assignment, and if they can’t do that, then to try to pick “really good long passwords”, and if they can’t do that, to pretty please shut off RC4. But Microsoft doesn’t seem to do anything proactive, like absolutely banning obsolete legacy stuff, or being completely obnoxious and forcing admins to upgrade their weird and bad legacy configurations. Instead this all seems much more like a reluctant and half-baked bit of vulnerability management.
I’m sure there are some reasons why this is, but I refuse to believe they’re good reasons, and Microsoft should probably try a lot harder to make sure these obsolete services go away. It isn’t 1999 anymore, and it isn’t even 2014.
If you don’t believe me on these points, go ask Ascension Health.
This is the third and penultimate post in a series about theoretical weaknesses in Fiat-Shamir as applied to proof systems. The first post is here, the second post is here, and you should probably read them.
Over the past two posts I’ve given a bit of background on four subjects: (1) interactive proof systems (for general programs/circuits), (2) the Fiat-Shamir heuristic, (3) random oracles. We’ve also talked about (4) recursive proofs, which will be important but are not immediately relevant.
The KRS result deals with a very common situation that we introduced in the previous post. Namely, that many new proving systems are first developed as interactive protocols (usually called public-coin protocols, or sometimes Sigma protocols.) These protocols fit into a template: first, a Prover first sends a commitment message, then interacts with some (honest) Verifier who “challenges” the Prover in various ways that are specific to the protocol; for each challenge, the Prover must respond correctly, either once or multiple times. The nature of the challenges can vary from scheme to scheme. For now we don’t care about the details: the commonality is that in the interactive setting the Verifier picks its challenges honestly, using real randomness.
In many cases, these protocols are then “flattened” down into a non-interactive proof using the Fiat-Shamir heuristic. The neat thing is that the Prover can run the interactive protocol all by itself, by running a deterministic “copy” of the Verifier. Specifically, the Prover will:
Cryptographically hash its own Commitment message — along with some extra information, such as the input/output and “circuit” (or program, or statement.)1
Use the resulting hash digest bits to sample a challenge.
Compute the Prover’s response to the challenge (many times if the protocol calls for this.)
Publish the whole transcript for anyone to verify.
Protocol designers focus on the interactive setting because it’s relatively easy to analyze the security of the protocol. They can make strong claims about the nature of the challenges that will be chosen, and can then reason about the probability that a cheating Prover can lie in response. The hope with Fiat-Shamir is that, if the hash function is “as good as” a random oracle, it should be nearly as secure as the interactive protocol.
Of course none of this applies to practice. When we deploy the protocol onto a blockchain, we don’t have interactive Verifiers and we certainly don’t have random oracles. Instead we replace the random oracle in Fiat-Shamir with a standard hash function like SHA-3. Whether or not any security guarantees still hold once we do this is an open question. And into the maw of that question is where we shall go.
The GKR15 succinct proof system (but not with details)
The new KRS paper starts by considering a specific interactive proof system designed back in 2015 by Goldwasser, Kalai and Rothblum, which we will refer to as GKR15 (note that the “R” is the not the same in both papers — thanks Aditya!) This is a relatively early result on interactive proving systems and has many interesting theoretical features that we will mostly ignore.
At the surface level, what you need to know about the GKR15 proof system is that it works over arithmetic circuits. The Prover and Verifier agree on a circuit C (which can be thought of as the “program”). The Prover also provides someinput to the circuit x as well as a witnessw, and a purported output y, which ought to satisfy y = C(w, x) if the Prover is honest.
There are some restrictions on the nature of the circuits that can be used in GKR15 — which we will ignore for the purposes of this high-level intuition. The important feature is that the circuits can be relativelydeep. That is to say, they can implement reasonably complex programs, such as cryptographic hashing algorithms.
(The authors of the recent KRS paper also refer to GKR15 as a “popular” scheme. I don’t know how to evaluate that claim. But they cite some features in the protocol that are re-used in more recent proof systems that might be deployed in practice, so let’s go with this!)
The GKR15 scheme (like most proving schemes) is designed to be interactive. All you need to know for the moment is that:
The Prover and Verifier agree on C.
The Prover sends the input and output (x, y) to the Verifier.
It also sends a (polynomial) commitment to the witness w in the first “Commitment” message.
The Verifier picks a random challenge c and the Prover/Verifier interact (multiple times) to do stuff in response to this challenge.
Finally: GKR15 possesses a security analysis (“soundness proof”) that is quite powerful, provided we are discussing the interactive version of the protocol. This argument does not claim GKR15 is “perfect”! It leaves room for some tiny probability that a cheating Prover can get away with its crimes: however, it does bound the probability of successful cheating to something (asymptotically and, presumably, practically with the right parameters) negligible.
Since the GKR15 authors are careful theoretical cryptographers, they don’t suggest that their protocol would be a good fit for Fiat-Shamir. In fact, they hint that this is a problematic idea. But, in the 2015 paper anyway, the don’t actually show there’s a problem with the idea. This leaves open a question: what happens if we do flatten it using Fiat-Shamir? Could bad things happen?
A first thought experiment: “weak challenges”
I am making a deliberate decision to stay “high level” and not dive into the details of the GKR15 system quite yet, not because I think they’re boring and off-putting — ok, it’s partly because I think they’re boring and off-putting — but mostly because I think leading with those details will make understanding more difficult. I promise I’ll get to the details later.
Up here at the abstract level I want to remind us, one final time, what we know. We know that proving systems like GKR15 involve a Verifier making a “challenge” to the Prover, which the Prover must answer successfully. A good proving system should ensure that an honest Prover can answer those challenges successfully — but a cheating Prover (any algorithm that is trying to prove a false statement) will fail to respond correctly to these challenges, at least with overwhelming probability.
Now I want to add a new wrinkle.
Let’s first imagine that the set of all possible challenges a Verifier could issue to a Prover is quite large. For one example: the the challenge might be a random 256-bit string, i.e., there are 2256 to choose from. For fun, let’s further imagine that somewhere within this huge set of possible challenge values there exists a single “weak challenge.” This value c* — which I’ll exemplify by the number “53” for this discussion — is special. A cheating Prover who is fortunate enough to be challenged at this point will always be able to come up with a valid response, even if the statement they are “proving” is totally false (that is, if y is not equal to C(w, x).)
Now it goes without saying that having such a “weak challenge” in your scheme is not great! Clearly we don’t like to have weird vulnerabilities in our schemes. And yet, perhaps it’s not really a problem? To decide, we need to ask: how likely is it that a Verifier will select this weak challenge value?
If we are thinking about the interactive setting with an honest Verifier, the analysis is easy. There are 2256 possible challenge values, and just one “weak challenge” at c* = 53. If the honest Verifier picks challenges uniformly at random, this bad challenge will be chosen with probability 2-256 during one run of the protocol. This is so astronomically improbable that we can more or less pretend it will never happen.
How does Fiat-Shamir handle “bad challenges”?
We now need to think about what happens when we flatten this scheme using Fiat-Shamir.
To do that we need to be more specific about how the scheme will be Fiat-Shamir-ified. In our scheme, we assumed that the Prover will generate a Commitment message first. The deterministic Fiat-Shamir “Verifier” will hash this message using a hash function H, probably tossing in some other inputs just to be safe. For example, it might include the input/output values as well as a hash of the circuit h(C) — note that we’re using a separate hash function out of an abundance of caution. Our challenge will now be computed as follows:
c = H( h(C), x, y, Commitment )
Our strawman protocol has a weak challenge point at c* = 53. So now we should ask: can a cheating Prover somehow convince the Fiat-Shamir hash “Verifier” to challenge them at this weak point?
The good news for Fiat-Shamir is that this also seems pretty difficult. A cheating Prover might want to get itself challenged on c* = 53. But to do this, they’d need to find some input (pre-image) to the hash function H that produces the output “53”. For any hash function worth its salt (pun intended!) this should be pretty difficult!4
Of course, in Fiat-Shamir world, the cheating Prover has a slight advantage: if it doesn’t get the hash challenge it wants, it can always throw away the result and try again. To do this it could formulate a new Commitment message (or even pick a new input/output pair x, y) and then try hashing again. It can potentially repeat this process millions of times! This attack is sometimes called “grinding” and it’s a real attack that actual cheating Provers can run in the real world. Fortunately even grinding isn’t necessarily a disaster: if we assume that the Prover can only compute, say, 250 hashes, then (in the ROM) the probability of finding an input that produces c = 53 is still 250 * 2-256 = 2-206, yet another very unlikely outcome.
Another victory for Fiat-Shamir! Even if we have one or more fixed “weak challenge” points in our protocol, it seems like Fiat-Shamir protects us.
What if a cheating Prover can pick the “weak challenge”?
I realize I’m being exhaustive (or exhausting), but I now want to consider another weird possibility: what if the “bad challenge” value can change when we switch circuits (or even circuit inputs)?
For fun, let’s crank this concern into absolute overdrive. Imagine we’re using a proving system that’s as helpful as possible to the cheating Prover: in this system, the “weak challenge value” will be equal to whatever the real output of the circuit C is. Concretely, if the circuit outputs c* = C(w, x) and alsoc* happens to be challenge value selected by the Verifier, then the Prover can cheat.
(Notice that I’m specifying that this vulnerability depends on the “real” output of the circuit. The prover also sends over a value y, which is the purported output of the circuit that the Prover is claiming, but that might be different if the Prover is cheating.)
In the interactive world this really isn’t an issue. In that setting, the Verifier selects the challenge randomly after the Prover has committed to everything. In that setting, the Prover genuinely cannot “cook” the circuit to produce the challenge value as output (except with a tiny probability.) Our concern is that In Fiat-Shamir world we should be a bit more worried. The value c* is chosen by hashing. A cheating Prover could theoretically compute c* in advance. It now has several options:
The cheater could alter the circuit C so that it hard-codes in c*.
Alternatively, it could feed the value c* (or some function of it) into the circuit via the input x.
It could sneak c* in within the witness w.
Or any combination of the above.
The problem here is that even in Fiat-Shamir world, this attack doesn’t work. A cheating Prover might first pick a circuit C and some input/output x, witness w, and a (purported) output y. It could then compute a Commitment by using the proving scheme’s commitment protocol to commit to w. It will then compute the anticipated Fiat-Shamir challenge as:
c* = H( h(C), x, y, Commitment )
To exploit the vulnerability in our proving system, the cheating Prover must now somehow cause the circuit C to output C(w, x) = c*. However, once again we encounter a problem. The cheating Prover had to feed x, as well as a (commitment to) w and (a hash of) the circuit C into the Fiat-Shamir hash function in order to learn c*. (It should not have been able to predict c* before performing the hash computation above, so it’s extremely unlikely that C(w, x) would just happen to output c*.) However, in order to make C(w, x) output c*, the cheater must subsequently manipulate either (1) the design of C or (2) the circuit’s inputs w, x.
But if the cheating Prover does any of those things, they will be completely foiled. If the cheating Prover changes any of the inputs to the circuit or the Circuit itself after it hashes to learn c*, then the actual Fiat-Shamir challenge used in the protocol will change.3
What if the circuit can compute the “weak challenge” value?
Phew. So what have we learned?
Even if our proving system allows us to literally pick the “weak challenge” c* — have it be the output of the circuit C(w, x) — we cannot exploit this fact very easily. Changing the structure of C, x or wafter we’ve learned c*will cause the actual Fiat-Shamir challenge used to simply hop to a different value, like the timeline of a traveler who goes back in time and kills their own grandfather.
Clearly we need a different strategy: one where none of the inputs to the circuit, or the “code” of the circuit itself, depend on the output of the Fiat-Shamir hash function.
An important observation, and one that is critical to the KRS result, is that the “circuit” we are proving is fundamentally a kind of program that computes things. What if, instead of computing c* and feeding it to the circuit, or hard-coding it within the circuit, we instead design a circuit that itself computes c*?
Let’s look one last time at the way that Fiat-Shamir challenges are computed:
c* = H( h(C), x, y, Commitment)
We are now going to build a circuit C* that is able to compute c* when given the right inputs.
To make this interesting, we are going to design a very silly circuit. It is silly in a specific way: it can never output one specific output, which in this case will be the binary string “BANANAS”. Looking forward, our cheating Prover is then going to try to falsely claim that for some x, w, the relation C*(w, x) = “BANANAS” actually does hold.
Critically, this circuit will contain a copy of the Fiat-Shamir hashing algorithm H() and it will — quite coincidentally — actually output a value that happens to be identical to the Fiat-Shamir challenge (most of the time.) Here’s how it works:
The cheating Prover will pass w and x = ( h(C*), y* = “BANANAS” ) as input.
It will then use the proving system’s commitment algorithm on w to compute Commitment.
The circuit will parse x into its constituent values.
The circuit will internally compute c* = H( h(C*), x, y*, Commitment ).
In the (highly unlikely) case that c* = “BANANAS”, it will set c* = “APPLES”.
Finally, the circuit will output c*.
Notice first that this circuit can never, ever output C*(w, x) = “BANANAS” for any inputs w, x. Indeed, it is incredibly likely that this output would happen to occur naturally after step (4) — how likely is it that a hash function outputs the name of a fruit? — but just to be certain, we have step (5) to reduce this occurrence from “incredibly unlikely” to “absolutely impossible.”
Second, we should observe that the “code” of the circuit above does not in any way depend on c*. We can write this circuit before we ever hash to learn c*! The same goes for the inputs w and x. None of the proposed inputs require the cheating Prover to know c* before it chooses them.
Now imagine that some Prover shows up and tells you that, in fact, they know some w, x such that C*(w, x) = “BANANAS”. By definition they must be lying! When they try to convince you of this using the proving system, a correctly-functioning system should (with overwhelming probability) catch them in their lie and inform you (the Verifier) that the proof is invalid.
However: we stipulated that this particular proving system becomes totally insecure in the special case where the real calculation C*(w, x) happens to equal the Fiat-Shamir challenge c* that will be chosen during the protocol execution. If and when this remarkable event ever happens, the cheating Prover will be able to successfully complete the protocol even if the statement they are proving is totally bogus. And finally it seems we have an exploitable vulnerability! A cheating Prover can show up with the ridiculous false statement that C*(w, x) = “BANANAS”, and then hand us a Fiat-Shamir proof that will verify just fine. They can do this because in real life, C*(w, x) = c* and, thanks to the “weak challenge” feature of the proving system, that Prover successfully answer all the challenges on that point.
And thus in Fiat-Shamir landwe have finally proved a false statement! Note that in the interactive protocol none of this matters, since the Prover cannot predict the Verifier’s (honest) challenge, and so has no real leverage to cheat. In the Fiat-Shamir world — at least when considering this one weird circuit C* — a cheating Prover can get away with murder.
This is not terribly satisfying!
Well, not murder maybe.
I realize this may seem a bit contrived. First we had to introduce a made-up proving system with a “weird” vulnerability, then we exploited it in a very nutty way. And the way we exploited it is kind of silly. But there is a method to the madness. I hope I’ve loaded us up with the basic concepts that we will need to really understand the KRS result.
What remains is to show how the real GKR15 scheme actually maps to some of these ideas.
As a second matter: I started these posts out by proposing all kinds of flashy ideas: we could steal billions of dollars in Ethereum transactions by falsely “proving” that a set of invalid transactions is actually valid! Now having promised the moon, I’m delivering the incredibly lame false statement C*(w, x) = “BANANAS”, where C* is a silly circuit that mostly computes a hash function. This should disappoint you. It disappoints me.
But keep in mind that cryptographic protocols are very delicate. Sometimes an apparently useless vulnerability can be expanded into something that actually matters. It turns out that something similar will apply to this vulnerability, when we apply it to the GKR15 scheme. In the next post.
There will be only one last post, I promise.
Notes:
There is a class of attacks on Fiat-Shamir-ified protocols that stems from putting too little information into the hash function. Usually the weakness here is that the hash does not get fed stuff like “the public key” (in signature schemes), which weakly corresponds to “the circuit” in a proving system. Sneaky attackers can switch these out and do bad thing.
I’ve been extremely casual about the problem of converting hash function outputs into “challenges” for arbitrary protocols. Sometimes this is easy — for example, if the challenge space consists of fixed-length random bit-strings, then we can just pick a hash function with the appropriate output length. Sometimes it is moderately easy, for example if the challenges are sampled from some reasonably-sized field. A few protocols might pick the challenges from genuinely weird distibutions. If you’re annoyed with me on this technical detail, I might stipulate that we have (A) a Fiat-Shamir hash function that outputs (enough) random bits, and (B) a way to convert those bits into whatever form of challenge you need for the protocol.
I said this is not scientific, but clearly we could make some kind of argument in the random oracle model. There we’d argue (something like): assume the scheme is secure using random challenges chosen by an honest (interactive) Verifier, now let’s consider whether it’s possible for the attacker to have pre-queried the oracle on the inputs that will produce the actual Fiat-Shamir. We could then analyze every possible case and hopefully determine that the answer is “no.” And that would be “science.”
In the random oracle model we can convert this intuition into a stronger argument: each time the Prover hashes something for the first time, the oracle effectively samples a uniformly random string as its response. Since there are 2256 possible digests, the probability that it returns c = 53 after one hash attempt should still be 2-256, which again is very low.
Update(April 19): Yilei Chen announced the discovery of a bug in the algorithm, which he does not know how to fix. This was independently discovered by Hongxun Wu and Thomas Vidick. At present, the paper does not provide a polynomial-time algorithm for solving LWE.
If you’re a normal person — that is, a person who doesn’t obsessively follow the latest cryptography news — you probably missed last week’s cryptography bombshell. That news comes in the form of a new e-print authored by Yilei Chen, “Quantum Algorithms for Lattice Problems“, which has roiled the cryptography research community. The result is now being evaluated by experts in lattices and quantum algorithm design (and to be clear, I am not one!) but if it holds up, it’s going to be quite a bad day/week/month/year for the applied cryptography community.
Rather than elaborate at length, here’s quick set of five bullet-points giving the background.
(1) Cryptographers like to build modern public-key encryption schemes on top of mathematical problems that are believed to be “hard”. In practice, we need problems with a specific structure: we can construct efficient solutions for those who hold a secret key, or “trapdoor”, and yet also admit no efficient solution for folks who don’t. While many problems have been considered (and often discarded), most schemes we use today are based on three problems: factoring (the RSA cryptosystem), discrete logarithm (Diffie-Hellman, DSA) and elliptic curve discrete logarithm problem (EC-Diffie-Hellman, ECDSA etc.)
(2) While we would like to believe our favorite problems are fundamentally “hard”, we know this isn’t really true. Researchers have devised algorithms that solve all of these problems quite efficiently (i.e., in polynomial time) — provided someone figures out how to build a quantum computer powerful enough to run the attack algorithms. Fortunately such a computer has not yet been built!
(3) Even though quantum computers are not yet powerful enough to break our public-key crypto, the mere threat of future quantum attacks has inspired industry, government and academia to join forces Fellowship-of-the-Ring-style in order to tackle the problem right now. This isn’t merely about future-proofing our systems: even if quantum computers take decades to build, future quantum computers could break encrypted messages we send today!
(4) One conspicuous outcome of this fellowship is NIST’s Post-Quantum Cryptography (PQC) competition: this was an open competition designed to standardize “post-quantum” cryptographic schemes. Critically, these schemes must be based on different mathematical problems — most notably, problems that don’t seem to admit efficient quantum solutions.
(5) Within this new set of schemes, the most popular class of schemes are based on problems related to mathematical objects called lattices. NIST-approved schemes based on lattice problems include Kyber and Dilithium (which I wrote about recently.) Lattice problems are also the basis of several efficient fully-homomorphic encryption (FHE) schemes.
This background sets up the new result.
Chen’s (not yet peer-reviewed) preprint claims anew quantum algorithm that efficiently solves the “shortest independent vector problem” (SIVP, as well as GapSVP) in lattices with specific parameters. If it holds up, the result could (with numerous important caveats) allow future quantum computers to break schemes that depend on the hardness of specific instances of these problems. The good news here is that even if the result is correct, the vulnerable parameters are very specific: Chen’s algorithm does not immediately apply to the recently-standardized NIST algorithms such as Kyber or Dilithium. Moreover, the exact concrete complexity of the algorithm is not instantly clear: it may turn out to be impractical to run, even if quantum computers become available.
But there is a saying in our field that attacks only get better. If Chen’s result can be improved upon, then quantum algorithms could render obsolete an entire generation of “post-quantum” lattice-based schemes, forcing cryptographers andindustryback to the drawing board.
In other words, both a great technical result — and possibly a mild disaster.
As previously mentioned: I am neither an expert in lattice-based cryptography nor quantum computing. The folks who are those things are very busy trying to validate the writeup: and more than a few big results have fallen apart upon detailed inspection.For those searching for the latest developments, here’s a nice writeup by Nigel Smart that doesn’t tackle the correctness of the quantum algorithm (see updates at the bottom), but does talk about the possible implications for FHE and PQC schemes (TL;DR: bad for some FHE schemes, but really depends on the concrete details of the algorithm’s running time.) And here’s another brief note on a “bug” that was found in the paper, that seems to have been quickly addressed by the author.
Up until this week I had intended to write another long wonky post about complexity theory, lattices, and what it all meant for applied cryptography. But now I hope you’ll forgive me if I hold onto that one, for just a little bit longer.
It’s been a while since I wrote an “attack of the week” post, and the fault for this is entirely mine. I’ve been much too busy writing boring posts about Schnorr signatures! But this week’s news brings an exciting story with both technical and political dimensions: new reports claim that Chinese security agencies have developed a technique to trace the sender of AirDrop transmissions.
Typically my “attack of the week” posts are intended to highlight recent research. What’s unusual about this one is that the attack is not really new; it was discovered way back in 2019, when a set of TU Darmstadt researchers — Heinrich, Hollick, Schneider, Stute, and Weinert — reverse-engineered the Apple AirDrop protocol and disclosed several privacy flaws to Apple. (The resulting paper, which appeared in Usenix Security 2021 can be found here.)
What makes this an attack of the week is a piece of news that was initially reported by Bloomberg (here’s some other coveragewithout paywall) claiming that researchers in China’s Beijing Wangshendongjian Judicial Appraisal Institute have used these vulnerabilities to help police to identify the sender of “unauthorized” AirDrop materials, using a technique based on rainbow tables. While this new capability may not (yet) be in widespread deployment, it represents a new tool that could strongly suppress the use of AirDrop in China and Hong Kong.
And this is a big deal, since AirDrop is apparently one of a few channels that can still be used to disseminate unauthorized protest materials — and indeed, that was used in both places in 2019 and 2022, and (allegedly as a result) has already been subject to various curtailments.
In this post I’m going to talk about the Darmstadt research and how it relates to the news out of Beijing. Finally, I’ll talk a little about what Apple can do about it — something that is likely to be as much of a political problem as a technical one.
As always, the rest of this will be in the “fun” question-and-answer format I use for these posts.
What is AirDrop and why should I care?
Image from Apple. Used without permission.
If you own an iPhone, you already know the answer to this question. Otherwise: AirDrop is an Apple-specific protocol that allows Apple devices to send files (and contacts and other stuff) in a peer-to-peer manner over various wireless protocols, including Bluetooth and WiFi.
The key thing to know about AirDrop is that it has two settings, which can be enabled by a potential receiver. In “Contacts Only” mode, AirDrop will accept files only from people who are in your Contacts list (address book.) When set to “Everyone”, AirDrop will receive files from any random person within transmit range. This latter mode has been extensively used to distribute protest materials in China and Hong Kong, as well as to distribute indecent photos to strangers all over the world.
The former usage of AirDrop became such a big deal in protests that in 2022, Apple pushed a software update exclusively to Chinese users that limited the “Everyone” receive-from mode — ensuring that phones would automatically switch back to “Contacts only” after 10 minutes. The company later extended this software update to all users worldwide, but only after they were extensively criticized for the original move.
Is AirDrop supposed to be private? And how does AirDrop know if a user is in their Contacts list?
While AirDrop is not explicitly advertised as an “anonymous” communication protocol, any system that has your phone talking to strangers has implicit privacy concerns baked into it. This drives many choices around how AirDrop works.
Let’s start with the most important one: do AirDrop senders provide their ID to potential recipients? The answer, at some level, must be “yes.”
The reason for this is straightforward. In order for AirDrop recipients in “Contacts only” mode to check that a sender is in their Contacts list, there must be a way for them to check the sender’s ID. This implies that the sender must somehow reveal their identity to the recipient. And since AirDrop presents a list of possible recipients any time a sending user pops up the AirDrop window, this will happen at “discovery” time — typically before you’ve even decided if you really want to send a file.
But this poses a conundrum: the sender’s phone doesn’t actually know which nearby AirDrop users are willing to receive files from it — i.e., which AirDrop users have the sender in their Contacts — and it won’t know this until it actually talks to them. But talking to them means your phone is potentially shouting at everyone around it all the time, saying something like:
Hi there! My Apple ID is john.doe.28@icloud.com. Will you accept files from me!??
Now forget that this is being done by phones. Instead imagine yourself, as a human being, doing this to every random stranger you encounter on the subway. It should be obvious that this will quickly become a privacy concern, one that would scare even a company that doesn’t care about privacy. But Apple generally does care quite a bit about privacy!
Thus, just solving this basic problem requires a clever way by which phones can figure out whether they should talk to each other — i.e., whether the receiver has the sender in its Contacts — without either side leaking any useful information to random strangers. Fortunately cryptographic researchers have thought a lot about this problem! We’ve even given it a cool name: it’s called Private Set Intersection, or PSI.
To make a long story short: a Private Set Intersection protocol takes a set of strings from the Sender and a set from the Receiver. It gives one (or both) parties the intersection of both sets: that is, the set of entries that appear on both lists. Most critically, a good PSI protocol doesn’t reveal any other information about either of the sets.
In Apple’s case, the Sender would have just a few entries, since you can have a few different email addresses and phone numbers. The Receiver would have a big set containing its entire Contacts list. The output of the protocol would contain either (1) one or more of the Sender’s addresses, or (2) nothing. A PSI protocol would therefore solve Apple’s problem nicely.
Great, so which PSI protocol does Apple use?
The best possible answer to this is: 😔.
For a variety of mildly defensible reasons — which I will come back to in a moment — Apple does not use a secure PSI protocol to solve their AirDrop problem. Instead they did the thing that every software developer does when faced with the choice of doing complicated cryptography or “hacking something together in time for the next ship date”: they threw together their own solution using hash functions.
The TU Darmstadt researchers did a nice job of reverse-engineering Apple’s protocol in their paper. Read it! The important bit happens during the “Discovery” portion of the protocol, which is marked by an HTTPS POST request as shown in the excerpt below:
The very short TL;DR is this:
In the POST request, a sender attaches a truncated SHA-256 hash of its own Apple ID, which is contained within a signed certificate that it gets from Apple. (If the sender has more than one identifier, e.g., a phone number and an email address, this will contain hashes of each one.)
The recipient then hashes every entry in its Contacts list, and compares the results to see if it finds a match.
If the recipient is in Contacts Only mode and finds a match, it indicates this and accepts later file transfers. Otherwise it aborts the connection.
(As a secondary issue, AirDrop also includes a very short [two byte] portion of the same hashes in its BLE advertisements. Two bytes is pretty tiny, which means this shouldn’t leak much information, since many different addresses will collide on a two-byte hash. However, some other researchers have determined that it generally does work well enough to guess identities. Or they may have, the source isn’t translating well for me.)
A second important issue here is that the hash identifiers are apparently stored in logs within the recipient’s phone, which means that to obtain them you don’t have to be physically present when the transfer happens. You can potentially scoop them out of someone else’s phone after the fact.
So what’s the problem?
Many folks who have some experience with cryptography will see the problem immediately. But let’s be explicit.
Hash functions are designed to be one-way. In theory, this means that there is should be no efficient algorithm for “directly” taking the output of a hash function and turning it back into its input. But that guarantee has a huge asterisk: if I can guess a set of possible inputs that could have produced the hash, I can simply hash each one of my guesses and compare it to the target. If one input matches, then chances are overwhelming that I’ve found the right input (also called a pre-image.)
In its most basic form, this naive approach is called a “dictionary attack” based on the idea that one can assemble a dictionary of likely candidates, then test every one. Since these hashes apparently don’t contain any session-dependent information (such as salt), you can even do the hashing in advance to assemble a dictionary of candidate hashes, making the attack even faster.
This approach won’t work if your Apple ID (or phone number) is not guessable. The big question in exploiting this vulnerability is whether it’s possible to assemble a complete list of candidate Apple ID emails and phone numbers. The answer for phone numbers, as the Darmstadt researchers point out, is absolutely yes. Since there are only a few billion phone numbers, it is entirely possible to make a list of every phone number and have a computer grind through them — given a not-unreasonable amount of time. For email addresses this is more complicated, but there are many lists of email addresses in the world, and the Chinese state authorities almost certainly have some good approaches to collecting and/or generating those lists.
As an aside, exploiting these dictionaries can be done in three different ways:
You can make a list of candidate identifiers (or generate them programmatically) and then, given a new target hash, you can hash each identifier and check for a match. This requires you to compute a whole lot of SHA256 hashes for each target you crack, which is pretty fast on a GPU or FPGA (or ASIC) but not optimal.
You can pre-hash the list and make a database of hashes and identifiers. Then when you see a target hash, you just need to do a fast lookup. This means all computation is done once, and lookups are fast. But it requires a ton of storage.
Alternatively, you can use an intermediate approach called a time-memory tradeoff in which you exchange some storage for some computation once the target is found. The most popular technique is called a rainbow table, and it really deserves its own separate blog post, though I will not elaborate today.
The Chinese announcement explicitly mentions a rainbow table, so that’s a good indicator that they’re exploiting this vulnerability.
Well that sucks. What can we, or rather Apple, do about it?
If you’re worried about leaking your identifier, an immediate solution is to turn off AirDrop, assuming such a thing is possible. (I haven’t tried it, so I don’t know if turning this off will really stop your phone from talking to other people!) Alternatively you can unregister your Apple ID, or use a bizarre high-entropy Apple ID that nobody will possibly guess. Apple could also reduce their use of logging.
But those solutions are all terrible.
The proper technical solution is for Apple to replace their hashing-based protocol with a proper PSI protocol, which will — as previously discussed — reveal only one bit of information: whether the receiver has the sender’s address(es) in their Contacts list. Indeed, that’s the solution that the Darmstadt researchers propose. They even devised a Diffie-Hellman-based PSI protocol called “PrivateDrop” and showed that it can be used to solve this problem.
But this is not necessarily an easy solution, for reasons that are both technical and political. It’s worth noting that Apple almost certainly knew from the get-go that their protocol was vulnerable to these attacks — but even if they didn’t, they were told about these issues back in May 2019 by the Darmstadt folks. It’s now 2024, and Chinese authorities are exploiting it. So clearly it was not an easy fix.
Some of this stems from the fact that PSI protocols are more computationally heavy that the hashing-based protocol, and some of it (may) stem from the need for more interaction between each pair of devices. Although these costs are not particularly unbearable, it’s important to remember that phone battery life and BLE/WiFi bandwidth is precious to Apple, so even minor costs are hard to bear. Finally, Apple may not view this as really being an issue.
However in this case there is an even tougher political dimension.
Will Apple even fix this, given that Chinese authorities are now exploiting it?
And here we find the hundred billion dollar question: if Apple actually replaced their existing protocol with PrivateDrop, would that be viewed negatively by the Chinese government?
Those of us on the outside can only speculate about this. However, the facts are pretty worrying: Apple has enormous manufacturing and sales resources located inside of China, which makes them extremely vulnerable to an irritated Chinese government. They have, in the past, taken actions that appeared to be targeted at restricting AirDrop use within China — and although there’s no definitive proof of their motivations, it certainly looked bad.
Hence there is a legitimate question about whether it’s politically wise for Apple to make a big technical improvement to their AirDrop privacy, right at the moment that the lack of privacy is being viewed as an asset by authorities in China. Even if this attack isn’t really that critical to law enforcement within China, the decision to “fix” it could very well be seen as a slap in the face.
One hopes that despite all these concerns, we’ll soon see a substantial push to improve the privacy of AirDrop. But I’m not going to hold my breath.
This week a group of global newspapers is running a series of articlesdetailingabuses of NSO Group’s Pegasus spyware. If you haven’t seen any of these articles, they’re worth reading — and likely will continue to be so as more revelations leak out. The impetus for the stories is a leak comprising more than 50,000 phone numbers that are allegedly the targets of NSO’s advanced iPhone/Android malware.
Notably, these targets include journalists and members of various nations’ political opposition parties — in other words, precisely the people who every thinking person worried would be the target of the mass-exploitation software that NSO sells. And indeed, that should be the biggest lesson of these stories: the bad thing everyone said would happen now has.
This is a technical blog, so I won’t advocate for, say, sanctioning NSO Group or demanding answers from theluminaries on NSO’s “governance and compliance” committee. Instead I want to talk a bit about some of the technical lessons we’ve learned from these leaks — and even more at a high level, precisely what’s wrong with shrugging these attacks away.
We should all want perfect security!
Don’t feel bad, targeted attacks are super hard!
A perverse reaction I’ve seen from some security experts is to shrug and say “there’s no such thing as perfect security.” More concretely, some folks argue, this kind of well-resourced targeted attack is fundamentally impossible to prevent — no matter how much effort companies like Apple put into stopping it.
And at the extremes, this argument is not wrong. NSO isn’t some script-kiddy toy. Deploying it costs hundreds of thousands of dollars, and fighting attackers with that level of resources is always difficult. Plus, the argument goes, even if we raise the bar for NSO then someone with even more resources will find their way into the gap — perhaps charging an even more absurd price. So let’s stop crapping on Apple, a company that works hard to improve the baseline security of their products, just because they’re failing to solve an impossible problem.
Still that doesn’t mean today’s version of those products are doing everything they could be to stop attacks. There is certainly more that corporations like Apple and Google could be doing to protect their users. However, the only way we’re going to get those changes is if we demand them.
Not all vectors are created equal
Because spyware is hard to capture, we don’t know precisely how Pegasus works. The forensic details we do have come from an extensive investigation conducted by Amnesty International’s technology group. They describe a sophisticated infection process that proved capable of infecting a fully-patched iPhone 12 running the latest version of Apple’s iOS (14.6).
Many attacks used “network injection” to redirect the victim to a malicious website. That technique requires some control of the local network, which makes it hard to deploy to remote users in other countries. A more worrying set of attacks appear to use Apple’s iMessage to perform “0-click” exploitation of iOS devices. Using this vector, NSO simply “throws” a targeted exploit payload at some Apple ID such as your phone number, and then sits back and waits for your zombie phone to contact its infrastructure.
This is really bad. While cynics are probably correct (for now) that we probably can’t shut down every avenue for compromise, there’s good reason to believe we can close down a vector for 0-interaction compromise. And we should try to do that.
What can we do to make NSO’s life harder?
What we know that these attacks take advantage of fundamental weaknesses in Apple iMessage: most critically, the fact that iMessage will gleefully parse all sorts of complex data received from random strangers, and will do that parsing using crappy libraries written in memory unsafe languages. These issues are hard to fix, since iMessage can accept so many data formats and has been allowed to sprout so much complexity over the past few years.
There is good evidence that Apple realizes the bind they’re in, since they tried to fix iMessage by barricading it behind a specialized “firewall” called BlastDoor. But firewalls haven’t been particularly successful at preventing targeted network attacks, and there’s no reason to think that BlastDoor will do much better. (Indeed, we know it’s probably not doing its job now.)
Adding a firewall is the cheap solution to the problem, and this is probably why Apple chose this as their first line of defense. But actually closing this security hole is going to require a lot more. Apple will have to re-write most of the iMessage codebase in some memory-safe language, along with many system libraries that handle data parsing. They’ll also need to widely deploy ARM mitigations like PAC and MTE in order to make exploitation harder. All of this work has costs and (more importantly) risks associated with it — since activating these features can break all sorts of things, and people with a billion devices can’t afford to have .001% of them crashing every day.
An entirely separate area is surveillance and detection: Apple already performs some remote telemetry to detect processes doing weird things. This kind of telemetry could be expanded as much as possible while not destroying user privacy. While this wouldn’t necessarily stop NSO, it would make the cost of throwing these exploits quite a bit higher — and make them think twice before pushing them out to every random authoritarian government.
It’s the scale, stupid
Critics are correct that fixing these issues won’t stop exploits. The problem that companies like Apple need to solve is not preventing exploits forever, but a much simpler one: they need to screw up the economics of NSO-style mass exploitation.
Targeted exploits have been around forever. What makes NSO special is not that they have some exploits. Rather: NSO’s genius is that they’ve done something that attackers were never incentivized to do in this past: democratize access to exploit technology. In other words, they’ve done precisely what every “smart” tech business is supposed to do: take something difficult and very expensive, and make it more accessible by applying the magic of scale. NSO is basically the SpaceX of surveillance.
But this scalability is not inevitable.
NSO can afford to maintain a 50,000 number target list because the exploits they use hit a particular “sweet spot” where the risk of losing an exploit chain — combined with the cost of developing new ones — is low enough that they can deploy them at scale. That’s why they’re willing to hand out exploitation to every idiot dictator — because right now they think they can keep the business going even if Amnesty International or CitizenLab occasionally catches them targeting some human rights lawyer.
But companies like Apple and Google can raise both the cost and risk of exploitation — not just everywhere, but at least on specific channels like iMessage. This could make NSO’s scaling model much harder to maintain. A world where only a handful of very rich governments can launch exploits (under very careful vetting and controlled circumstances) isn’t a great world, but it’s better than a world where any tin-pot authoritarian can cut a check to NSO and surveil their political opposition or some random journalist.
So how do we get to that world?
In a perfect world, US and European governments would wake up and realize that arming authoritarianism is really is bad for democracy — and that whatever trivial benefit they get from NSO is vastly outweighed by the very real damage this technology is doing to journalism and democratic governance worldwide.
But I’m not holding my breath for that to happen.
In the world I inhabit, I’m hoping that Ivan Krstić wakes up tomorrow and tells his bosses he wants to put NSO out of business. And I’m hoping that his bosses say “great: here’s a blank check.” Maybe they’ll succeed and maybe they’ll fail, but I’ll bet they can at least make NSO’s life interesting.
But Apple isn’t going to do any of this if they don’t think they have to, and they won’t think they have to if people aren’t calling for their heads. The only people who can fix Apple devices are Apple (very much by their own design) and that means Apple has to feel responsible each time an innocent victim gets pwned while using an Apple device. If we simply pat Apple on the head and say “gosh, targeted attacks are hard, it’s not your fault” then this is exactly the level of security we should expect to get — and we’ll deserve it.
I haven’t written an “attack of the week” post in a while, and it’s been bumming me out. This is not because there’s been a lack of attacks, but mostly because there hasn’t been an attack on something sufficiently widely-used that it can rouse me out of my blogging torpor.
But today brings a beautiful attack called ReVoLTE, on a set of protocols that I particularly love to see get broken: namely, cellular protocols. And specifically, the (voice over) LTE standards. I’m excited about these particular protocols — and this new attack — because it’s so rare to see actual cellular protocols and implementations get broken. This is mostly because these standards are developed in smoke-filled rooms and written up in 12,000 page documents that researchers never have the energy to deal with. Moreover, implementing the attacks requires researchers to mess with gnarly radio protocols.
And so, serious cryptographic vulnerabilities can spread all over the world, presumably only exploited by governments, before a researcher actually takes a look at them. But every now and then there’s an exception, and today’s attack is one of them.
The attack itself is by David Rupprecht, Katharina Kohls, Thorsten Holz, and Christina Pöpper at RUB and NYU Abu Dhabi. It’s a lovely key re-installation attack on a voice protocol that you’re probably already using, assuming you’re one of the older generation who still make phone calls using a cellular phone.
Let’s start with some background.
What is LTE, and what is VoLTE?
The basis for our modern cellular telephony standards began in Europe back in the 1980s, with a standard known as Global System for Mobile. GSM was the first major digital cellular telephony standard, and it introduced a number of revolutionary features such as the use of encryption to protect phone calls. Early GSM was designed primarily for voice communications, although data could be sent over the air at some expense.
As data became more central to cellular communications, the Long Term Evolution (LTE) standards were devised to streamline this type of communication. LTE builds on a group of older standards such as GSM, EDGE and HSPA to make data communication much faster. There’s a lot of branding and misbranding in this area, but the TL;DR is that LTE is a data communications system that serves as a bridge between older packet data protocols and future 5G cellular data technologies.
Of course, history tells us that once you have enough (IP) bandwidth, concepts like “voice” and “data” start to blur together. The same is true with modern cellular protocols. To make this transition smoother, the LTE standards define Voice-over-LTE (VoLTE), which is an IP-based standard for transmitting voice calls directly over the data plane of the LTE system, bypassing the circuit-switched portion of the cellular network entirely. As with standard VoIP calls, VoLTE calls can be terminated by the cellular provider and connected to the normal phone network. Or (as is increasingly common) they can be routed directly from one cellular customer to another, even across providers.
Like standard VoIP, VoLTE is based on two popular IP-based protocols: Session Initiation Protocol (SIP) for call establishment, and Real Time Transport Protocol (which should be called RTTP but is actually called RTP) to actually handle voice data. VoLTE also adds some additional bandwidth optimizations, such as header compression.
Ok, what does this have to do with encryption?
Like GSM before it, LTE has a standard set of cryptographic protocols for encrypting packets while they travel over the air. These are mainly designed to protect your data while it travels between your handset (called the “User Equipment”, or UE) and the cellular tower (or wherever your provider decides to terminate the connection.) This is because cellular providers view outside eavesdroppers as the enemy, not themselves. Obviously.
(However, the fact that VoLTE connections can occur directly between customers on different provider networks does mean that the VoLTE protocol itself has some additional and optional encryption protocols that can happen at higher network layers. These aren’t relevant to the current paper except insofar as they could screw things up. We’ll talk about them briefly further below.)
Historical GSM encryption had many weaknesses: bad ciphers, protocols where only the handset authenticated itself to the tower (meaning an attacker could impersonate a tower, giving rise to the “Stingray“) and so on. LTE fixed many of the obvious bugs, while keeping a lot of the same structure.
Let’s start with the encryption itself. Assuming key establishment has already happened — and we’ll talk about that in just a minute — each data packet is encrypted using a stream cipher mode using some cipher called “EEA” (which in practice can be implemented with things like AES). The encryption mechanism is basically CTR-mode, as shown below:
Basic encryption algorithm for VoLTE packets (source: ReVoLTE paper). EEA is a cipher, “COUNT’ is a 32-bit counter, “BEARER” is a unique session identifier that separates VoLTE connections from normal internet traffic. And “DIRECTION” indicates whether the traffic is going from UE to tower or vice-versa.
Since the encryption algorithm itself (EEA) can be implemented using a strong cipher like AES, it’s unlikely that there’s any direct attack on the cipher itself, as there was back in the GSM days. However, even with a strong cipher, it’s obvious that this encryption scheme is a giant footgun waiting to go off.
CTR mode nonce re-use attacks were a thing when Poison was a thing.
Specifically: the LTE standard uses an (unauthenticated) stream cipher with a mode that will be devastatingly vulnerable should the counter — and other inputs, such as ‘bearer’ and ‘direction’ — ever be re-used. In modern parlance the term for this concept is “noncere-use attack“, but the potential risks here are not modern. They’re well-known and ancient, going back to the days of hair-metal and even disco.
In fairness, the LTE standards says “don’t re-use these counters, please“. But the LTE standards are also like 7,000 pages long, and anyway, this is like begging toddlers not to play with a gun. Inevitably, they’re going to do that and terrible things will happen. In this case, the discharging gun is a keystream re-use attack in which two different confidential messages get XORed with the same keystream bytes. This is known to be utterly devastating for message confidentiality.
So what’s ReVoLTE?
The ReVoLTE attack paper points out that, indeed, this highly vulnerable encryption construction is in fact, misused by real equipment in the wild. Specifically, the authors analyze actual VoLTE calls made using commercial equipment, and show that they can exploit something called a “key re-installation attack”. (Much credit for the basic observation goes to Raza and Lu, who first pointed out the potential vulnerability. But the ReVoLTE research turns it into a practical attack.)
Let me give a quick overview of the attack here, although you should really read the paper.
You might assume that once LTE sets up a packet data connection, voice-over-LTE is just a question of routing voice packets over that connection alongside all of your other data traffic. In other words, VoLTE would be a concept that exists only above Layer 2. This isn’t precisely the case.
In fact, LTE’s data link layer introduces the concept of a “bearer“. Bearers are separate session identifiers that differentiate various kinds of packet traffic. Normal Internet traffic (your Twitter and Snapchat) goes over one bearer. SIP signalling for VoIP goes over another, and voice traffic packets are handled on a third. I don’t have much insight into the RF and network routing mechanisms of LTE, but I presume this is done because LTE networks want to enable quality of service mechanisms to ensure that these different packet flows are treated with different priority levels: i.e., your crummy TCP connections to Facebook can be prioritized at a lower level than your real-time voice calls.
This isn’t exactly a problem, but it raises an issue. Keys for LTE encryption are derived separately each time a new “bearer” is set up. In principle this should happen afresh each time you make a new phone call. This would result in a different encryption key for each call, thus eliminating the possibility that the same key will be re-used to encrypt two different sets of call packets. Indeed, the LTE standard says something like “you should use a different key each time you set up a new bearer to handle a new phone call.” But that doesn’t mean it happens.
In fact, in real implementations, two different calls that happen in close temporal proximity will end up using the exact same key — despite the fact that new (identically-named) bearers are configured between them. The only practical change that happens between those calls is that the encryption counter will reset back to zero. In the literature, this is sometimes called a key reinstallation attack. One can argue that this is basically an implementation error, although in this case the risks seem largely set up by the standard itself.
In practice, this attack leads to keystream re-use where an attacker can obtain the encrypted packets and , which allows her to compute . Even better, if the attacker knows one of or , she can immediately recover the other. This gives her a strong incentive to knowone of the two plaintexts.
This brings us to the complete and most powerful attack scenario. Consider an attacker who can eavesdrop the radio connection between a target phone and the cellular tower, and who somehow gets “lucky enough” to record two different calls where the second happens immediately subsequent to the other. Now imagine she can somehow can guess the plaintext contents of one of the calls. In this eventuality, our attacker can completely decrypt the first call, using a simple XOR evaluation between the two sets of packets.
And of course, as it happens — luck has nothing to do with it. Since phones are designed to receive calls, an attacker who can eavesdrop that first call will be able to initiate a second call at exactly moment the first call ends. This second call, should it re-use the same encryption key with a counter set back to zero, will enable plaintext recovery. Even better, since our attacker actually controls the data in the second call, she may be able to recover the contents of the first one — pending a whole lot of implementation-specific details all breaking in her favor.
Here’s a picture of the overall attack, taken from the paper:
Attack overview from the ReVoLTE paper. This diagram assumes that two different calls happen using the same key. The attacker controls a passive sniffer (top left) as well as a second handset that they can use to make a second call to the victim phone.
So does the attack actually work?
At one level, this is really the entire question for the ReVoLTE paper. All of the ideas above sound great in theory, but they leave a ton of questions. Such as:
Is it feasible for (academic researchers) to actually sniff VoLTE connections?
Do real LTE systems actually re-install keys?
Can you actually initiate that second call quickly and reliably enough to make a handset and tower re-use a key?
Even if systems do re-install keys, can you actually know the digital plaintext of the second call — given that things like codecs and transcoding may totally change the (bitwise) contents of that second call, even if you have access to the “bits” flowing out of your attacker phone?
The ReVoLTE paper answers several of these questions in the affirmative. The authors are able to use a commercial software-defined radio downlink sniffer called Airscope in order to eavesdrop the downlink side of a VoLTE call. (As is typical with academic research, I expect that simply getting hold of the software and figuring out how to work it took months off some poor graduate students’ lives.)
In order for key re-use to happen, the researchers discovered that a second call has to occur very rapidly after the termination of the first one, but not too rapidly — about ten seconds for the providers they experimented with. Fortunately, it doesn’t really matter if the target picks the call up within that time — the “ringing”, i.e., SIP communication itself causes the provider to re-use the same key.
Many of the gnarliest issues thus revolve around issue (4), obtaining all of the plaintext bits for the attacker-initiated call. This is because a lot of things can happen to your plaintext as it travels from your attacker handset out to the victim’s phone and through the cellular network. These include nastiness such as transcoding of encoded audio data, which makes the audio sound the same but totally changes the binary representation of the audio. LTE networks also use RTP header compression that can substantially change big portions of the RTP packet.
Finally, packets sent by the attacker need to roughly line up with packets that happened in the first phone call. This can be problematic, as silent patches in a phone call result in shorter messages (called comfort noise), which may not overlap well with the original call.
The “real world attack” section of the paper is worth reading for all the details. It addresses many of the above concerns — specifically, the authors find that some codecs are not transcoded, and that roughly 89% of the binary representation of the target call can be recovered, for at least two European providers that the attackers tested.
This is an astonishingly high level of success, and frankly much better than I anticipated when I started the paper.
So what can we do to fix this?
The immediate answer to this question is straightforward: since the vulnerability is a key re-use (re-installation) attack, just fix this attack. Make sure to derive a new key for each phone call, and never allow your packet counter to reset back to zero with the same key. Problem solved!
Or maybe not. Getting this right will require upgrading a lot of equipment, and frankly the fix itself isn’t terribly robust. It would be nice if standards could find a cleaner way to implement their encryption modes that isn’t instantly and catastrophically vulnerable to these nonce-reuse issues.
One possible direction is to use modes of encryption where nonce-misuse doesn’t result in catastrophic outcomes. This might be too expensive for some current hardware, but it’s certainly a direction that designers should be thinking about for the future, particular as the 5G standards are about to take over the world.
This new result also raises a general question about why the same damned attacks keep cropping up in standard after standard, many of which use very similar designs and protocols. At a certain point when you’ve had this same key re-installation issue happen in multiple widely-deployed protocols such as WPA2, maybe it’s time to make your specifications and testing procedures more robust to it? Stop treating implementers as thoughtful partners who will pay attention to your warnings, and treat them as (inadvertent) adversaries who are inevitably going to implement everything incorrectly.
Or alternatively, we can do what the Facebooks and Apples of the world are increasingly doing: make voice call encryption happen at a higher level of the OSI network stack, without relying on cellular equipment manufacturers to get anything right. We could even promote end-to-end encryption of voice calls, as WhatsApp and Signal and FaceTime do, assuming the US government would just stop trying to trip us up. Then (with the exception of some metadata) many of these problems would go away. This solution is particularly pertinent in a world where governments aren’t even sure if they trust their equipment providers.
Alternatively, we could just do what our kids have already done: and just stop answering those annoying voice calls altogether.
A few days ago I had the pleasure of hosting Kenny Paterson, who braved snow and historic cold (by Baltimore standards) to come talk to us about encrypted databases.
Kenny’s newest result is with first authors Paul Grubbs, Marie-Sarah Lacharité and Brice Minaud (let’s call it GLMP). It isn’t so much about building encrypted databases, as it is about the risks of building them badly. And — for reasons I will get into shortly — there have been a lot of badly-constructed encrypted database schemes going around. What GLMP point out is that this weakness isn’t so much a knock against the authors of those schemes, but rather, an indication that they may just be trying to do the impossible.
Hopefully this is a good enough start to get you drawn in. Which is excellent, because I’m going to need to give you a lot of background.
What’s an “encrypted” database, and why are they a problem?
Databases (both relational and otherwise) are a pretty important part of the computing experience. Modern systems make vast use of databases and their accompanying query technology in order to power just about every software application we depend on.
Because these databases often contain sensitive information, there has been a strong push to secure that data. A key goal is to encrypt the contents of the database, so that a malicious database operator (or a hacker) can’t get access to it if they compromise a single machine. If we lived in a world where security was all that mattered, the encryption part would be pretty easy: database records are, after all, just blobs of data — and we know how to encrypt those. So we could generate a cryptographic key on our local machine, encrypt the data before we upload it to a vulnerable database server, and just keep that key locally on our client computer.
Voila: we’re safe against a database hack!
The problem with this approach is that encrypting the database records leaves us with a database full of opaque, unreadable encrypted junk. Since we have the decryption key on our client, we can decrypt and read those records after we’ve downloaded them. But this approach completely disables one of the most useful features of modern databases: the ability for the database server itself to search (or query) the database for specific records, so that the client doesn’t have to.
Unfortunately, standard encryption borks search capability pretty badly. If I want to search a database for, say, employees whose salary is between $50,000 and $100,000, my database is helpless: all it sees is row after row of encrypted gibberish. In the worst case, the client will have to download all of the data rows and search them itself — yuck.
This has led to much wailing and gnashing of teeth in the database community. As a result, many cryptographers (and a distressing number of non-cryptographers) have tried to fix the problem with “fancier” crypto. This has not gone very well.
It would take me a hundred years to detail all of various solutions that have been put forward. But let me just hit a few of the high points:
Some proposals have suggested using deterministic encryption to encrypt database records. Deterministic encryption ensures that a given plaintext will always encrypt to a single ciphertext value, at least for a given key. This enables exact-match queries: a client can simply encrypt the exact value (“John Smith”) that it’s searching for, and ask the database to identify encrypted rows that match it.
Of course, exact-match queries don’t support more powerful features. Most databases also need to support range queries. One approach to this is something called order revealing encryption (or its weaker sibling, order preserving encryption). These do exactly what they say they do: they allow the database to compare two encrypted records to determine which plaintext is greater than the other.
Some people have proposed to use trusted hardware to solve these problems in a “simpler” way, but as we like to say in cryptography: if we actually had trusted hardware, nobody would pay our salaries. And, speaking more seriously, even hardware might not stop the leakage-based attacks discussed below.
This summary barely scratches the surface of this problem, and frankly you don’t need to know all the details for the purpose of this blog post.
What you do need to know is that each of the above proposals entails has some degree of “leakage”. Namely, if I’m an attacker who is able to compromise the database, both to see its contents and to see how it responds when you (a legitimate user) makes a query, then I can learn something about the data being queried.
What some examples of leakage, and what’s a leakage function?
Leakage is a (nearly) unavoidable byproduct of an encrypted database that supports queries. It can happen when the attacker simply looks at the encrypted data, as she might if she was able to dump the contents of your database and post them on the dark web. But a more powerful type of leakage occurs when the attacker is able to compromise your database server and observe the query interaction between legitimate client(s) and your database.
Take deterministic encryption, for instance.
Deterministic encryption has the very useful, but also unpleasant feature that the same plaintext will always encrypt to the same ciphertext. This leads to very obvious types of leakage, in the sense that an attacker can see repeated records in the dataset itself. Extending this to the active setting, if a legitimate client queries on a specific encrypted value, the attacker can see exactly which records match the attacker’s encrypted value. She can see how often each value occurs, which gives and indication of what value it might be (e.g., the last name “Smith” is more common than “Azriel”.) All of these vectors leak valuable information to an attacker.
Other systems leak more. Order-preserving encryption leaks the exact order of a list of underlying records, because it causes the resulting ciphertexts to have the same order. This is great for searching and sorting, but unfortunately it leaks tons of useful information to an attacker. Indeed, researchers have shown that, in real datasets, an ordering can be combined with knowledge about the record distribution in order to (approximately) reconstruct the contents of an encrypted database.
Fancier order-revealing encryption schemes aren’t quite so careless with your confidentiality: they enable the legitimate client to perform range queries, but without leaking the full ordering so trivially. This approach can leak less information: but a persistent attacker will still learn some data from observing a query and its response — at a minimum, she will learn which rows constitute the response to a query, since the database must pack up the matching records and send them over to the client.
If you’re having trouble visualizing what this last type of leakage might look like, here’s a picture that shows what an attacker might see when a user queries an unencrypted database vs. what the attacker might see with a really “good” encrypted database that supports range queries:
So the TL;DR here is that many encrypted database schemes have some sort of “leakage”, and this leakage can potentially reveal information about (a) what a client is querying on, and (b) what data is in the actual database.
But surely cryptographers don’t build leaky schemes?
Sometimes the perfect is the enemy of the good.
Cryptographers could spend a million years stressing themselves to death over the practical impact of different types of leakage. They could also try to do things perfectly using expensive techniques like fully-homomorphic encryption and oblivious RAM — but the results would be highly inefficient. So a common view in the field is researchers should do the very best we can, and then carefully explain to users what the risks are.
For example, a real database system might provide the following guarantee:
“Records are opaque. If the user queries for all records BETWEEN some hidden values X AND Y then all the database will learn is the row numbers of the records that match this range, and nothing else.”
This is a pretty awesome guarantee, particularly if you can formalize it and prove that a scheme achieves it. And indeed, this is something that researchers have tried to do. The formalized description is typically achieved by defining something called a leakage function. It might not be possible to prove that a scheme is absolutely private, but we can prove that it only leaks as much as the leakage function allows.
Now, I may be overdoing this slightly, but I want to be very clear about this next part:
Proving your encrypted database protocol is secure with respect to a specific leakage function does not mean it is safe to use in practice. What it means is that you are punting that questionto the application developer, who is presumed to know how this leakage will affect their dataset and their security needs. Your leakage function and proof simply tell the app developer what information your scheme is (provably) going to protect, and what it won’t.
The obvious problem with this approach is that application developers probably don’t have any idea what’s safe to use either. Helping them to figure this out is one goal of this new GLMP paper and its related work.
So what leaks from these schemes?
GLMP don’t look at a specific encryption scheme. Rather, they ask a more general question: let’s imagine that we can only see that a legitimate user has made a range query — but not what the actual queried range values are. Further, let’s assume we can also see which records the database returns for that query, but not their actual values.
How much does just this information tell us about the contents of the database?
You can see that this is a very limited amount of leakage. Indeed, it is possibly the least amount of leakage you could imagine for any system that supports range queries, and is also efficient. So in one sense, you could say authors are asking a different and much more important question: are any of these encrypted databases actually secure?
The answer is somewhat worrying.
Can you give me a simple, illuminating example?
Let’s say I’m an attacker who has compromised a database, and observes the following two range queries/results from a legitimate client:
Query 1: SELECT * FROM Salaries BETWEEN ⚙️ and 🕹 Result 1: (rows 1, 3, 5) Query 2: SELECT * FROM Salaries BETWEEN 😨 and 🎱 Result 2: (rows 1, 43, 3, 5)
Here I’m using the emoji to illustrate that an attacker can’t see the actual values submitted within the range queries — those are protected by the scheme — nor can she see the actual values of the result rows, since the fancy encryption scheme hides all this stuff. All the attacker sees is that a range query came in, and some specific rows were scooped up off disk after running the fancy search protocol.
So what can the attacker learn from the above queries? Surprisingly: quite a bit.
At very minimum, the attacker learns that Query 2 returned all of the same records as Query 1. Thus the range of the latter query clearly somewhat overlaps with the range of the former. There is an additional record (row 43) that is not within the range of Query 1. That tells us that row 43 must must be either the “next” greater or smaller record than each of rows (1, 3, 5). That’s useful information.
Get enough useful information, it turns out that it starts to add up. In 2016, Kellaris, Kollios, Nissim and O’Neill showed that if you know the distribution of the query range endpoints — for example, if you assumed that they were uniformly random — then you can get more than just the order of records. You can reconstruct the exact value of every record in the database.
This result is statistical in nature. If I know that the queries are uniformly random, then I can model how often a given value (say, Age=34 out of a range 1-120) should be responsive to a given random query results. By counting the actual occurrences of a specific row after many such queries, I can guess which rows correlate to specific record values. The more queries I see, the more certain I can be.The Kellaris et al. paper shows that this takes queries, where N is the number of possible values your data can take on (e.g., the ages of your employees, ranging between 1 and 100 would give N=100.) This is assuming an arbitrary dataset. The results get much better if the database is “dense”, meaning every possible value occurs once.
In practice the Kellaris et al. results mean that database fields with small domains (like ages) could be quickly reconstructed after observing a reasonable number of queries from a legitimate user, albeit one who likes to query everything randomly.
So that’s really bad!
The main bright spot in this research —- at least up until recently — was that many types of data have much larger domains. If you’re dealing with salary data ranging from, say, $1 to $200,000, then N=200,000 and this dominant tends to make Kellaris et al. attacks impractical, simply because they’ll take too long. Similarly, data like employee last names (encoded as a form that can be sorted and range-queries) gives you even vaster domains like , say, and so perhaps we could pleasantly ignore these results and spend our time on more amusing engagements.
I bet we can’t ignore these results, can we?
Indeed, it seems that we can’t. The reason we can’t sit on our laurels and hope for an attacker to die of old age recovering large-domain data sets is due to something called approximate database reconstruction, or ADR.
The setting here is the same: an attacker sits and watches an attacker make (uniformly random) range queries. The critical difference is that this attacker isn’t trying to get every database record back at its exact value: she’s willing to tolerate some degree of error, up to an additive . For example, if I’m trying to recover employee salaries, I don’t need them to be exact: getting them within 1% or 5% is probably good enough for my purposes. Similarly, reconstructing nearly all of the letters in your last name probably lets me guess the rest, especially if I know the distribution of common last names.
Which finally brings us to this new GLMP paper, which puts ADR on steroids. What it shows is that the same setting, if one is willing to “sacrifice” a few of the highest and lowest values in the database, an attacker can reconstruct nearly the full database in a much smaller (asymptotic) number of queries, specifically: queries, where is the error parameter.
The important thing to notice about these results is that the value N has dropped out of the equation. The only term that’s left is the error term . That means these results are “scale-free”, and (asymptotically, at least), they work just as well for small values of N as large ones, and large databases and small ones. This is really remarkable.
Big-O notation doesn’t do anything for me: what does this even mean?
Big-O notation is beloved by computer scientists, but potentially meaningless in practice. There could be huge constants in these terms that render these attacks completely impractical. Besides, weird equations involving epsilon characters are impossible for humans to understand.
Sometimes the easiest way to understand a theoretical result is to plug some actual numbers in and see what happens. GLMP were kind enough to do this for us, by first generating several random databases — each containing 1,000 records, for different values of N. They then ran their recovery algorithm against a simulated batch of random range queries to see what the actual error rate looked like as the query count increased.
Here are their results:
Experimental results (Figure 2) from Grubbs et al. (GLMP, 2019). The Y-axis represents the measured error between the reconstructed database and the actual dataset (smaller is better.) The X-axis represents the number of queries. Each database contains 1,000 records, but there are four different values of N tested here. Notice that the biggest error occurs around the very largest and smallest values in the dataset, so the results are much better if one is willing to “sacrifice” these values.
Even after just 100 queries, the error in the dataset has been hugely reduced, and after 500 queries the contents of the database — excluding the tails — can be recovered with only about a 1-2% error rate.
Moreover, these experimental results illustrate the fact that recovery works at many scales: that is, they work nearly as well for very different values of N, ranging from 100 to 100,000. This means that the only variable you really need to think about as an attacker is: how close do I need my reconstruction to be? This is probably not very good news for any real data set.
How do these techniques actually work?
The answer is both very straightforward and deeply complex. The straightforward part is simple; the complex part requires an understanding of Vapnik-Chervonenkis learning theory (VC-theory) which is beyond the scope of this blog post, but is explained in the paper.
At the very highest level the recovery approach is similar to what’s been done in the past: using response probabilities to obtain record values. This paper does it much more efficiently and approximately, using some fancy learning theory results while making a few assumptions.
At the highest level: we are going to assume that the range queries are made on random endpoints ranging from 1 to N. This is a big assumption, and more on it later! Yet with just this knowledge in hand, we learn quite a bit. For example: we can compute the probability that a potential record value (say, the specific salary $34,234) is going to be sent back, provided we know the total value lies in the range 1-N (say, we know all salaries are between $1 and $200,000).
If we draw the resulting probability curve in freehand, it might look something like the chart below. This isn’t actually to scale or (probably) even accurate, but it illustrates a key point: by the nature of (random) range queries, records near the center are going to have a higher overall chance of being responsive to any given query, since the “center” values are more frequently covered by random ranges, and records near the extreme high- and low values will be chosen less frequently.
I drew this graph freehand to mimic a picture in Kenny’s slides. Not a real plot!
The high-level goal of database reconstruction is to match the observed response rate for a given row (say, row 41) to the number of responses we’d expect see for different specific concrete values in the range. Clearly the accuracy of this approach is going to depend on the number of queries you, the attacker, can observe — more is better. And since the response rates are lower at the highest and lowest values, it will take more queries to guess outlying data values.
You might also notice that there is one major pitfall here. Since the graph above is symmetric around its midpoint, the expected response rate will be the same for a record at .25*N and a record at .75*N — that is, a $50,000 salary will be responsive to random queries at precisely same rate as a $150,000 salary. So even if you get every database row pegged precisely to its response rate, your results might still be “flipped” horizontally around the midpoint. Usually this isn’t the end of the world, because databases aren’t normally full of unstructured random data — high salaries will be less common than low salaries in most organizations, for example, so you can probably figure out the ordering based on that assumption. But this last “bit” of information is technically not guaranteed to come back, minus some assumptions about the data set.
Thus, the recovery algorithm breaks down into two steps: first, observe the response rate for each record as random range queries arrive. For each record that responds to such a query, try to solve for a concrete value that minimizes the difference between the expected response rate on that value, and the observed rate. The probability estimation can be made more efficient (eliminating a quadratic term) by assuming that there is at least one record in the database within the range .2N-.3N (or .7N-.8N, due to symmetry). Using this “anchor” record requires a mild assumption about the database contents.
What remains is to show that the resulting attack is efficient. You can do this by simply implementing it — as illustrated by the charts above. Or you can prove that it’s efficient. The GLMPpaper uses some very heavy statistical machinery to do the latter. Specifically, they make use of a result from Vapnik-Chervonenkis learning theory (VC-theory), which shows that the bound can be derived from something called the VC-dimension (which is a small number, in this case) and is unrelated to the actual value of N. That proof forms the bulk of the result, but the empirical results are also pretty good.
Is there anything else in the paper?
Yes. It gets worse. There’s so much in this paper that I cannot possibly include it all here without risking carpal tunnel and boredom, and all of it is bad news for the field of encrypted databases.
The biggest additional result is one that shows that if all you want is an approximate ordering of the database rows, then you can do this efficiently using something called a PQ tree. Asymptotically, this requires queries, and experimentally the results are again even better than one would expect.
What’s even more important about this ordering result is that it works independently of the query distribution. That is: we do not need to have random range queries in order for this to work: it works reasonably well regardless of how the client puts its queries together (up to a point).
Even better, the authors show that this ordering, along with some knowledge of the underlying database distribution — for example, let’s say we know that it consists of U.S. citizen last names — can also be used to obtain approximate database reconstruction. Oy vey!
And there’s still even more:
The authors show how to obtain even more efficient database recovery in a setting where the query range values are known to the attacker, using PAC learning. This is a more generous setting than previous work, but it could be realistic in some cases.
Finally, they extend this result to prefix and suffix queries, as well as range queries, and show that they can run their attacks on a dataset from the Fraternal Order of Police, obtaining record recovery in a few hundred queries.
In short: this is all really bad for the field of encrypted databases.
In all seriousness: database encryption has been a controversial subject in our field. I wish I could say that there’s been an actual debate, but it’s more that different researchers have fallen into different camps, and nobody has really had the data to make their position in a compelling way. There have actually been some very personal arguments made about it.
The schools of thought are as follows:
The first holds that any kind of database encryption is better than storing records in plaintext and we should stop demanding things be perfect, when the alternative is a world of constant data breaches and sadness.
To me this is a supportable position, given that the current attack model for plaintext databases is something like “copy the database files, or just run a local SELECT * query”, and the threat model for an encrypted database is “gain persistence on the server and run sophisticated statistical attacks.” Most attackers are pretty lazy, so even a weak system is probably better than nothing.
The countervailing school of thought has two points: sometimes the good is much worse than the perfect, particularly if it gives application developers an outsized degree of confidence of the security that their encryption system is going to provide them.
If even the best encryption protocol is only throwing a tiny roadblock in the attacker’s way, why risk this at all? Just let the database community come up with some kind of ROT13 encryption that everyone knows to be crap and stop throwing good research time into a problem that has no good solution.
I don’t really know who is right in this debate. I’m just glad to see we’re getting closer to having it.
On Monday a team of researchers from Münster, RUB and NXP disclosed serious cryptographic vulnerabilities in a number of encrypted email clients. The flaws, which go by the cute vulnerability name of “Efail”, potentially allow an attacker to decrypt S/MIME or PGP-encrypted email with only minimal user interaction.
By the standards of cryptographic vulnerabilities, this is about as bad as things get. In short: if an attacker can intercept and alter an encrypted email — say, by sending you a new (altered) copy, or modifying a copy stored on your mail server — they can cause many GUI-based email clients to send the full plaintext of the email to an attacker controlled-server. Even worse, most of the basic problems that cause this flaw have been known for years, and yet remain in clients.
The big (and largely under-reported) story of EFail is the way it affects S/MIME. That “corporate” email protocol is simultaneously (1) hated by the general crypto community because it’s awful and has a slash in its name, and yet (2) is probably the most widely-used email encryption protocol in the corporate world. The table at the right — excerpted from the paper — gives you a flavor of how Efail affects S/MIME clients. TL;DR it affects them very badly.
Efail also happens to affect a smaller, but non-trivial number of OpenPGP-compatible clients. As one might expect (if one has spent time around PGP-loving folks) the disclosure of these vulnerabilities has created something of a backlash on HN, and among people who make and love OpenPGP clients. Mostly for reasons that aren’t very defensible.
So rather than write about fun things — like the creation of CFB and CBC gadgets — today, I’m going to write about something much less exciting: the problem of vulnerabilitydisclosure in ecosystems like PGP. And how bad reactions to disclosure can hurt us all.
How Efail was disclosed to the PGP community
Putting together a comprehensive timeline of the Efail disclosure process would probably be a boring, time-intensive project. Fortunately Thomas Ptacek loves boring and time-intensive projects, and has already done this for us.
Briefly, the first Efail disclosures to vendors began last October, more than 200 days prior to the agreed publication date. The authors notified a large number of vulnerable PGP GUI clients, and also notified the GnuPG project (on which many of these projects depend) by February at the latest. From what I can tell every major vendor agreed to make some kind of patch. GnuPG decided that it wasn’t their fault, and basically stopped corresponding.
All parties agreed not to publicly discuss the vulnerability until an agreed date in April, which was later pushed back to May 15. The researchers also notified the EFF and some journalists under embargo, but none of them leaked anything. On May 14 someone dumped the bug onto a mailing list. So the EFF posted a notice about the vulnerability (which we’ll discuss a bit more below), and the researchers put up a website. That’s pretty much the whole story.
There are three basic accusations going around about the Efail disclosure. They can be summarized as (1) maintaining embargoes in coordinated disclosures is really hard, (2) the EFF disclosure “unfairly” made this sound like a serious vulnerability “when it isn’t”, and (3) everything was already patched anyway so what’s the big deal.
Disclosures are hard; particularly coordinated ones
I’ve been involved in two disclosures of flaws in open encryption protocols. (Both were TLS issues.) Each one poses an impossible dilemma. You need to simultaneously (a) make sure every vendor has as much advance notice as possible, so they can patch their software. But at the same time (b)you need to avoid tellingliterallyanyone, because nothing on the Internet stays secret. At some point you’ll notify some FOSS project that uses an open development mailing list or ticket server, and the whole problem will leak out into the open.
Disclosing bugs that affect PGP is particularly fraught. That’s because there’s no such thing as “PGP”. What we have instead is a large and distributed community that revolves around the OpenPGP protocol. The pillar of this community is the GnuPG project, which maintains the core GnuPG tool and libraries that many clients rely on. Then there are a variety of niche GUI-based clients and email plugin projects. Finally, there are commercial vendors like Apple and Microsoft. (Who are mostly involved in the S/MIME side of things, and may reluctantly allow PGP plugins.)
Then, of course there are thousands of end-users, who will generally fail to update their software unless something really bad and newsworthy happens.
The obvious solution to the disclosure problem to use a staged disclosure. You notify the big commercial vendors first, since that’s where most of the affected users are. Then you work your way down the “long tail” of open source projects, knowing that inevitably the embargo could break and everyone will have to patch in a hurry. And you keep in mind that no matter what happens, everyone will blame you for screwing up the disclosure.
For the PGP issues in Efail, the big client vendors are Mozilla (Thunderbird), Microsoft (Outlook) and maybe Apple (Mail). The very next obvious choice would be to patch the GnuPG tool so that it no longer spits out unauthenticated plaintext, which is the root of many of the problems in Efail.
The Efail team appears to have pursued exactly this approach for the client-side vulnerabilities. Sadly, the GnuPG team made the decision that it’s not their job to pre-emptively address problems that they view as ‘clients misusing the GnuPG API’ (my paraphrase), even when that misuse appears to be rampant across many of the clients that use their tool. And so the most obvious fix for one part of the problem was not available.
This is probably the most unfortunate part of the Efail story, because in this case GnuPG is very much at fault. Their API does something that directly violates cryptographic best practices— namely, releasing unauthenticated plaintext prior to producing an error message. And while this could be understood as a reasonable API design at design time, continuing to support this API even as clients routinely misuse it has now led to flaws across the ecosystem. The refusal of GnuPG to take a leadership role in preemptively safeguarding these vulnerabilities both increases the difficulty of disclosing these flaws, and increases the probability of future issues.
So what went wrong with the Efail disclosure?
Despite what you may have heard, given the complexity of this disclosure, very little went wrong. The main issues people have raised seem to have to do with the contents of an EFF post. And with some really bad communications from Robert J. Hansen at the Enigmail (and GnuPG) project.
The EFF post. The Efail researchers chose to use the Electronic Frontier Foundation as their main source for announcing the existence of the vulnerability to the privacy community. This hardly seems unreasonable, because the EFF is generally considered a trusted broker, and speaks to the right community (at least here in the US).
The EFF post doesn’t give many details, nor does it give a list of affected (or patched) clients. It does give two pretty mild recommendations:
Temporarily disable or uninstall your existing clients until you’ve checked that they’re patched.
Maybe consider using a more modern cryptosystem like Signal, at least until you know that your PGP client is safe again.
This naturally led to a huge freakout by many in the PGP community. Some folks, including vendors, have misrepresented the EFF post as essentially pushing people to “permanently” uninstall PGP, which will “put lives at risk” because presumably these users (whose lives are at risk, remember) will immediately fall back to sending incriminating information via plaintext emails — rather than temporarily switching their communications to one of several modern, well-studied secure messengers, or just not emailing for a few hours.
The most reasonable criticism I’ve heard of the EFF post is that it doesn’t give many details about which clients are patched, and which are vulnerable. This could presumably give someone the impression that this vulnerability is still present in their email client, and thus would cause them to feel less than secure in using it.
I have to be honest that to me that sounds like a really good outcome. The problem with Efail is that it doesn’t matter if your client is secure. The Efail vulnerability could affect you if even a single one of your communication partners is using an insecure client.
So needless to say I’m not very sympathetic to the reaction around the EFF post. If you can’t be sure whether your client is secure, you probably should feel insecure.
Bad communications from GnuPG and Enigmail. On the date of the disclosure, anyone looking for accurate information about security from two major projects — GnuPG and Enigmail — would not have been able to find it.
They wouldn’t have found it because developers from both Enigmail and GnuPGwere on mailing lists and Twitter claiming that they had never heard of Efail, and hadn’t been notified by the researchers. Needless to say, these allegations took off around the Internet, sometimes in place of real information that could have helped users (like, whether either project had patched.)
It goes without saying that neither allegation was actually true. In fact, both project members soon checked with their fellow developers (and their memories) and found out that they’d both been given months of notice by the researchers, and that Enigmail had even developed a patch. (However, it turned out that even this patch may not perfectly address the issue, and the community is still working to figure out exactly what still needs to be done.)
This is an understandable mistake, perhaps. But it sure is a bad one.
PGP is bad technology and it’s making a bad community
Now that I’ve made it clear that neither the researchers nor the EFF is out to get the PGP community, let me put on my mask and horns and tell you why someone should be.
I’ve written extensively about PGP on this blog, but in the past I’ve written mostly from a technical point of view about the problems with PGP. But what’s really problematic about PGP is not just the cryptography; it’s the story it tells about path dependence and how software communities work.
The fact of the matter is that OpenPGP is not really a cryptography project. That is, it’s not held together by cryptography. It’s held together by backwards-compatibility and (increasingly) a kind of an obsession with the idea of PGP as an end in and of itself, rather than as a means to actually make end-users more secure.
Let’s face it, as a protocol, PGP/OpenPGP is just not what we’d develop if we started over today. It was formed over the years out of mostly experimental parts, which were in turn replaced, bandaged and repaired — and then worked into numerous implementations, which all had to be insanely flexible and yet compatible with one another. The result is bad, and most of the software implementing it is worse. It’s the equivalent of a beloved antique sports car, where the electrical system is totally shot, but it still drives. You know, the kind of car where the owner has to install a hand-switch so he can turn the reverse lights on manually whenever he wants to pull out of a parking space.
If PGP went away, I estimate it would take the security community less than a year to entirely replace (the key bits of) the standard with something much better and modern. It would have modern crypto and authentication, and maybe even extensions for future post-quantum future security. It would be simple. Many bright new people would get involved to help write the inevitable Rust, Go and Javascript clients and libraries.
Unfortunately for us all, (Open)PGP does exist. And that means that even fancy greenfield email projects feel like they need to support OpenPGP, or at least some subset of it. This in turn perpetuates the PGP myth, and causes other clients to use it. And as a direct result, even if some clients re-implement OpenPGP from scratch, other clients will end up using tools like GnuPG which will support unauthenticated encryption with bad APIs. And the cycle will go round and around, like a spaceship stuck near the event horizon of a black hole.
And as the standard perpetuates itself, largely for the sake of being a standard, it will fail to attract new security people. It will turn away exactly the type of people who should be working on these tools. Those people will go off and build encryption systems in a totally different area, or they’ll get into cryptocurrency. And — with some exceptions — the people who work in the community will increasingly work in that community because they’re supporting PGP, and not because they’re trying to seek out the best security technologies for their users. And the serious (email) users of PGP will be using it because they like the idea of using PGP better than they like using an actual, secure email standard.
And as things get worse, and fail to develop, people who work on it will become more dogmatic about its importance, because it’s something threatened and not a real security protocol that anyone’s using. To me that’s where PGP is going today, and that is why the community has such a hard time motivating itself to take these vulnerabilities seriously, and instead reacts defensively.
Maybe that’s a random, depressing way to end a post. But that’s the story I see in OpenPGP. And it makes me really sad.
In Fall 2016 I was invited to come to Miami as part of a team that independently validated some alleged flaws in implantable cardiac devices manufactured by St. Jude Medical (now part of Abbott Labs). These flaws were discovered by a company called MedSec. The story got a lot of traction in the press at the time, primarily due to the fact that a hedge fund called Muddy Waters took a large short position on SJM stock as a result of these findings. SJM subsequently sued both parties for defamation. The FDA later issued a recall for many of the devices.
Due in part to the legal dispute (still ongoing!), I never had the opportunity to write about what happened down in Miami, and I thought that was a shame: because it’s really interesting. So I’m belatedly putting up this post, which talks a bit MedSec’s findings, and implantable device security in general.
By the way: “we” in this case refers to a team of subject matter experts hired by Bishop Fox, and retained by legal counsel for Muddy Waters investments. I won’t name the other team members here because some might not want to be troubled by this now, but they did most of the work — and their names can be found in this public expert report (as can all the technical findings in this post.)
Quick disclaimers: this post is my own, and any mistakes or inaccuracies in it are mine and mine alone. I’m not a doctor so holy cow this isn’t medical advice. Many of the flaws in this post have since been patched by SJM/Abbot. I was paid for my time and travel by Bishop Fox for a few days in 2016, but I haven’t worked for them since. I didn’t ask anyone for permission to post this, because it’s all public information.
A quick primer on implantable cardiac devices
Implantable cardiac devices are tiny computers that can be surgically installed inside a patient’s body. Each device contains a battery and a set of electrical leads that can be surgically attached to the patient’s heart muscle.
When people think about these devices, they’re probably most familiar with the cardiacpacemaker. Pacemakers issue small electrical shocks to ensure that the heart beats at an appropriate rate. However, the pacemaker is actually one of the least powerful implantable devices. A much more powerful type of device is the Implantable Cardioverter-Defibrillator (ICD). These devices are implanted in patients who have a serious risk of spontaneously entering a dangerous state in which their heart ceases to pump blood effectively. The ICD continuously monitors the patient’s heart rhythm to identify when the patient’s heart has entered this condition, and applies a series of increasingly powerful shocks to the heart muscle to restore effective heart function. Unlike pacemakers, ICDs can issue shocks of several hundred volts or more, and can both stop and restart a patient’s normal heart rhythm.
Like most computers, implantable devices can communicate with other computers. To avoid the need for external data ports – which would mean a break in the patient’s skin – these devices communicate via either a long-range radio frequency (“RF”) or a near-field inductive coupling (“EM”) communication channel, or both. Healthcare providers use a specialized hospital device called a Programmer to update therapeutic settings on the device (e.g., program the device, turn therapy off). Using the Programmer, providers can manually issue commands that cause an ICD to shock the patient’s heart. One command, called a “T-Wave shock” (or “Shock-on-T”) can be used by healthcare providers to deliberately induce ventrical fibrillation. This capability is used after a device is implanted, in order to test the device and verify it’s functioning properly.
Because the Programmer is a powerful tool – one that could cause harm if misused – it’s generally deployed in a physician office or hospital setting. Moreover, device manufacturers may employ special precautions to prevent spurious commands from being accepted by an implantable device. For example:
Some devices require that all Programmer commands be received over a short-range communication channel, such as the inductive (EM) channel. This limits the communication range to several centimeters.
Other devices require that a short-range inductive (EM) wand must be used to initiate a session between the Programmer and a particular implantable device. The device will only accept long-range RF commands sent by the Programmer after this interaction, and then only for a limited period of time.
From a computer security perspective, both of these approaches have a common feature: using either approach requires some form of close-proximity physical interaction with the patient before the implantable device will accept (potentially harmful) commands via the long-range RF channel. Even if a malicious party steals a Programmer from a hospital, she may still need to physically approach the patient – at a distance limited to perhaps centimeters – before she can use the Programmer to issue commands that might harm the patient.
In addition to the Programmer, most implantable manufacturers also produce some form of “telemedicine” device. These devices aren’t intended to deliver commands like cardiac shocks. Instead, they exist to provide remote patient monitoring from the patient’s home. Telematics devices use RF or inductive (EM) communications to interrogate the implantable device in order to obtain episode history, usually at night when the patient is asleep. The resulting data is uploaded to a server (via telephone or cellular modem) where it can be accessed by healthcare providers.
What can go wrong?
Before we get into specific vulnerabilities in implantable devices, it’s worth asking a very basic question. From a security perspective, what should we even be worried about?
There are a number of answers to this question. For example, an attacker might abuse implantable device systems or infrastructure to recover confidential patient data (known as PHI). Obviously this would be bad, and manufacturers should design against it. But the loss of patient information is, quite frankly, kind of the least of your worries.
A much scarier possibility is that an attacker might attempt to harm patients. This could be as simple as turning off therapy, leaving the patient to deal with their underlying condition. On the much scarier end of the spectrum, an ICD attacker could find a way to deliberately issue dangerous shocks that could stop a patient’s heart from functioning properly.
Now let me be clear: this isn’t not what you’d call a high probability attack. Most people aren’t going to be targeted by sophisticated technical assassins. The concerning thing about this the impact of such an attack is significantly terrifying that we should probably be concerned about it. Indeed, some high-profile individuals have already taken precautions against it.
The real nightmare scenario is a mass attack in which a single resourceful attacker targets thousands of individuals simultaneously — perhaps by compromising a manufacturer’s back-end infrastructure — and threatens to harm them all at the same time. While this might seem unlikely, we’ve already seen attackers systematically target hospitals with ransomware. So this isn’t entirely without precedent.
Securing device interaction physically
The real challenge in securing an implantable device is that too much security could hurt you. As tempting as it might be to lard these devices up with security features like passwords and digital certificates, doctors need to be able to access them. Sometimes in a hurry.
This shouldn’t happen in the ER.
This is a big deal. If you’re in a remote emergency room or hospital, the last thing you want is some complex security protocol making it hard to disable your device or issue a required shock. This means we can forget about complex PKI and revocation lists. Nobody is going to have time to remember a password. Even merely complicated procedures are out — you can’t afford to have them slow down treatment.
At the same time, these devices obviously must perform some sort of authentication: otherwise anyone with the right kind of RF transmitter could program them — via RF, from a distance. This is exactly what you want to prevent.
Many manufacturers have adopted an approach that cut through this knot. The basic idea is to require physical proximity before someone can issue commands to your device. Specifically, before anyone can issue a shock command (even via a long-range RF channel) they must — at least briefly — make close physical contact with the patient.
This proximity be enforced in a variety of ways. If you remember, I mentioned above that most devices have a short-range inductive coupling (“EM”) communications channel. These short-range channels seem ideal for establishing a “pairing” between a Programmer and an implantable device — via a specialized wand. Once the channel is established, of course, it’s possible to switch over to long-range RF communications.
This isn’t a perfect solution, but it has a lot going for it: someone could still harm you, but they would have to at least get a transmitter within a few inches of your chest before doing so. Moreover, you can potentially disable harmful commands from an entire class of device (like telemedecine monitoring devices) simply by leaving off the wand.
St. Jude Medical and MedSec
So given this background, what did St. Jude Medical do? All of the details are discussed in a full expert report published by Bishop Fox. In this post we I’ll focus on the most serious of MedSec’s claims, which can be expressed as follows:
Using only the hardware contained within a “Merlin @Home” telematics device, it was possible to disable therapy and issue high-power “shock” commands to an ICD from a distance, and without first physically interacting with the implantable device at close range.
This vulnerability had several implications:
The existence of this vulnerability implies that – through a relatively simple process of “rooting” and installing software on a Merlin @Home device – a malicious attacker could create a device capable of issuing harmful shock commands to installed SJM ICD devices at a distance. This is particularly worrying given that Merlin @Home devices are widely deployed in patients’ homes and can be purchased on eBay for prices under $30. While it might conceivably be possible to physically secure and track the location of all PCS Programmer devices, it seems challenging to physically track the much larger fleet of Merlin @Home devices.
More critically, it implies that St. Jude Medical implantable devices do not enforce a close physical interaction (e.g., via an EM wand or other mechanism) prior to accepting commands that have the potential to harm or even kill patients. This may be a deliberate design decision on St. Jude Medical’s part. Alternatively, it could be an oversight. In either case, this design flaw increases the risk to patients by allowing for the possibility that remote attackers might be able to cause patient harm solely via the long-range RF channel.
If it is possible – using software modifications only – to issue shock commands from the Merlin @Home device, then patients with an ICD may be vulnerable in the hypothetical event that their Merlin @Home device becomes remotely compromised by an attacker. Such a compromise might be accomplished remotely via a network attack on a single patient’s Merlin @Home device. Alternatively, a compromise might be accomplished at large scale through a compromise of St. Jude Medical’s server infrastructure.
We stress that the final scenario is strictly hypothetical. MedSec did not allege a specific vulnerability that allows for the remote compromise of Merlin @Home devices or SJM infrastructure. However, from the perspective of software and network security design, these attacks are one of the potential implications of a design that permits telematics devices to send such commands to an implantable device. It is important to stress that none of these attacks would be possible if St. Jude Medical’s design prohibited the implantable from accepting therapeutic commands from the Merlin @Home device (e.g., by requiring close physical interaction via the EM wand, or by somehow authenticating the provenance of commands and restricting critical commands to be sent by the Programmer only).
Validating MedSec’s claim
To validate MedSec’s claim, we examined their methodology from start to finish. This methodology included extracting and decompiling Java-based software from a single PCS Programmer; accessing a Merlin @Home device to obtain a root shell via the JTAG port; and installing a new package of custom software written by MedSec onto a used Merlin @Home device.
We then observed MedSec issue a series of commands to an ICD device using a Merlin @Home device that had been customized (via software) as described above. We used the Programmer to verify that these commands were successfully received by the implantable device, and physically confirmed that MedSec had induced shocks by attaching a multimeter to the leads on the implantable device.
Finally, we reproduced MedSec’s claims by opening the case of a second Merlin @Home device (after verifying that the tape was intact over the screw holes), obtaining a shell by connecting a laptop computer to the JTAG port, and installing MedSec’s software on the device. We were then able to issue commands to the ICD from a distance of several feet. This process took us less than three hours in total, and required only inexpensive tools and a laptop computer.
What are the technical details of the attack?
Simply reproducing a claim is only part of the validation process. To verify MedSec’s claims we also needed to understand why the attack described above was successful. Specifically, we were interested in identifying the security design issues that make it possible for a Merlin @Home device to successfully issue commands that are not intended to be issued from this type of device. The answer to this question is quite technical, and involves the specific way that SJM implantable devices verify commands before accepting them.
MedSec described to us the operation of SJM’s command protocol as part of their demonstration. They also provided us with Java JAR executable code files taken from the hard drive of the PCS Programmer. These files, which are not obfuscated and can easily be “decompiled” into clear source code, contain the software responsible for implementing the Programmer-to-Device communications protocol.
By examining the SJM Programmer code, we verified that Programmer commands are authenticated through the inclusion of a three-byte (24 bit) “authentication tag” that must be present and correct within each command message received by the implantable device. If this tag is not correct, the device will refuse to accept the command.
From a cryptographic perspective, 24 bits is a surprisingly short value for an important authentication field. However, we note that even this relatively short tag might be sufficient to prevent forgery of command messages – provided the tag ws calculated using a secure cryptographic function (e.g., a Message Authentication Code) using a fresh secret key that cannot be predicted by an the attacker.
Based on MedSec’s demonstration, and on our analysis of the Programmer code, it appears that SJM does not use the above approach to generate authentication tags. Instead, SJM authenticates the Programmer to the implantable with the assistance of a “key table” that is hard-coded within the Java code within the Programmer. At minimum, any party who obtains the (non-obfuscated) Java code from a legitimate SJM Programmer can gain the ability to calculate the correct authentication tags needed to produce viable commands – without any need to use the Programmer itself.
Moreover, MedSec determined – and successfully demonstrated – that there exists a “Universal Key”, i.e., a fixed three-byte authentication tag, that can be used in place of the calculated authentication tag. We identified this value in the Java code provided by MedSec, and verified that it was sufficient to issue shock commands from a Merlin @Home to an implantable device.
While these issues alone are sufficient to defeat the command authentication mechanism used by SJM implantable devices, we also analyzed the specific function that is used by SJM to generate the three-byte authentication tag. To our surprise, SJM does not appear to use a standard cryptographic function to compute this tag. Instead, they use an unusual and apparently “homebrewed” cryptographic algorithm for the purpose.
Specifically, the PCS Programmer Java code contains a series of hard-coded 32-bit RSA public keys. To issue a command, the implantable device sends a value to the Programmer. This value is then “encrypted” by the Programmer using one of the RSA public keys, and the resulting output is truncated to produce a 24-bit output tag.
The above is not a standard cryptographic protocol, and quite frankly it is difficult to see what St. Jude Medical is trying to accomplish using this technique. From a cryptographic perspective it has several problems:
The RSA public keys used by the PCS Programmers are 32 bits long. Normal RSA keys are expected to be a minimum of 1024 bits in length. Some estimates predict that a 1024-bit RSA key can be factored (and thus rendered insecure) in approximately one year using a powerful network of supercomputers. Based on experimentation, we were able to factor the SJM public keys in less than one second on a laptop computer.
Even if the RSA keys were of an appropriate length, the SJM protocol does not make use of the corresponding RSA secret keys. Thus the authentication tag is not an RSA signature, nor does it use RSA in any way that we are familiar with.
As noted above, since there is no shared session key established between the specific implantable device and the Programmer, the only shared secret available to both parties is contained within the Programmer’s Java code. Thus any party who extracts the Java code from a PCS Programmer will be able to transmit valid commands to any SJM implantable device.
Our best interpretation of this design is that the calculation is intended as a form of “security by obscurity”, based on the assumption that an attacker will not be able to reverse engineer the protocol. Unfortunately, this approach is rarely successful when used in security systems. In this case, the system is fundamentally fragile – due to the fact that code for computing the correct authentication tag is likely available in easily-decompiled Java bytecode on each St. Jude Medical Programmer device. If this code is ever extracted and published, all St. Jude Medical devices become vulnerable to command forgery.
How to remediate these attacks?
To reiterate, the fundamental security concerns with these St. Jude Medical devices (as of 2016) appeared to be problems of design. These were:
SJM implantable devices did not require close physical interaction prior to accepting commands (allegedly) sent by the Programmer.
SJM did not incorporate a strong cryptographic authentication mechanism in its RF protocol to verify that commands are truly sent by the Programmer.
Even if the previous issue was addressed, St. Jude did not appear to have an infrastructure for securely exchanging shared cryptographic keys between a legitimate Programmer and an implantable device.
There are various ways to remediate these issues. One approach is to require St. Jude implantable devices to exchange a secret key with the Programmer through a close-range interaction involving the Programmer’s EM wand. A second approach would be to use a magnetic sensor to verify the presence of a magnet on the device, prior to accepting Programmer commands. Other solutions are also possible. I haven’t reviewed the solution SJM ultimately adopted in their software patches, and I don’t know how many users patched.
Conclusion
Implantable devices offer a number of unique security challenges. It’s naturally hard to get these things right. At the same time, it’s important that vendors take these issues seriously, and spend the time to get cryptographic authentication mechanisms right — because once deployed, these devices are very hard to repair, and the cost of a mistake is extremely high.
If you’ve read this blog before, you know that secure messaging is one of my favorite topics. However, recently I’ve been a bit disappointed. My sadness comes from the fact that lately these systems have been getting too damned good. That is, I was starting to believe that most of the interesting problems had finally been solved.
If nothing else, today’s post helped disabuse me of that notion.
This result comes from a new paper by Rösler, Mainka and Schwenk from Ruhr-Universität Bochum (affectionately known as “RUB”). The RUB paper paper takes a close look at the problem of group messaging, and finds that while messengers may be doing fine with normal (pairwise) messaging, group messaging is still kind of a hack.
If all you want is the TL;DR, here’s the headline finding: due to flaws in both Signal and WhatsApp (which I single out because I use them), it’s theoretically possible forstrangers to add themselves to an encrypted group chat. However, the caveat is that these attacks are extremely difficult to pull off in practice, so nobody needs to panic. But both issues are very avoidable, and tend to undermine the logic of having an end-to-end encryption protocol in the first place. (Wired also has a good article.)
First, some background.
How do end-to-end encryption and group chats work?
In recent years we’ve seenplenty of evidence that centralized messaging servers aren’t a very good place to store confidential information. The good news is: we’re not stuck with them. One of the most promising advances in the area of secure communications has been the recentwidespread deployment of end-to-end (e2e) encrypted messaging protocols.
At a high level, e2e messaging protocols are simple: rather than sending plaintext to a server — where it can be stolen or read — the individual endpoints (typically smartphones) encrypt all of the data using keys that the server doesn’t possess. The server has a much more limited role, moving and storing only meaningless ciphertext. With plenty of caveats, this means a corrupt server shouldn’t be able to eavesdrop on the communications.
In pairwise communications (i.e., Alice communicates with only Bob) this encryption is conducted using a mix of public-key and symmetric key algorithms. One of the most popular mechanisms is the Signal protocol, which is used by Signal and WhatsApp (notable for having 1.3 billion users!) I won’t discuss the details of the Signal protocol here, except to say that it’s complicated, but it works pretty well.
A fly in the ointment is that the standard Signal protocol doesn’t work quite as well for group messaging, primarily because it’s not optimized for broadcasting messages to many users.
To handle that popular case, both WhatsApp and Signal use a small hack. It works like this: each group member generates a single “group key” that this member will use to encrypt all of her messages to everyone else in the group. When a new member joins, everyone who is already in the group needs to send a copy of their group key to the new member (using the normal Signal pairwise encryption protocol). This greatly simplifies the operation of group chats, while ensuring that they’re still end-to-end encrypted.
How do members know when to add a new user to their chat?
Here is where things get problematic.
From a UX perspective, the idea is that only one person actually initiates the adding of a new group member. This person is called the “administrator”. This administrator is the only human being who should actually do anything — yet, her one click must cause some automated action on the part of every other group members’ devices. That is, in response to the administrator’s trigger, all devices in the group chat must send their keys to this new group member.
Notification messages in WhatsApp.
(In Signal, every group member is an administrator. In WhatsApp it’s just a subset of the members.)
The trigger is implemented using a special kind of message called (unimaginatively) a “group management message”. When I, as an administrator, add Tom to a group, my phone sends a group management message to all the existing group members. This instructs them to send their keys to Tom — and to notify the members visually so that they know Tom is now part of the group. Obviously this should only happen if I reallydid add Tom, and not if some outsider (like that sneaky bastard Tom himself!) tries to add Tom.
And this is where things get problematic.
Ok, what’s the problem?
According to the RUB paper, both Signal and WhatsApp fail to properly authenticate group management messages.
The upshot is that, at least in theory, this makes it possible for an unauthorized person — not a group administrator, possibly not even a member of the group — to add someone to your group chat.
The issues here are slightly different between Signal and WhatsApp. To paraphrase Tolstoy, every working implementation is alike, but every broken one is broken in its own way. And WhatsApp’s implementation is somewhat worse than Signal. Here I’ll break them down.
Signal. Signal takes a pragmatic (and reasonable) approach to group management. In Signal, every group member is considered an administrator — which means that any member can add a new member. Thus if I’m a member of a group, I can add a new member by sending a group management message to every other member. These messages are sent encrypted via the normal (pairwise) Signal protocol.
The group management message contains the “group ID” (a long, unpredictable number), along with the identity of the person I’m adding. Because messages are sent using the Signal (pairwise) protocol, they should be implicitly authenticated as coming from me — because authenticity is a property that the pairwise Signal protocol already offers. So far, this all sounds pretty good.
The problem that the RUB researchers discovered through testing, is that while the Signal protocol does authenticate that the group management comes from me, it doesn’t actually check that I am a member of the group — and thus authorized to add the new user!
In short, if this finding is correct, it turns out that any random Signal user in the world can you send a message of the form “Add Mallory to the Group 8374294372934722942947”, and (if you happen to belong to that group) your app will go ahead and try to do it.
The good news is that in Signal the attack is very difficult to execute. The reason is that in order to add someone to your group, I need to know the group ID. Since the group ID is a random 128-bit number (and is never revealed to non-group-members or even the server**) that pretty much blocks the attack. The main exception to this is former group members, who already know the group ID — and can now add themselves back to the group with impunity.
(And for the record, while the group ID may block the attack, it really seems like a lucky break — like falling out of a building and landing on a street awning. There’s no reason the app should process group management messages from random strangers.)
So that’s the good news. The bad news is that WhatsApp is a bit worse.
WhatsApp. WhatsApp uses a slightly different approach for its group chat. Unlike Signal, the WhatsApp server plays a significant role in group management, which means that it determines who is an administrator and thus authorized to send group management messages.
Additionally, group management messages are not end-to-end encrypted or signed. They’re sent to and from the WhatsApp server using transport encryption, but not the actual Signal protocol.
When an administrator wishes to add a member to a group, it sends a message to the server identifying the group and the member to add. The server then checks that the user is authorized to administer that group, and (if so), it sends a message to every member of the group indicating that they should add that user.
The flaw here is obvious: since the group management messages are not signed by the administrator, a malicious WhatsApp server can add any user it wants into the group. This means the privacy of your end-to-end encrypted group chat is only guaranteed if you actually trust the WhatsApp server.
This undermines the entire purpose of end-to-end encryption.
But this is silly. Don’t we trust the WhatsApp server? And what about visual notifications?
One perfectly reasonable response is that exploiting this vulnerability requires a compromise of the WhatsApp server (or legal compulsion, perhaps). This seems fairly unlikely.
And yet, the entire point of end-to-end encryption is to remove the server from the trusted computing base. We haven’t entirely achieved this yet, thanks to things like key servers. But we are making progress. This bug is a step back, and it’s one a sophisticated attacker potentially could exploit.
A second obvious objection to these issues is that adding a new group member results in a visual notification to each group member. However, it’s not entirely clear that these messages are very effective. In general they’re relatively easy to miss. So these are meaningful bugs, and things that should be fixed.
How do you fix this?
The great thing about these bugs is that they’re both eminently fixable.
The RUB paper points out some obvious countermeasures. In Signal, just make sure that the group management messages come from a legitimate member of the group. In WhatsApp, make sure that the group management messages are signed by an administrator.*
Obviously fixes like this are a bit complex to roll out, but none of these should be killers.
Is there anything else in the paper?
Oh yes, there’s quite a bit more. But none of it is quite as dramatic. For one thing, it’s possible for attackers to block message acknowledgements in group chats, which means that different group members could potentially see very different versions of the chat. There are also several cases where forward secrecy can be interrupted. There’s also some nice analysis of Threema, if you’re interested.
I need a lesson. What’s the moral of this story?
The biggest lesson is that protocol specifications are never enough. Both WhatsApp and Signal (to an extent) have detailed protocol specifications that talk quite a bit about the cryptography used in their systems. And yet the issues reported in the RUB paper not obvious from reading these summaries. I certainly didn’t know about them.
In practice, these problems were only found through testing.
Mallory.
So the main lesson here is: test, test, test. This is a strong argument in favor of open-source applications and frameworks that can interact with private-garden services like Signal and WhatsApp. It lets us see what the systems are getting right and getting wrong.
The second lesson — and a very old one — is that cryptography is only half the battle. There’s no point in building the most secure encryption protocol in the world if someone can simply instruct your client to send your keys to Mallory. The greatest lesson of all time is that real cryptosystems are always broken this way — and almost never through the fancy cryptographic attacks we love to write about.
Notes:
* The challenge here is that since WhatsApp itself determines who the administrators are, this isn’t quite so simple. But at very least you can ensure that someone in the group was responsible for the addition.
** According to the paper, the Signal group IDs are always sent encrypted between group members and are never revealed to the Signal server. Indeed, group chat messages look exactly like pairwise chats, as far as the server is concerned. This means only current or former group members should know the group ID.
















 and
and 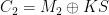 , which allows her to compute
, which allows her to compute 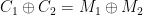 . Even better, if the attacker knows one of
. Even better, if the attacker knows one of  or
or  , she can immediately recover the other. This gives her a strong incentive to know one of the two plaintexts.
, she can immediately recover the other. This gives her a strong incentive to know one of the two plaintexts.

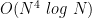 queries, where N is the number of possible values your data can take on (e.g., the ages of your employees, ranging between 1 and 100 would give N=100.) This is assuming an arbitrary dataset. The results get much better if the database is “dense”, meaning every possible value occurs once.
queries, where N is the number of possible values your data can take on (e.g., the ages of your employees, ranging between 1 and 100 would give N=100.) This is assuming an arbitrary dataset. The results get much better if the database is “dense”, meaning every possible value occurs once.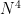 tends to make Kellaris et al. attacks impractical, simply because they’ll take too long. Similarly, data like employee last names (encoded as a form that can be sorted and range-queries) gives you even vaster domains like
tends to make Kellaris et al. attacks impractical, simply because they’ll take too long. Similarly, data like employee last names (encoded as a form that can be sorted and range-queries) gives you even vaster domains like 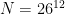 , say, and so perhaps we could pleasantly ignore these results and spend our time on more amusing engagements.
, say, and so perhaps we could pleasantly ignore these results and spend our time on more amusing engagements. ADR.
ADR. . For example, if I’m trying to recover employee salaries, I don’t need them to be exact: getting them within 1% or 5% is probably good enough for my purposes. Similarly, reconstructing nearly all of the letters in your last name probably lets me guess the rest, especially if I know the distribution of common last names.
. For example, if I’m trying to recover employee salaries, I don’t need them to be exact: getting them within 1% or 5% is probably good enough for my purposes. Similarly, reconstructing nearly all of the letters in your last name probably lets me guess the rest, especially if I know the distribution of common last names. queries, where
queries, where  is the error parameter.
is the error parameter.

 queries, and experimentally the results are again even better than one would expect.
queries, and experimentally the results are again even better than one would expect.

 validated some alleged flaws in implantable cardiac devices manufactured by St. Jude Medical (now part of
validated some alleged flaws in implantable cardiac devices manufactured by St. Jude Medical (now part of  effectively
effectively Moreover, device manufacturers may employ special precautions to prevent spurious commands from being accepted by an implantable device. For example:
Moreover, device manufacturers may employ special precautions to prevent spurious commands from being accepted by an implantable device. For example: These devices aren’t intended to deliver commands like cardiac shocks. Instead, they exist to provide remote patient monitoring from the patient’s home. Telematics devices use RF or inductive (EM) communications to interrogate the implantable device in order to obtain episode history, usually at night when the patient is asleep. The resulting data is uploaded to a server (via telephone or cellular modem) where it can be accessed by healthcare providers.
These devices aren’t intended to deliver commands like cardiac shocks. Instead, they exist to provide remote patient monitoring from the patient’s home. Telematics devices use RF or inductive (EM) communications to interrogate the implantable device in order to obtain episode history, usually at night when the patient is asleep. The resulting data is uploaded to a server (via telephone or cellular modem) where it can be accessed by healthcare providers.


