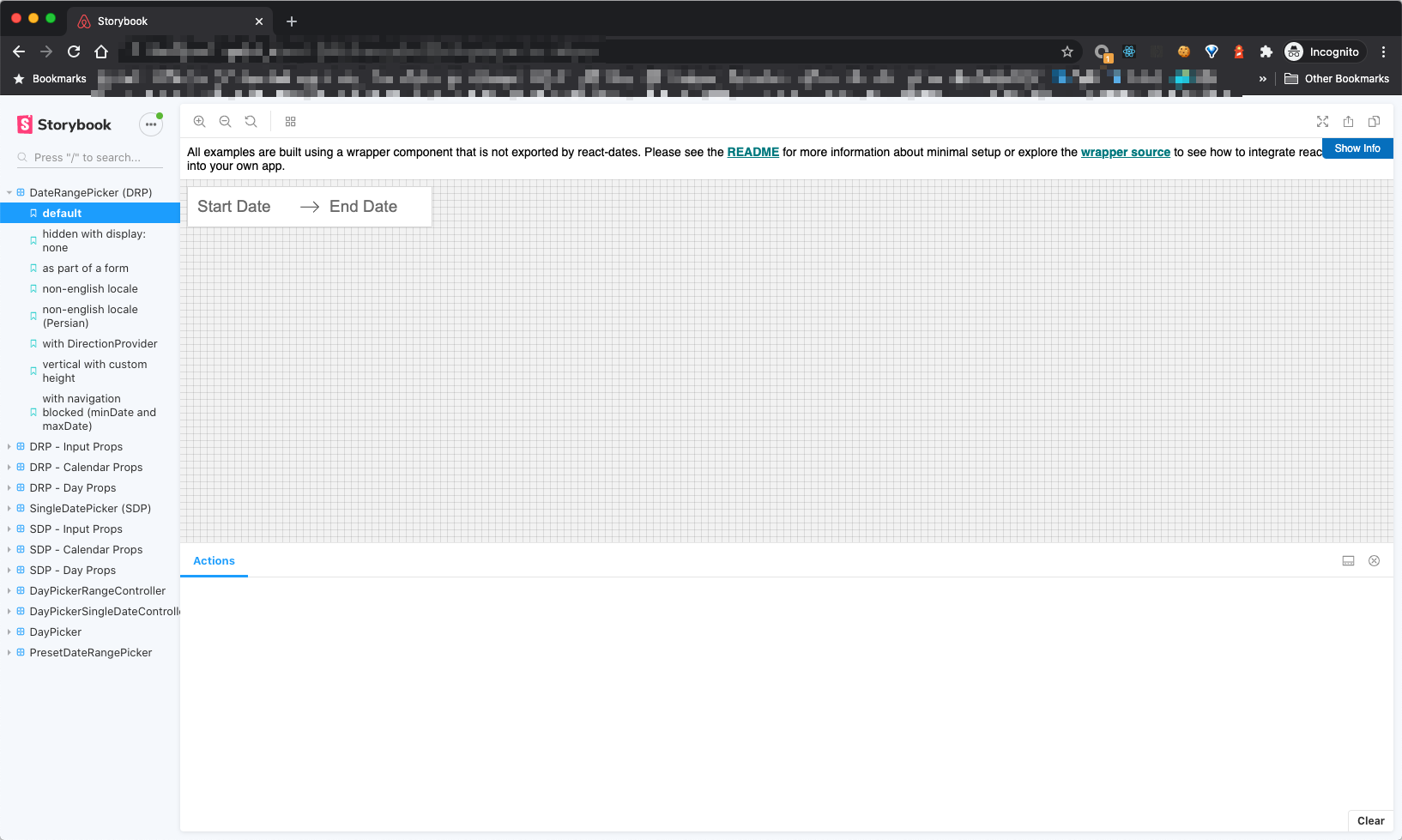
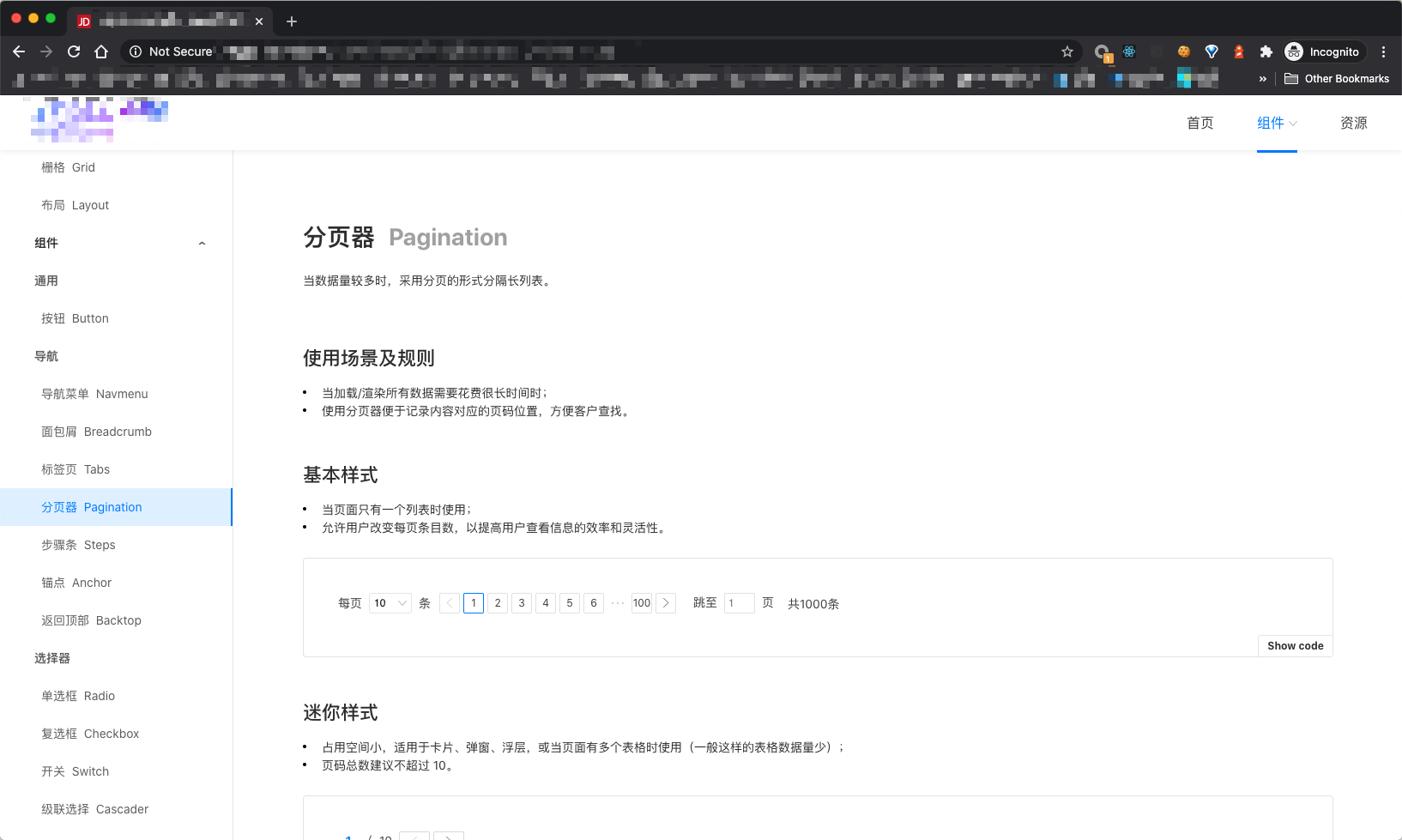
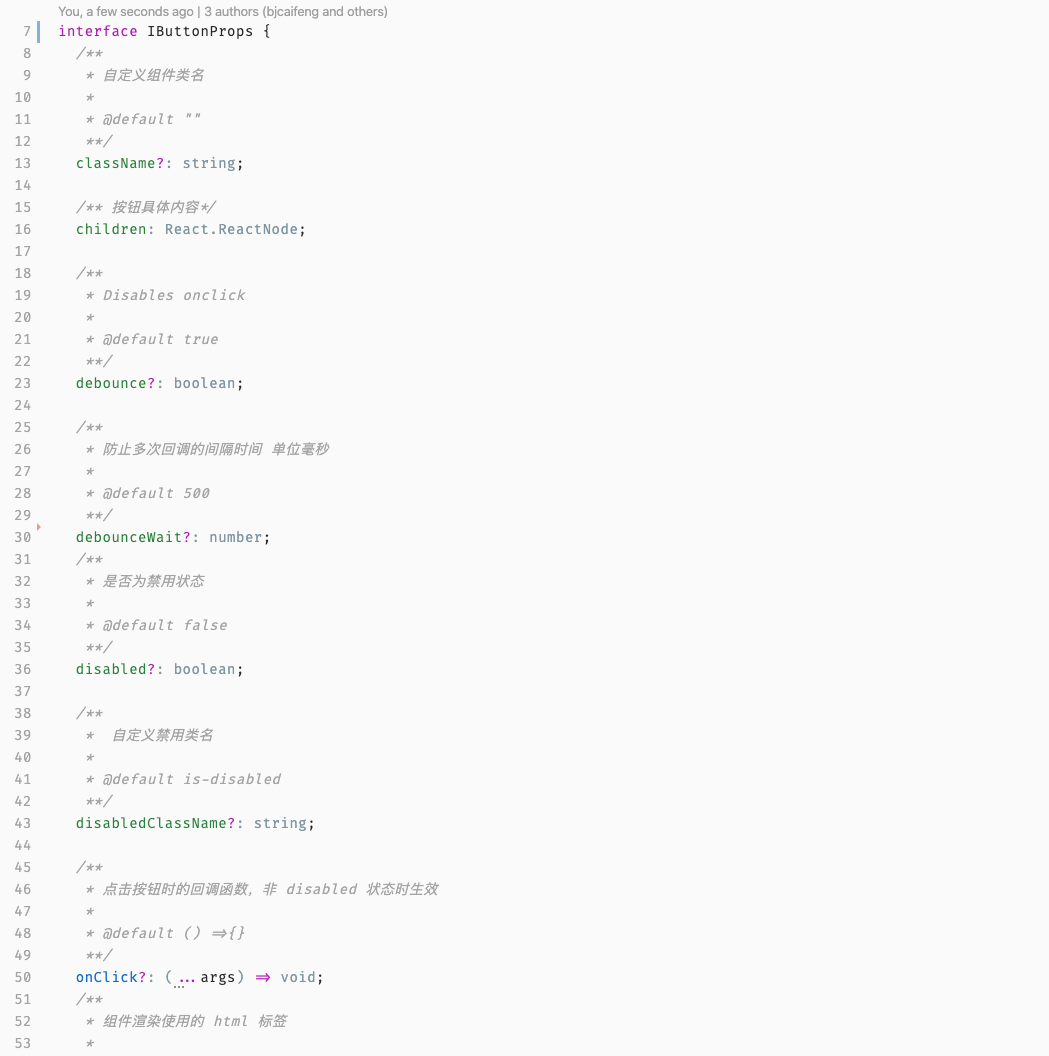
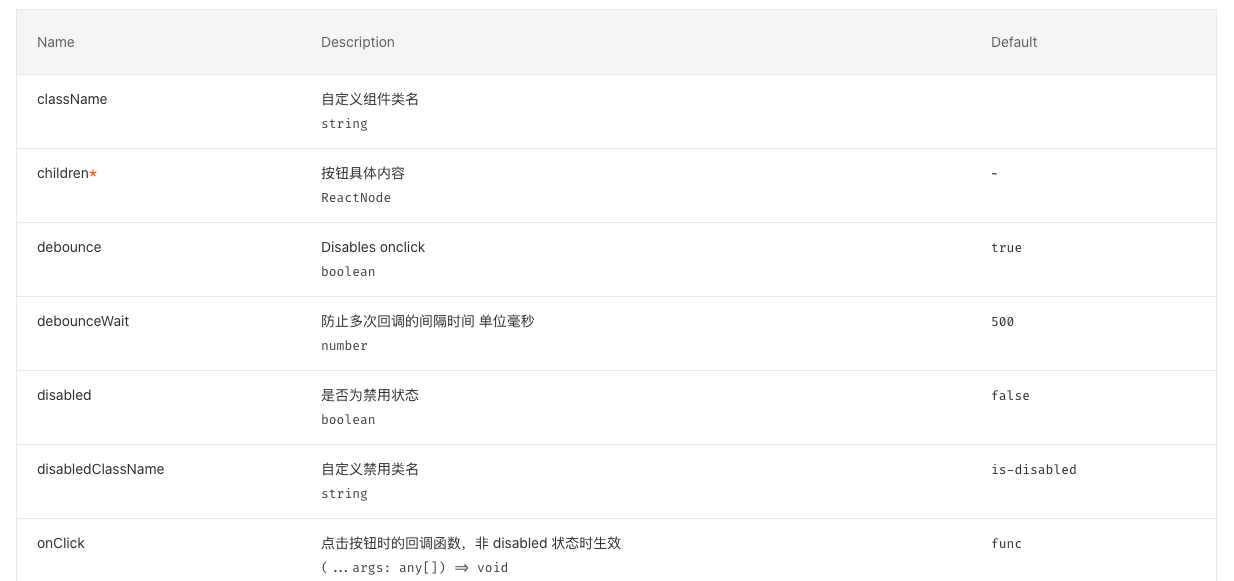
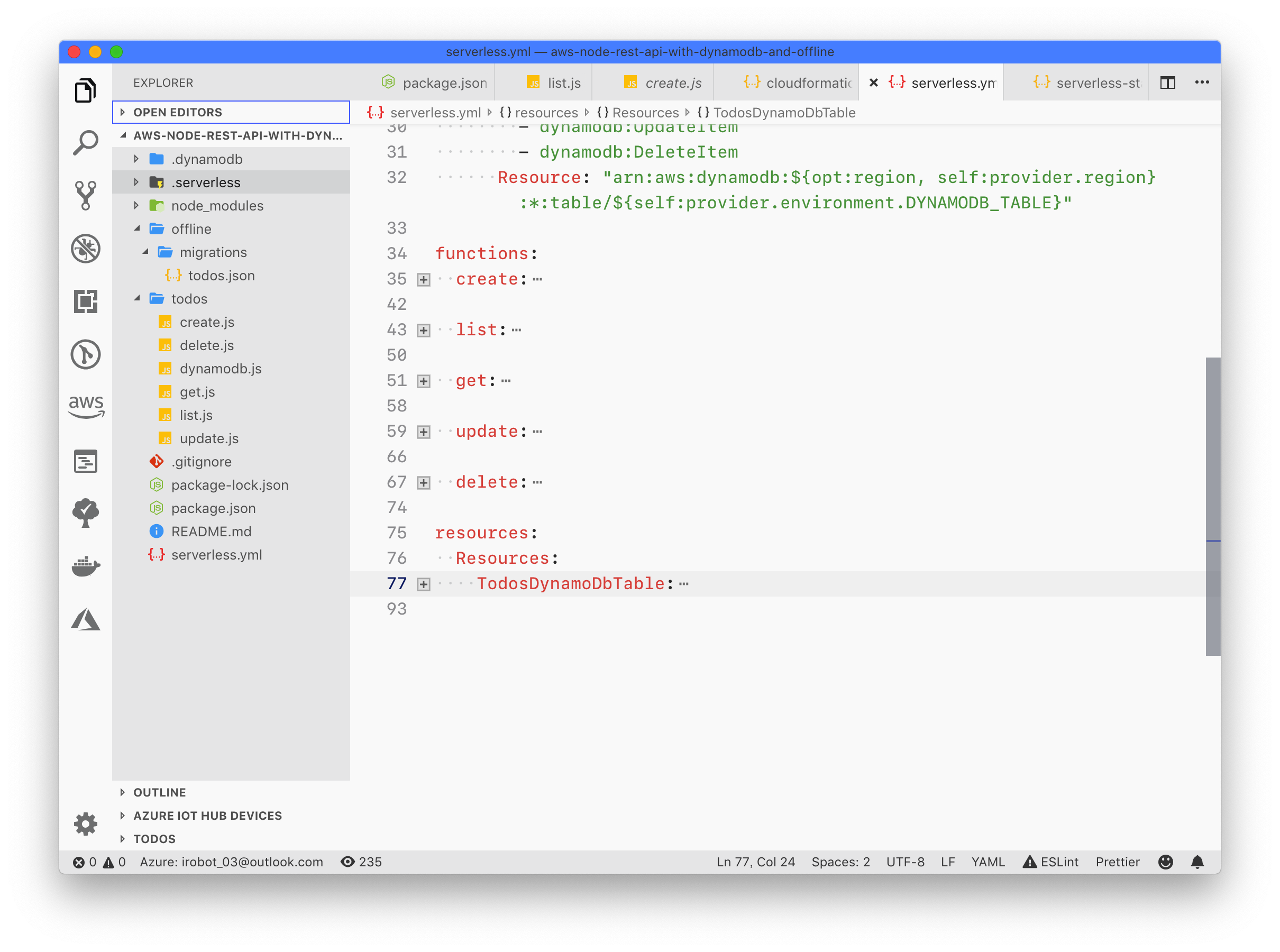
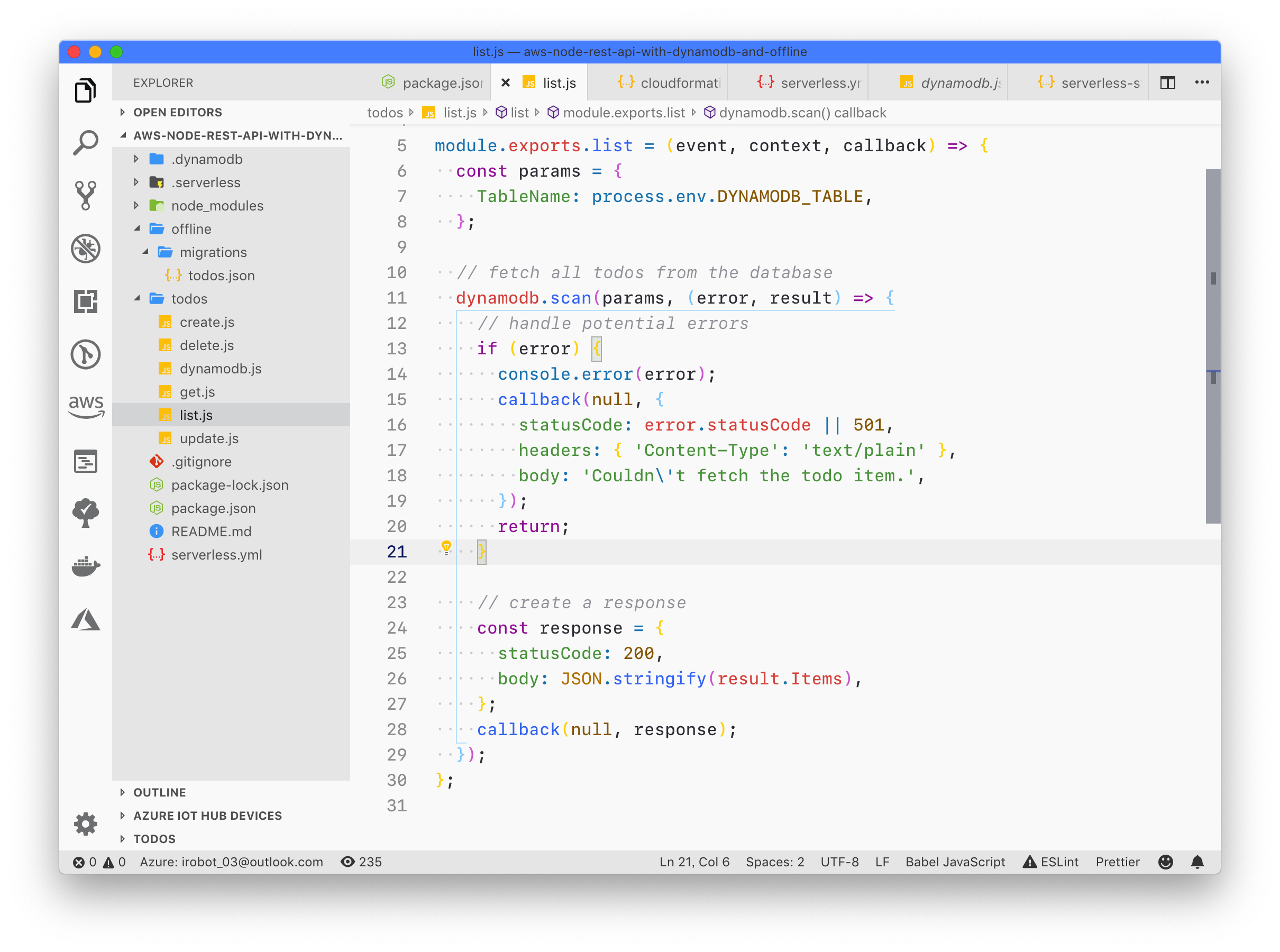
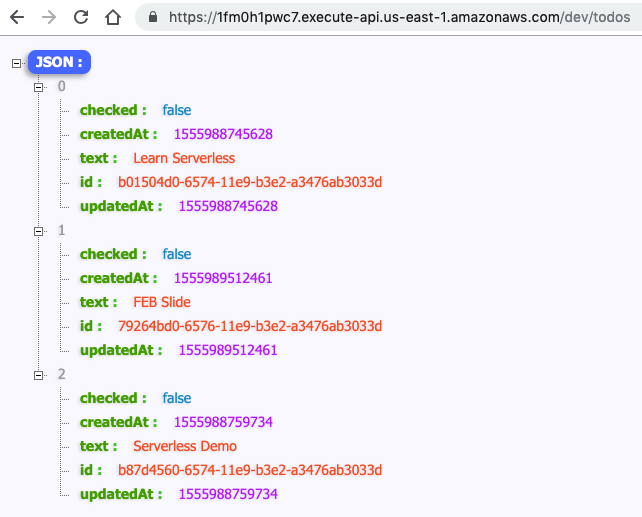
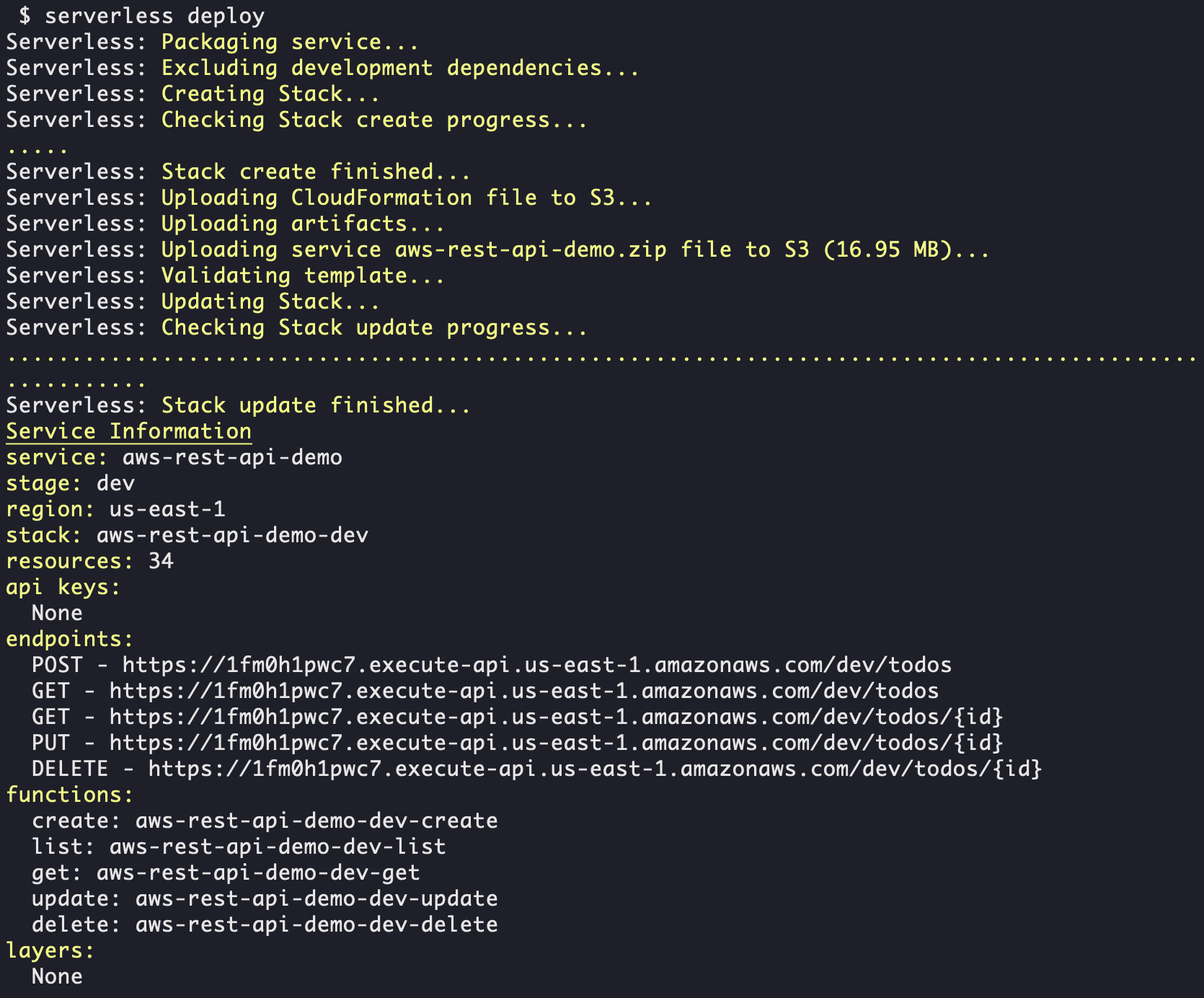
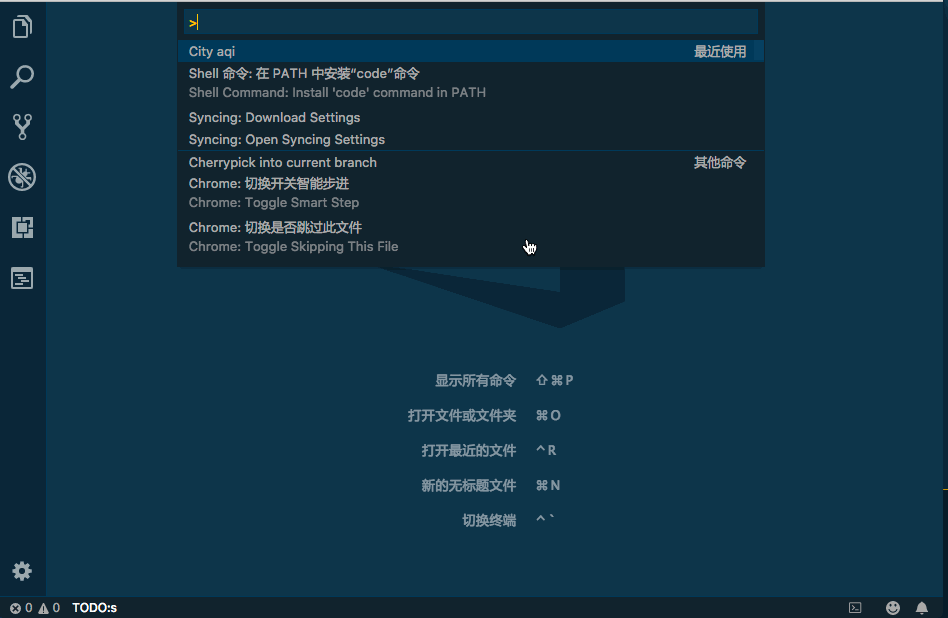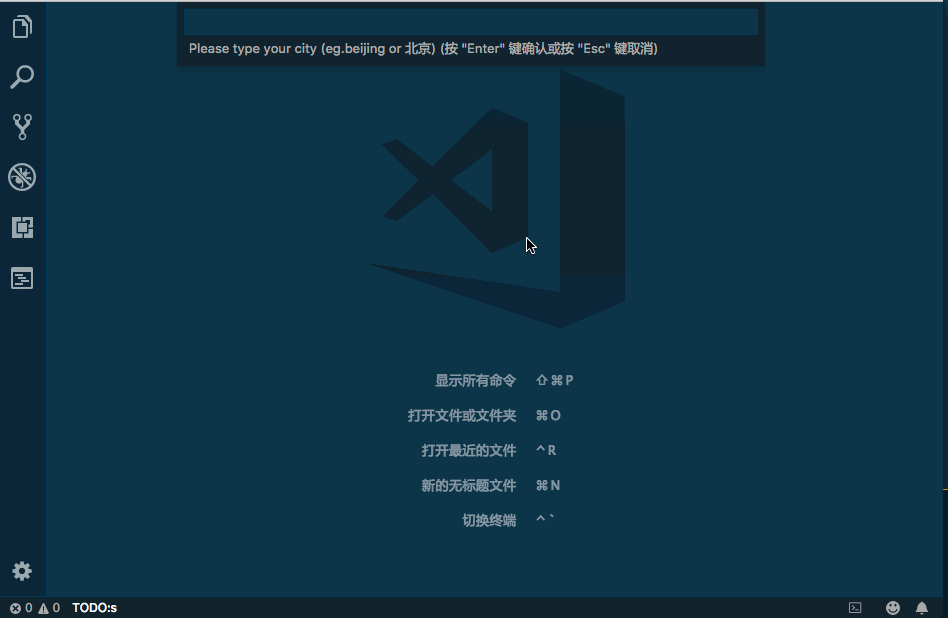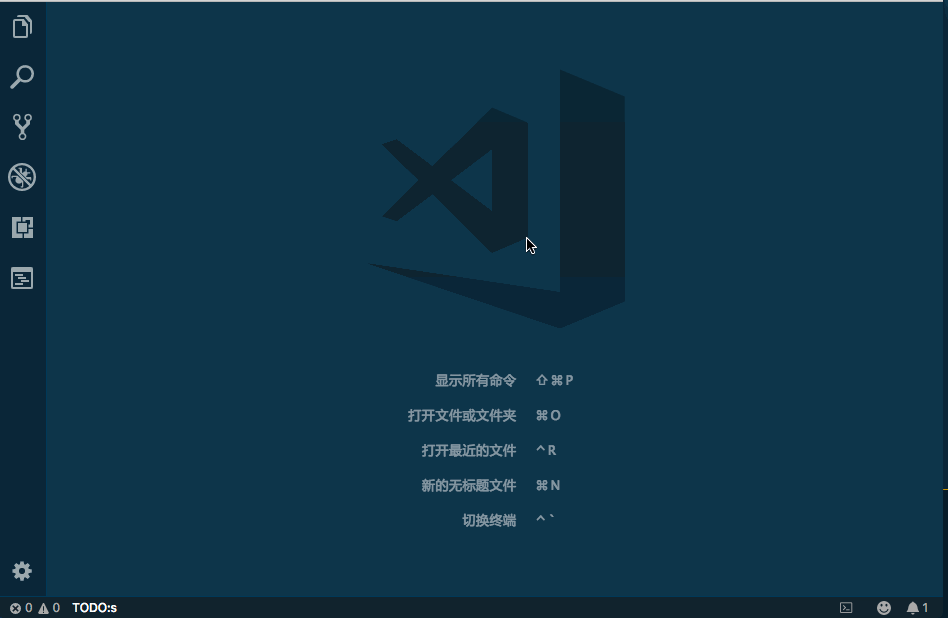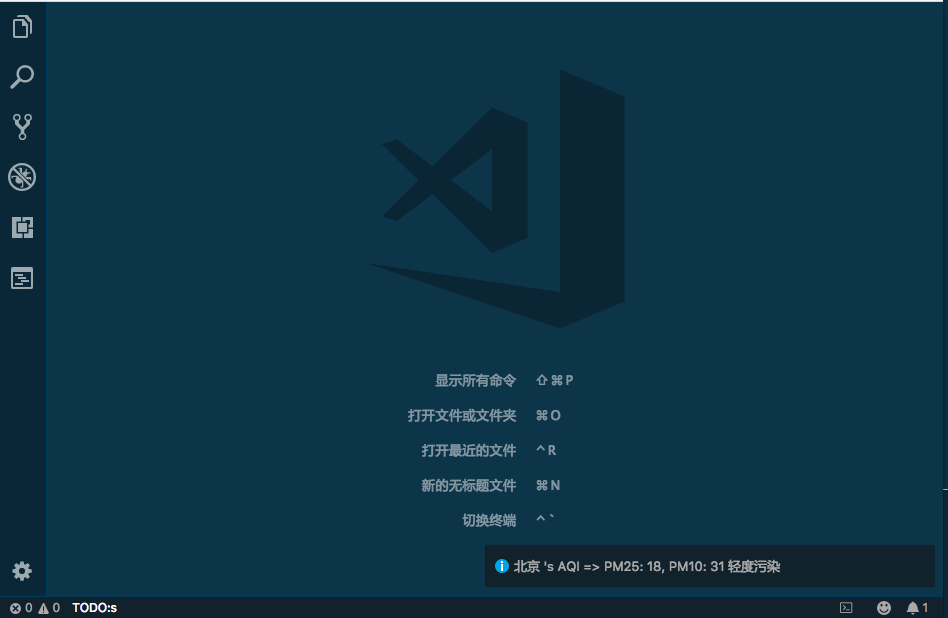
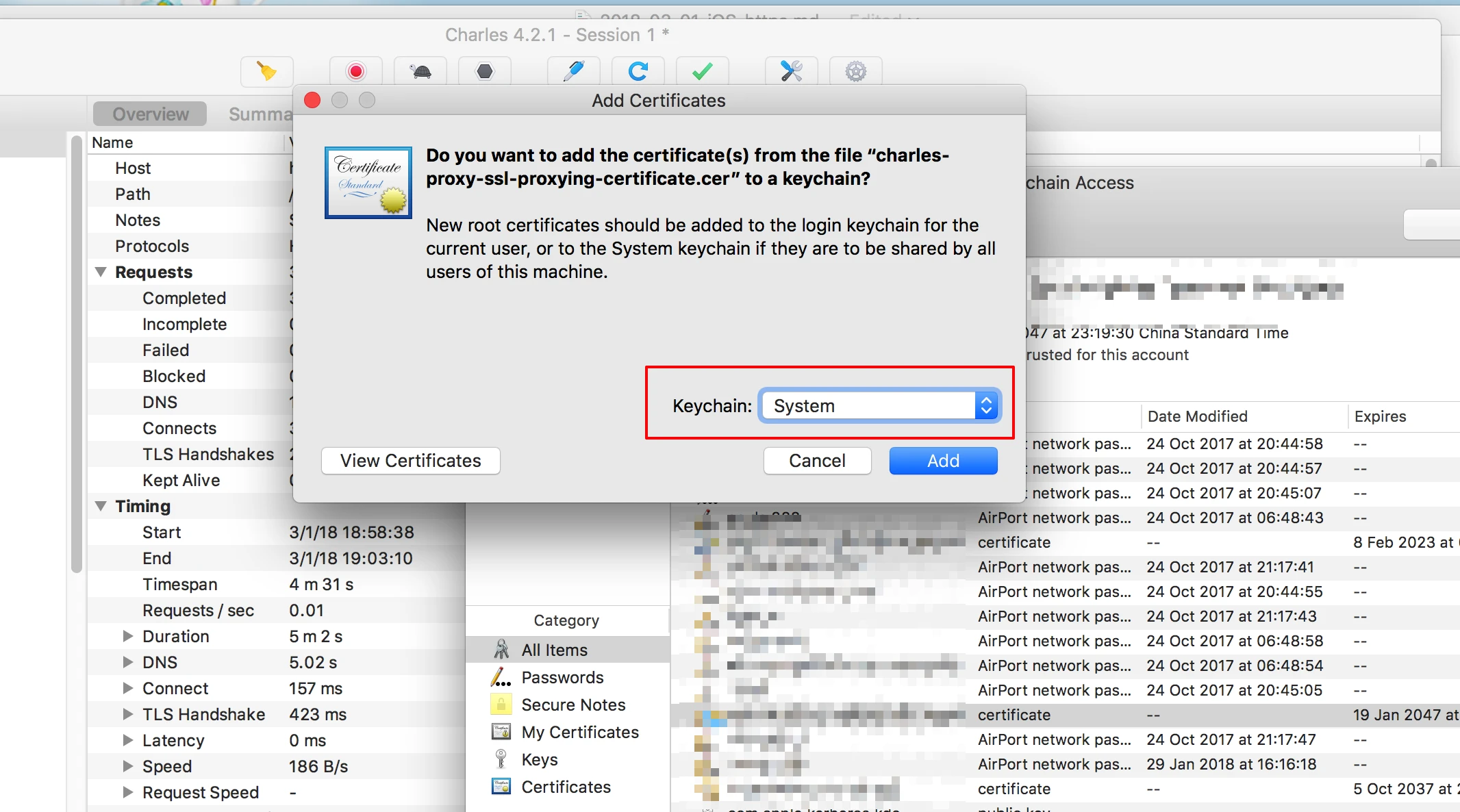
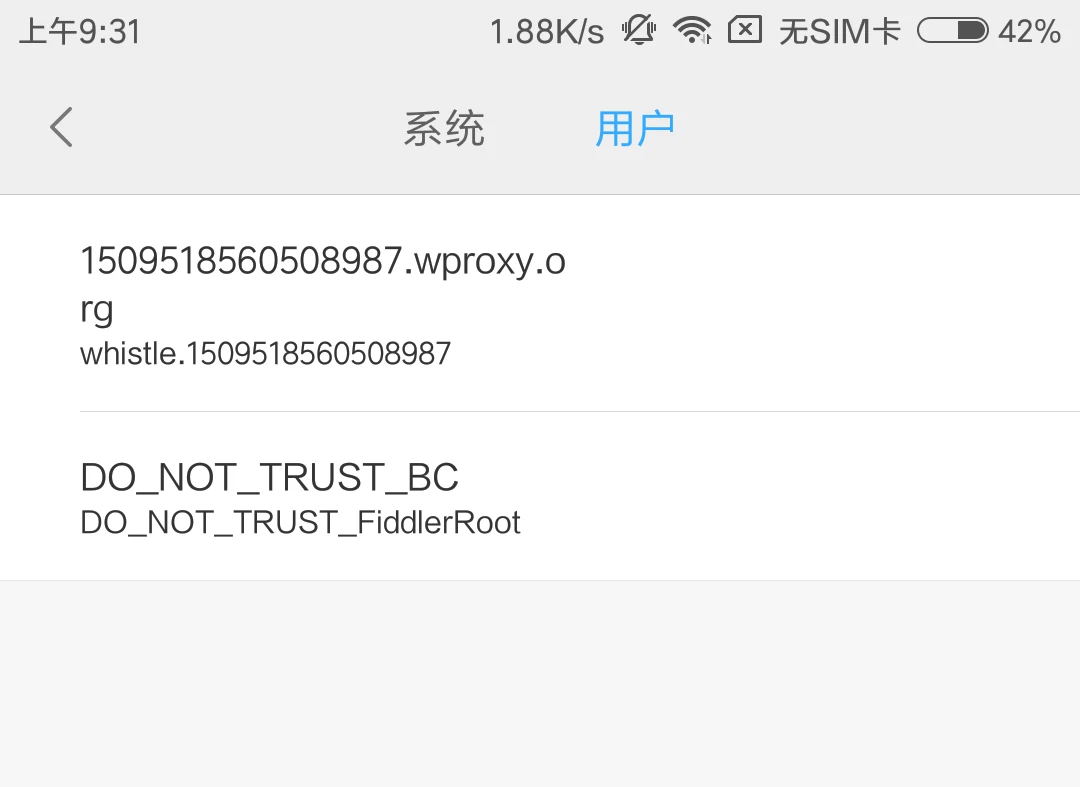
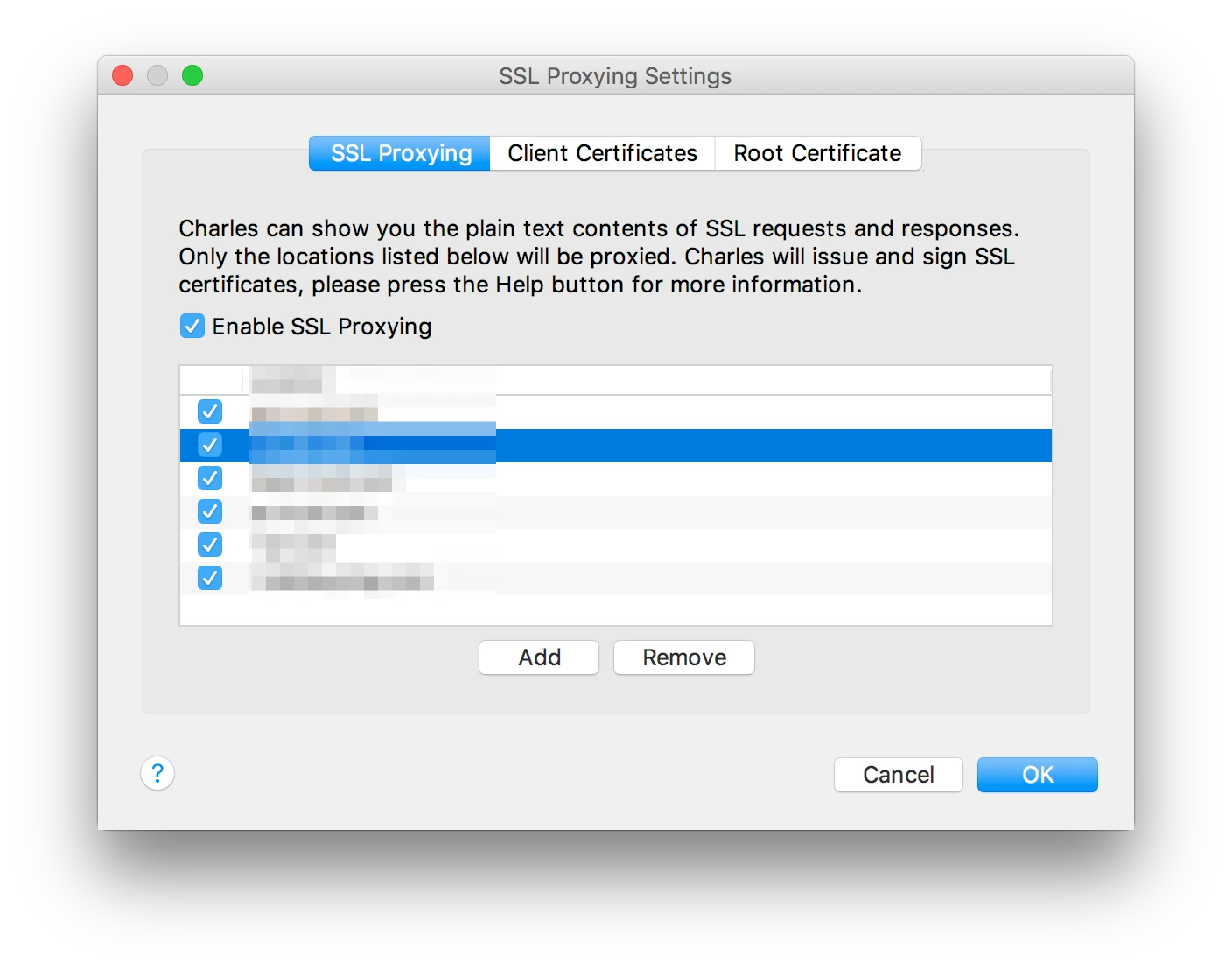
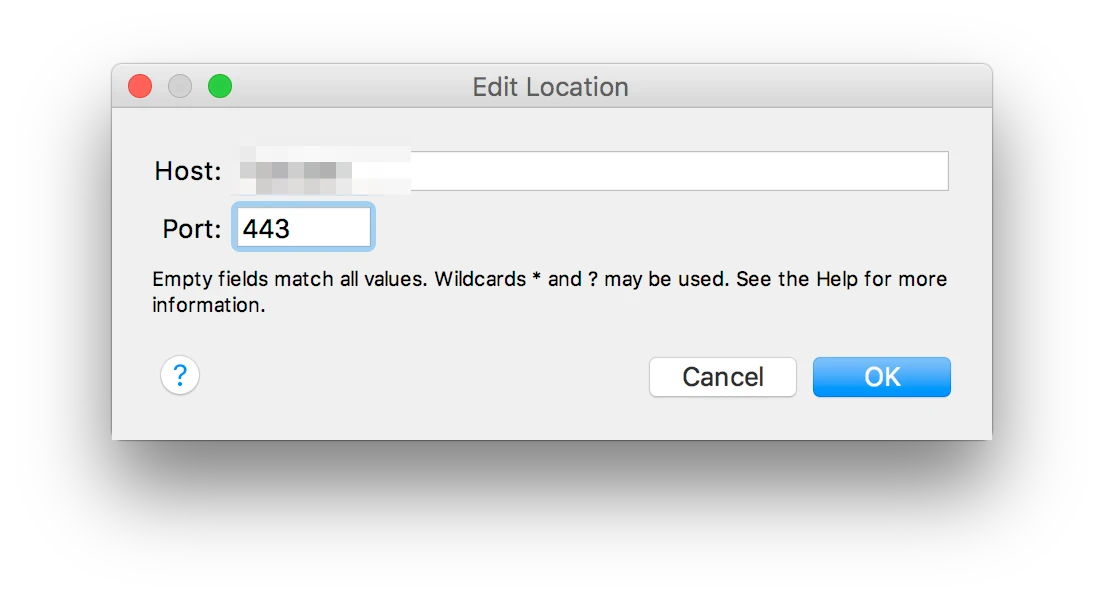
HSET key field value HGET key HMSET key field value [field value ...] # 存储某一个key,某一个或多个字段的 value HMGET key field [field ...] # 获取某一key的某一个或多个value HGETALL key # 获取某一 key 的所有value
自由地为任何键增减字段而不影响其他键。
列表类型
KEYS 命令需要遍历数据库中所有键,出于性能考虑,一般很少在生产环境使用。
List 可以存储一个有序的字符串列表,内部是 双向链表 实现的,所以在列表两端增加元素时间负责度都是 O(1),获取越接近两端的元素速度越快。链表的缺点是通过索引来访问某一个元素慢。
Don't use `{}` as a type. `{}` actually means "any non-nullish value".
- If you want a type meaning "any object", you probably want `Record<string, unknown>` instead. - If you want a type meaning "any value", you probably want `unknown` instead.
你是否怀疑过由于 JavaScript 的问题可能会影响你的网页或者某一部分内容出现在 Google Search 的结果? 你通过我们的故障排除指南来了解如何解决 JavaScript 相关的这些问题。
JavaScript 是 WEB 平台中重要的一部分,因为它能够提供由普通 web 网站向功能更强大的应用平台转变的众多特性。开发 JavaScript 驱动的 web 应用可以帮助你吸引新用户,同时可以通过 Google 搜索到你的 web 应用提供出来的有效内容来留存现有用户。当 Google Search 通过 Chromium 引擎来执行 JavaScript 时,你可以做一些下面这些事情去进行优化改进你的 Web 应用。
下面这个指南描述了 Google Search 是如何处理 JavaScript 的,同时也在展示提升 Google Search SEO 结果的最佳实践。
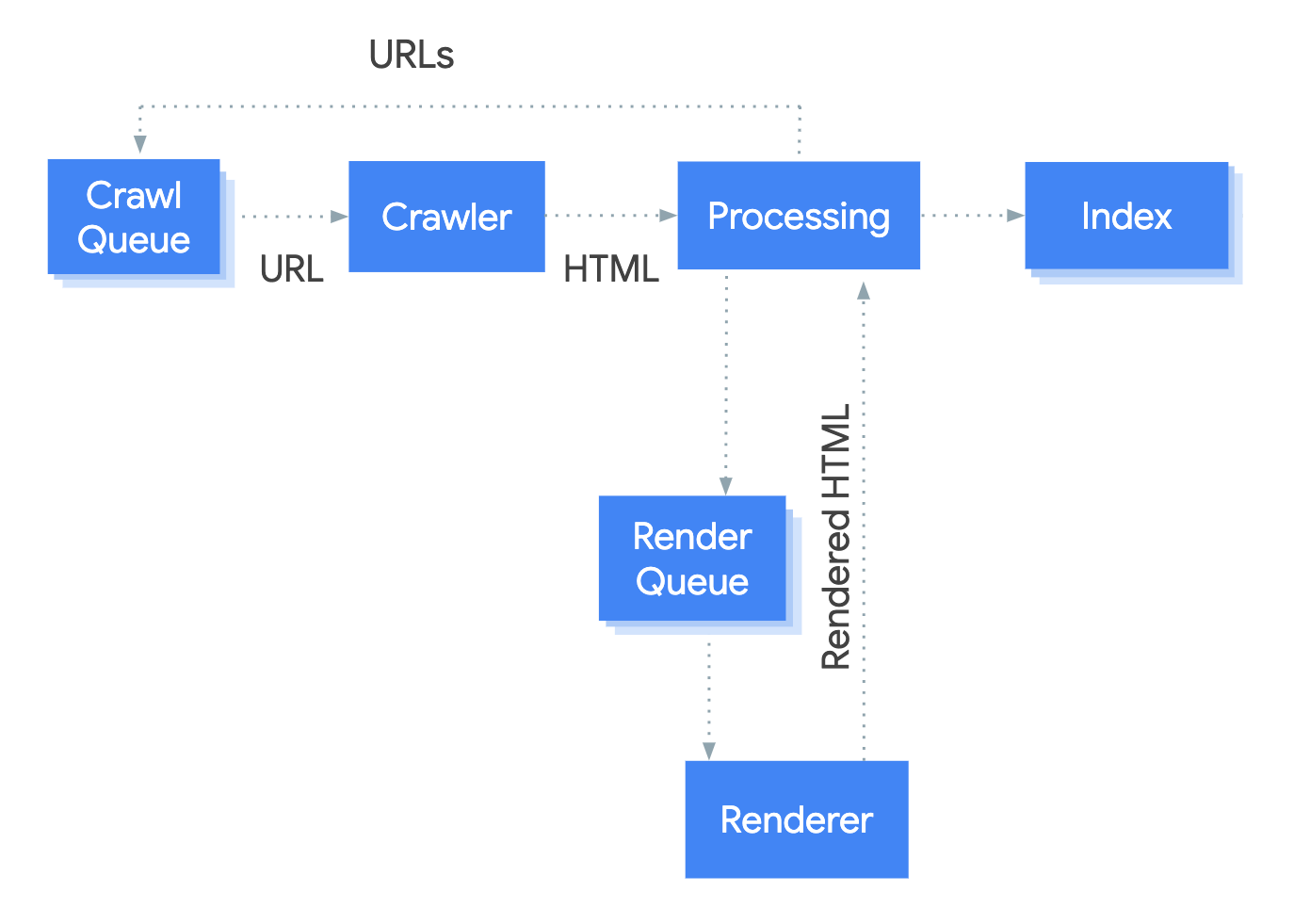
爬取 URL 时处理 HTML 响应在传统型网站和服务端渲染页面的网站很奏效,服务端渲染网站其中的 HTTP 响应中包含了全部的内容。一些 JavaScript 网站可能会用到 app shell model,这些网站在初始 HTML 内容中并不包含实际的内容,Googlebot 需要在看到十几页面内容之前执行 JavaScript。
Googlebot 将需要渲染的页面排入队列,除非网站的 robots meta tag or header 信息告诉 Googlebot 不要对这个页面进行索引。这个页面可能在队列中短暂停留,但是它将花费更长的时间。一旦 Googlebot 的资源允许,headless Chromium 可以渲染这个页面并且执行 JavaScript。Googlebot 会再次解析渲染完成的 HTML 链接,并且按照队列查找的 URL 继续爬取。Googlebot 也会使用渲染完成的 HTML 对页面进行索引。
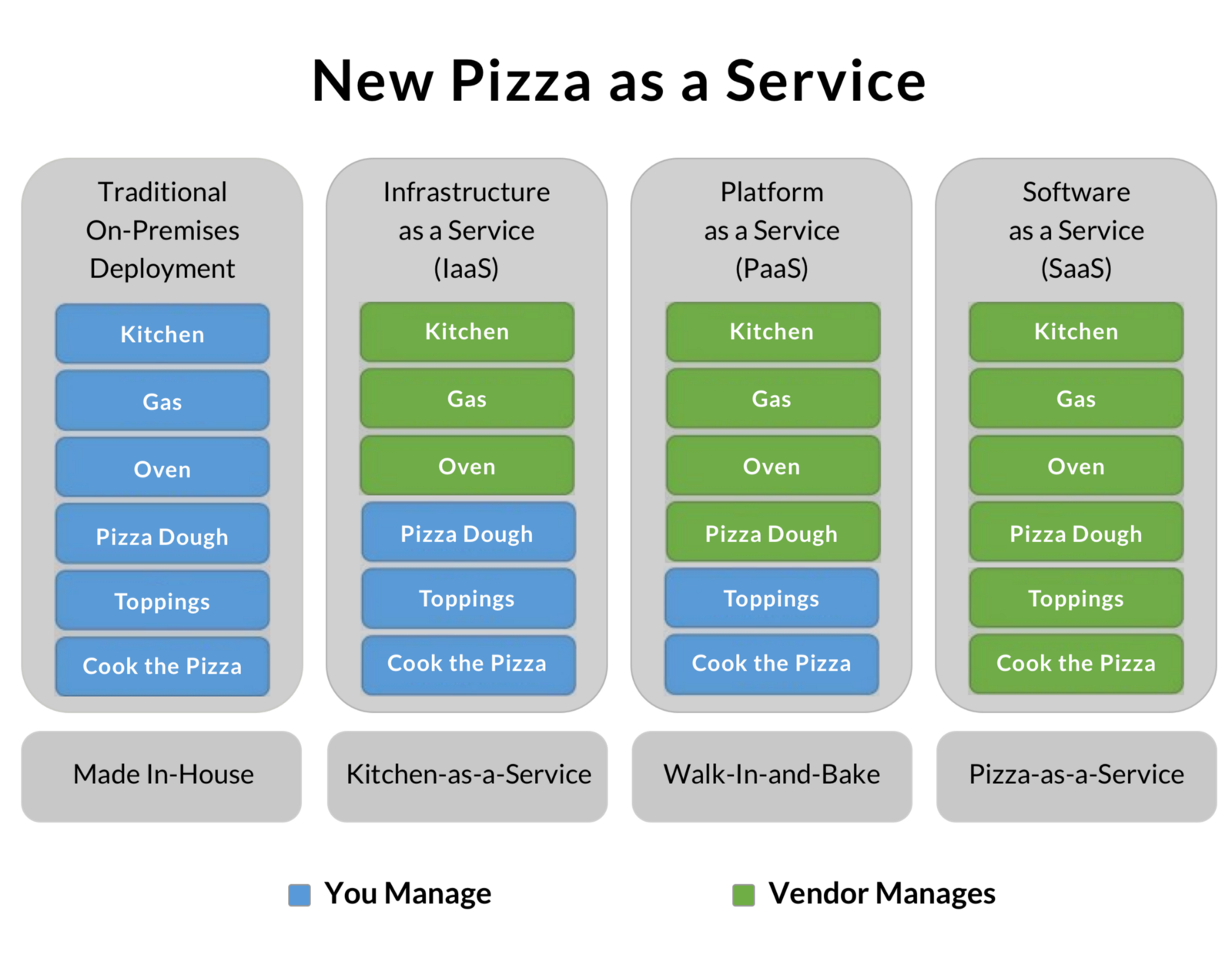
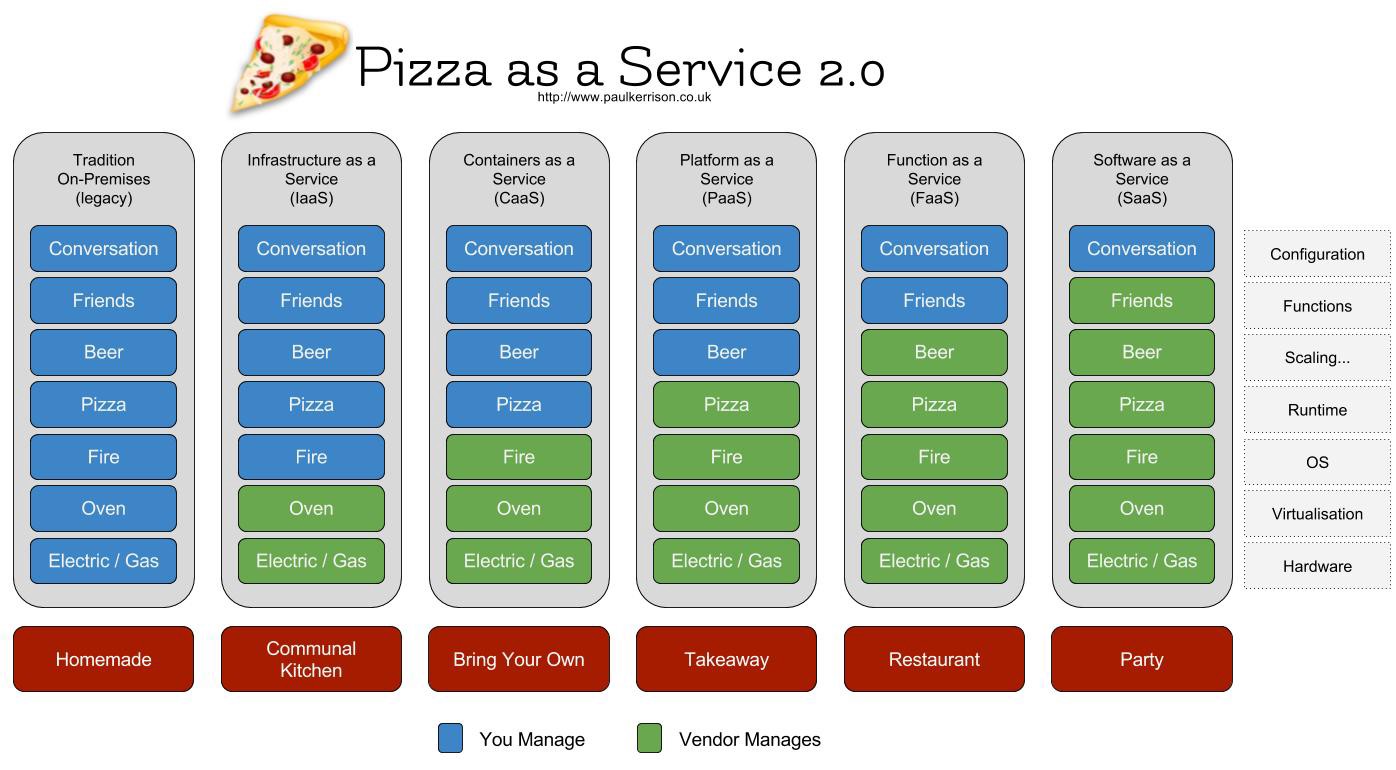
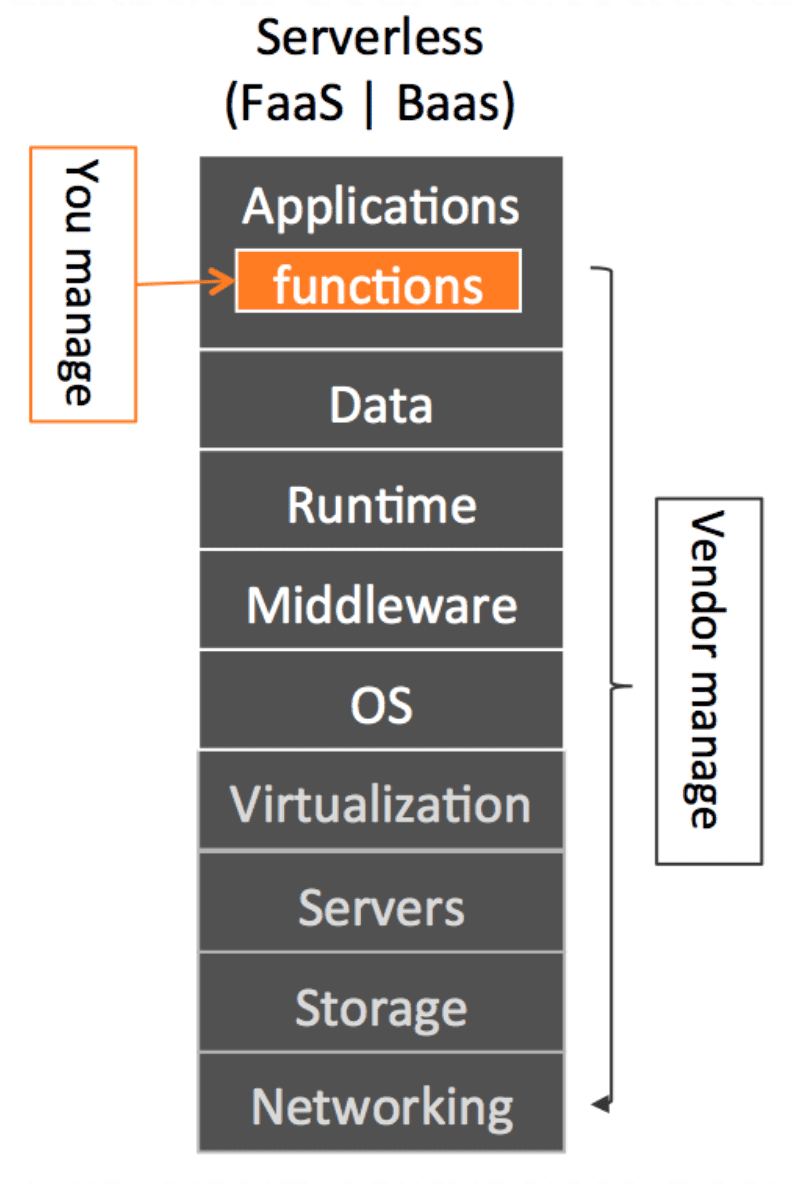
绝大部分应用在云主机或虚拟机上线后,其 CPU 利用率、内存使用率、网络带宽的利用率都非常低,因为你在选购过程中就要为未来新增的流量做好缓冲,你的服务一旦 7X24 的上线运行,你就要为这些冗余的运行时产生的费用自掏腰包。我们现如今公司内部的基于私有云架构开发和部署也是如此的问题,都是需要开发者为这些运维相关的技术债务来埋单,有的同学也会经常收到自动监控系统发出的效率低的提示邮件。
Where to Hold React Component Data: state, store, static, and this
With the advent of React and Redux, a common question has emerged:
What should I hold in the Redux store, and what should I save in local state?
在开发 React 和 Redux 项目时,经常会被问到一个问题?
我应该把什么维护在 Redux Store 中?我该在 Local state 中保存什么?
But this question is actually too simplistic, because there are also two other ways you can store data for use in a component: static and this. Let’s go over what each of these, and when you should use them.
When React was first introduced, we were presented with local state. The important thing to know about local state is that when a state value changes, it triggers a re-render. This state can be passed down to children as props, which allows you to separate your components between smart data-components and dumb presentational-components if you chose.
React 刚刚面世之初,我们就注意到 local state。每当 state 值发生变化,都会触发组件重新 render,因此了解 state 是非常重要的。
当前组件的 state 会被当做 props 传递到子组件中,这个 props 允许你在数据组件和描绘型组件之间做出区分。
Your data (the value of the counter) is stored within the App component, and can be passed down its children.
App 组件中数据被储存其中,并可以向子组件进行传递。
Use cases
Assuming your counter is important to your app, and is storing data that would be useful to other components, you would not want to use local state to keep this value. The current best practice is to use local state to handle the state of your user interface (UI) state rather than data. For example, using a controlled component to fill out a form is a perfectly valid use of local state. Another example of UI data that you could store in local state would be the currently selected tab from a list of options.
假设计数器 Couter 对于 App 很重要,并且它正在存储其他组件的重要数据,你不会希望使用 local state 来保存数据的。
目前最佳实践是使用 local state 来处理 UI 的状态,不是使用数据。比如,使用 Controlled Components 去实现一个 form 表单时使用 local state 是非常合理的。
UI 数据的另外一个例子,可以在 local state 中存储备选 options 列表中已选中的选项。
A good way to think about when to use local state is to consider whether the value you’re storing will be used by another component. If a value is specific to only a single component (or perhaps a single child of that component), then it’s safe to keep that value in local state.
Takeaway: keep UI state and transitory data (such as form inputs) in local state.
思考何时使用 local state 一个好方法,是考虑兼顾你正在存储的值是否会被另外一个组件使用到。如果这个值非常明确地只在单一组件(或单一子组件)中出现,那么将它保存在 local state 中就是非常安全的做法。
Takeaway:可以将 UI 状态和临时数据(form 表单输入数据)保存在 local state。
Redux store
Then after some time had elapsed and everyone started getting comfortable with the idea of unidirectional data flow, we got Redux.
With Redux, we get a global store. This store lives at the highest level of your app and passes data down to all children. You connect to the global store with the connect wrapper and a mapStateToProps function.
At first, people put everything in the Redux store. Users, modals, forms, sockets… you name it.
Below is the same counter app, but using Redux. The important thing to note is that counter now comes from this.props.counter after being mapped from mapStateToProps in the connect function, which takes the counter value from the global store and maps it to the current component’s props.
Now when you click on the button, an action is dispatched and the global store is updated. The data is handled outside of our local component and is passed down.
It’s worth noting that when props are updated, it also triggers a re-render—just like when you update state.
当你点击按钮,与此链接的 action 就会被触发,同时全局的 store 就会更新。这样我们本地组件外层的数据就被操作并传递下去。
props 更新是没有副作用的,只有当你更新 state 时才会触发重新渲染。
Use cases
The Redux store is great for keeping application state rather than UI state. A perfect example is a user’s login status. Many of your components will need access to this information, and as soon as the login status changes, all of those components (the ones that are rendered, at least) will need to be re-rendered with the updated information.
Redux is also useful for triggering events for which you need access on multiple components or across multiple routes. An example of this would be a login modal, which can be triggered by a multitude of buttons all across your app. Rather than conditionally rendering a modal in a dozen places, you can conditionally render it at the top-level of your app and use a Redux action to trigger it by changing a value in the store.
Takeaway: keep data that you intend to share across components in store.
Redux 中 store 应该维护应用的数据状态而不是 UI 的状态。用户登录数据状态就是另外一个例子。只要登录状态改变,项目中多数组件将需要访问这个登录信息,随着信息的更新,这些获取到信息更新的组件就都会重新 render。
Redux 通常也用于事件的触发,这些事件可能是横跨多个组件或者横跨多个路由。再以登录模块举例,可以在整个应用中来触发多个事件。你可以在应用的顶层,通过使用 Redux 对 store 进行修改,并使用 action 来触发条件渲染,而不是去不同地方去单独条件渲染。
Takeaway: 可以尝试在跨组件共享数据时,将数据保存进 store 。
this
One of the least utilized features when working with React is this. People often forget that React is just JavaScript with ES2015 syntax. Anything you can do in JavaScript, you can also do in React.
The example below is a functional counter app, similar to the two examples above.
We’re storing the counter value in the component and using forceUpdate() to re-render when the value changes. This is because changes to anything other than state and props does not trigger a re-render.
This is actually an example of how you should not use this. If you find yourself using forceUpdate(), you’re probably doing something wrong. For values for which a change should trigger a re-render, you should use local state or props/Redux store.
我们在组件中存储 counter 的值,并且在这个值发生变化的时候使用 forceUpdate() 去重新渲染。这是由于没有 state 和 props 发生变化,是不会触发组件的重新渲染。
这也是一个实际的非常糟糕地不使用 this 的例子。如果你发现你自己正在使用 forceUpdate() 你就有可能犯了一个错误。期望做到值改变而触发重新 render,就应该使用 local state 或者 props 或者是 Redux store。
Use cases
The use case for this is to store values for which a change should not trigger a re-render. For example, sockets are a perfect thing to store on this.
举个例子,this 所存储的变量发生改变,但并不希望触发重新 render。比如,sockets 就和适合存储在 this 上。
Also, many people don’t realize they’re already using this all the time in their function definitions. When you define render(), you’re really defining this.prototype.render = function(), but it’s hidden behind ES2015 class syntax.
Takeaway: use this to store things that shouldn’t trigger a re-render.
Static methods and properties are perhaps the least known aspect of ES2015 classes (calm down, yes, I know they aren’t really classes under the hood), mostly because they aren’t used all that frequently. But they actually aren’t especially complicated. If you’ve used PropTypes, you’ve already defined a static property.
The following two code blocks are identical. The first is how most people define PropTypes. The second is how you can define them with static.
As you can see, static is not all that complicated. It’s just another way to assign a value to a class. The main difference between static and this is that you do not need to instantiate the class to access the value.
你可以看到,static 并不复杂。他仅仅是给类增加值的另外一种方式。在 static 和 this 之间主要的差异主要是不需要实例化来访问这个值。
const proto = new App(); const proto2 = proto.prototypeProperty // => { baz: "qux" }
const stat = App.staticProperty // => { foo: "bar" }
In the example above, you can see that to get the staticProperty value, we could just call it straight from the class without instantiating it, but to get prototypeProperty, we had to instantiate it with new App().
在上面的例子中,你可以看到获取 staticProperty 静态属性的值,我们仅仅调用 class 中的静态方法即可,并不需要实例化,但是如果想要获取 prototypeProperty 属性,我们就不得不使用 new App() 实例化以后才可以访问到。
Use cases
Static methods and properties are rarely used, and should be used for utility functions that all components of a particular type would need.
PropTypes are an example of a utility function where you would attach to something like a Button component, since every button you render will need those same values.
Another use case is if you’re concerned about over-fetching data. If you’re using GraphQL or Falcor, you can specify which data you want back from your server. This way you don’t end up receiving a lot more data than you actually need for your component.
So in the example component above, before requesting the data for a particular component, you could quickly get an array of required values for your query with App.requiredData. This allows you to make a request without over-fetching.
Takeaway: you’re probably never going to use static.
There is actually another option, which I intentionally left out of the title because you should use it sparingly: you can store things in a module-scoped variable.
There are specific situations in which it makes sense, but for the most part you just shouldn’t do it.
You can see this is almost the same as using this, except that we’re storing the value outside of our component, which could cause problems if you have more than one component per file. You might want to use this for setting default values if the values are not tied to your store, otherwise using a static for default props would be better.
If you need to share data across components and want to keep data available to everything the module, it’s almost always better to use your Redux store.
Takeaway: don’t use module-scoped variables if you can avoid it.
从上面的代码你可以看到与使用 this 很相似,尤其是我们将值存储在了组件之外,如果每个文件有多个组件极有可能产生问题。如果你没有将这个值绑定在 store 上,那你可能很希望使用 this 去设定初始默认值,否则使用 static 来设置默认 props 会更好。
如果你需要跨组件之间共享数据,并且希望将这些数据维持在每一个模块都有效,那么使用 Redux store 会更好。
Takeaway: 如果可以避免的话,不要使用模块作用域的变量。
]]>
<blockquote>
<p>笔者最近在整理前段时间接手的其他团队的 RN 项目代码,在梳理项目中旧代码过程中,对 React 中 State Store Static This 产生疑惑,借此翻译这篇文章解惑,也分享给各位。</p>
</blockquote>
<p>原文 <a href="https://medium.freecodecamp.org/where-do-i-belong-a-guide-to-saving-react-component-data-in-state-store-static-and-this-c49b335e2a00" target="_blank" rel="noopener">https://medium.freecodecamp.org/where-do-i-belong-a-guide-to-saving-react-component-data-in-state-store-static-and-this-c49b335e2a00</a></p>
<p>发表时间 2016-08</p>
<p>作者 <a href="https://medium.freecodecamp.org/@SamCorcos" target="_blank" rel="noopener">Sam Corcos</a></p>
代码的艺术 - 章淼讲座笔记https://beanlee.github.io/posts/Art-Of-Code/2018-10-08T02:41:48.000Z2018-10-08T02:04:33.000Z适合新手和正在努力进阶的高年级同学阅读 :)
工程师的内功修炼
章淼 简介
清华大学计算机博士;百度云前端技术负责人;百度 Golang & Python 技术委员会成员;
笔记
对比 Google 的工程师,国内的工程师写代码的占用时间显然过多了,而不太注重提前设计;Google 工程师们在开始实现某一模块或功能时,会事先在代码库中搜索是否已经有可重用的代码,并且代码库中的代码具有完整的注释和文档。
// The module 'vscode' contains the VS Code extensibility API // Import the module and reference it with the alias vscode in your code below const vscode = require('vscode');
// this method is called when your extension is activated // your extension is activated the very first time the command is executed functionactivate(context) {
// Use the console to output diagnostic information (console.log) and errors (console.error) // This line of code will only be executed once when your extension is activated // 这里的代码将只会在插件激活时执行一次 console.log('Congratulations, your extension "city-aqi" is now active!');
// The command has been defined in the package.json file // 定义在 package.json 中的命令在这里定义 // Now provide the implementation of the command with registerCommand // 提供 registerCommand 来注册实现代码 // The commandId parameter must match the command field in package.json // commandId 参数必须与 package.json 匹配 let disposable = vscode.commands.registerCommand('extension.sayHello', function () { // The code you place here will be executed every time your command is executed // 这里的代码每次执行 这个命令 的时候都会被执行
// Display a message box to the user // 显示信息框 vscode.window.showInformationMessage('Hello World!'); });
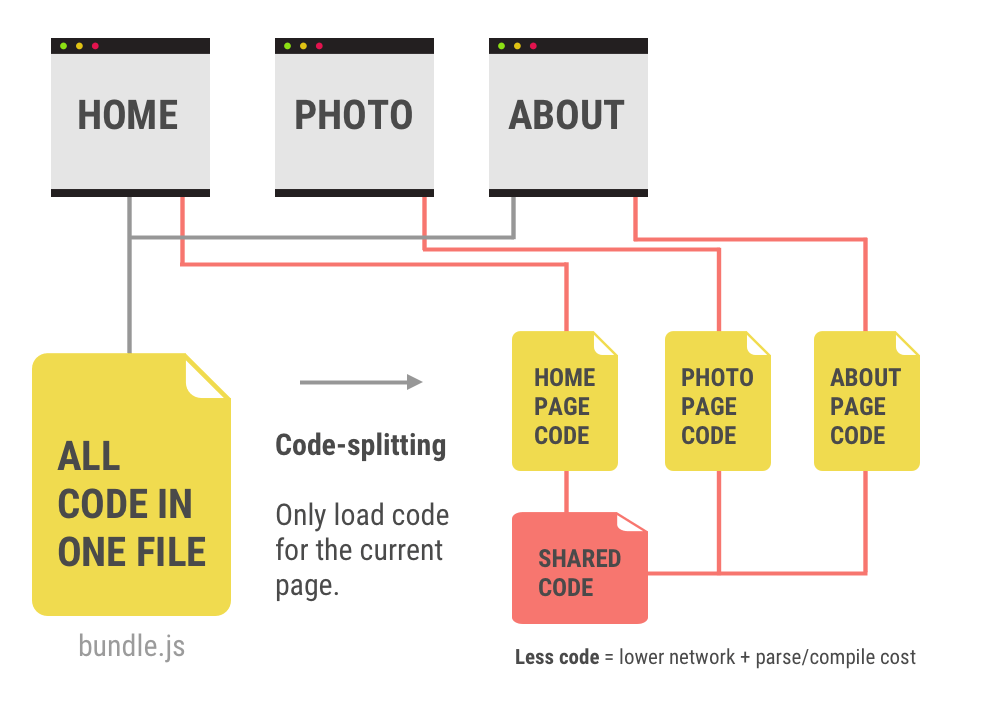
相信提到 Webpack 无论是作为前端工程师,还是 Web 开发者都不会太陌生,它从诞生伊始就收到社区的追捧和大量的生产实践,大量的项目代码构建工具开始选择他作为主力构建工具,究竟它是什么样工具,它的官网是这样描述的:
At its core, webpack is a static module bundler for modern JavaScript applications. When webpack processes your application, it internally builds a dependency graph which maps every module your project needs and generates one or more bundles. 其核心就是现代 Javascript 应用的静态模块构建器。当在应用中运行 Webpack 的时候,它就会在内部构建依赖图来映射项目中的每一个所需要的模块,并生成一个或多个 bundle 文件。
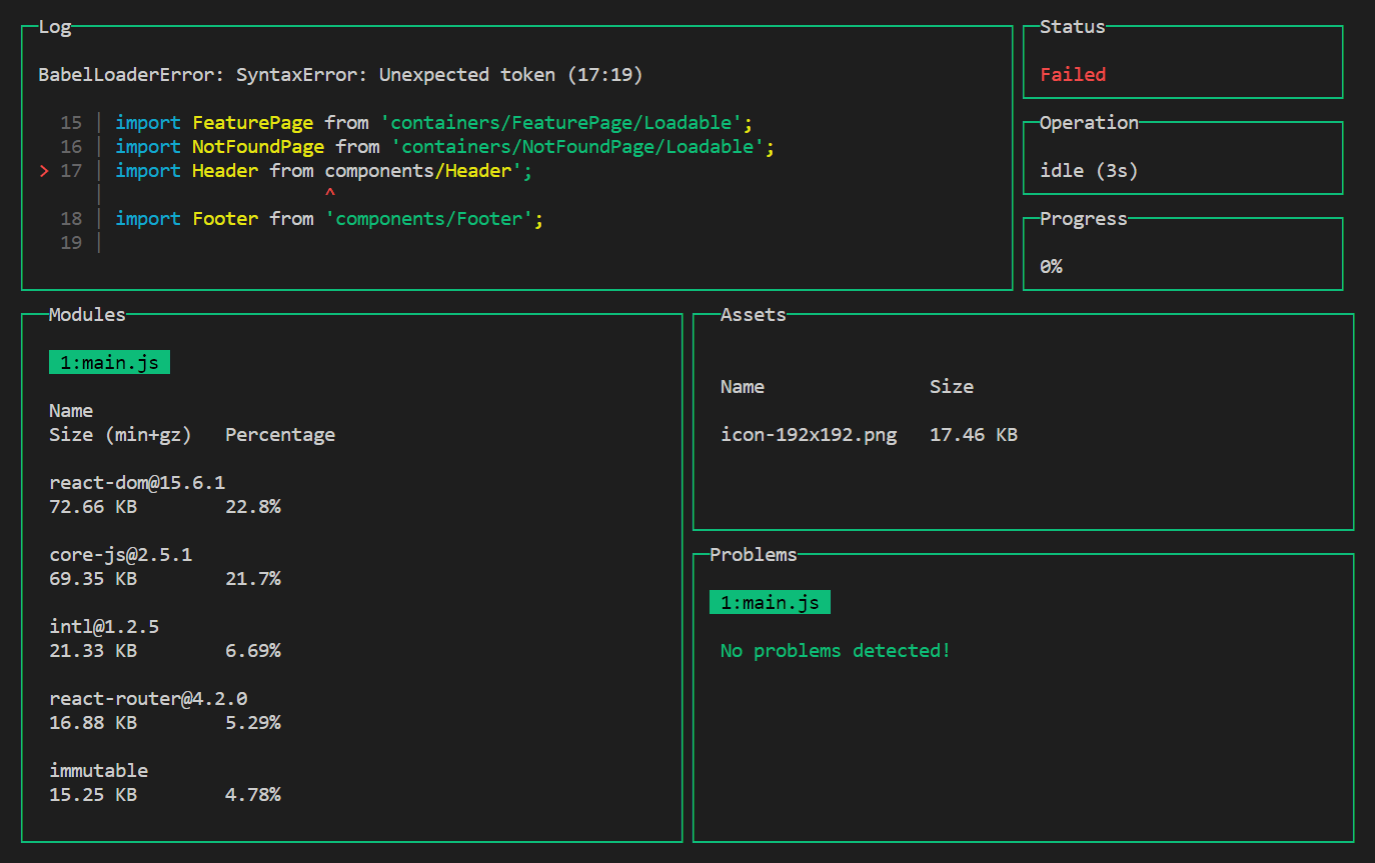
WARNING in configuration The 'mode' option has not been set, webpack will fallback to 'production'for this value. Set 'mode' option to 'development' or 'production' to enable defaults for each environment. You can also set it to 'none' to disable any default behavior. Learn more: https://webpack.js.org/concepts/mode/
// react/cjs/react.development.js // … warning$3( componentClass.getDefaultProps.isReactClassApproved, 'getDefaultProps is only used on classic React.createClass ' + 'definitions. Use a static property named `defaultProps` instead.' ); // …
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif (process.env.NODE_ENV !== 'production') { warn('props must be strings when using array syntax.'); }
↓
1 2 3 4 5 6 7
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif ("production" !== 'production') { warn('props must be strings when using array syntax.'); }
2.与此同时最小化工具会移除掉所有 if 的条件分支 - 由于 "production" !== 'production' 永远会返回 false,这样分支内的代码就永远不会执行:
1 2 3 4 5 6 7
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif ("production" !== 'production') { warn('props must be strings when using array syntax.'); }
↓
1 2 3 4 5
// vue/dist/vue.runtime.esm.js (without minification) if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; }
// bundle.js (part that corresponds to comments.js) (function(n,e){"use strict";var r=function(){return"Rendered!"};e.b=r})
如果他们都是有 ES module 编写,就是与一些库并存时也是生效的。
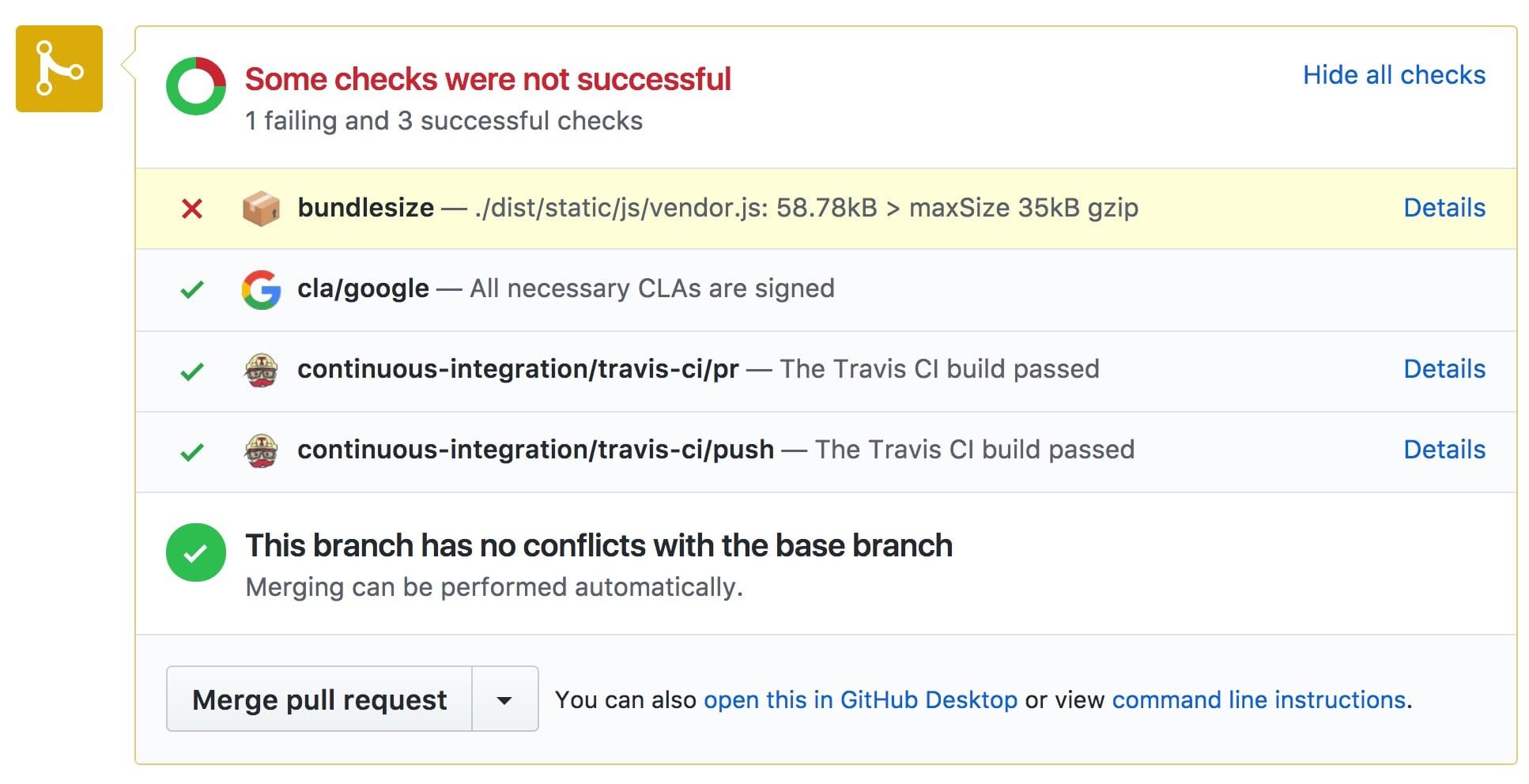
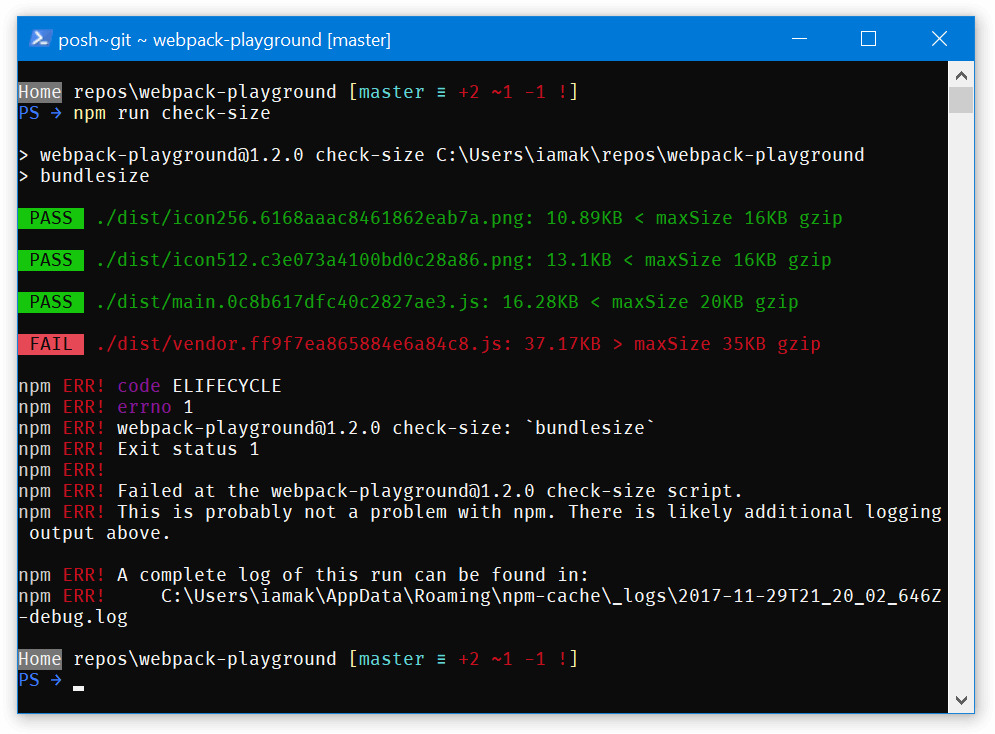
Note: 在 webpack 中,tree-shaking 没有 minifier 是无法生效的。 webpack 仅仅移除了没有被用到的 export 变量;UglifyJSPlugin才会移除无用代码。所以如果你编译打包时没有使用 minifier,打包后体积并不会更小。你也可以不一定使用这个插件。其他最小化的插件也支持移除 dead code(例如:Babel Minify plugin or Google Closure Compiler plugin)
Warning: 不要将 ES module 编译到 CommonJS 中。 如果你使用 Babel babel-preset-env or babel-preset-es2015,检查一下当前的配置。默认情况下, ES import and export to CommonJS require and module.exports。通过设置 option 来禁止掉Pass the { modules: false } option。
// index.js import imageUrl from'./image.png'; // → If image.png is smaller than 10 kB, `imageUrl` will include // the encoded image: 'data:image/png;base64,iVBORw0KGg…' // → If image.png is larger than 10 kB, the loader will create a new file, // and `imageUrl` will include its url: `/2fcd56a1920be.png`
Note: 内联图片减少了独立请求的数量,这是很好的方式(even with HTTP/2),但是会增加 bundle下载和转换的时间和内存的消耗。一定要确保不要嵌入超大图片或者较多的图片 - 否则增加的 bundle 的时间将会掩盖做成内联图片的收益。
// webpack.config.js module.exports = { module: { rules: [ { test: /\.(jpe?g|png|gif|svg)$/, loader: 'image-webpack-loader', // This will apply the loader before the other ones enforce: 'pre', }, ], }, };
// bundle.js (part of) (function(module, exports) { // A module that exports `window.React`. Without `externals`, // this module would include the whole React bundle module.exports = React; }), (function(module, exports) { // A module that exports `window.ReactDOM`. Without `externals`, // this module would include the whole ReactDOM bundle module.exports = ReactDOM; })
// webpack.config.js (for webpack 3) module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ // A name of the chunk that will include the dependencies. // This name is substituted in place of [name] from step 1 name: 'vendor',
// A function that determines which modules to include into this chunk minChunks: module =>module.context && module.context.includes('node_modules'), }), ], };
// This plugin must come after the vendor one (because webpack // includes runtime into the last chunk) new webpack.optimize.CommonsChunkPlugin({ name: 'runtime',
// minChunks: Infinity means that no app modules // will be included into this chunk minChunks: Infinity, }), ], };
// webpack.config.js (for webpack 3) module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ name: 'runtime', minChunks: Infinity, filename: 'runtime.js', // → Now the runtime file will be called // “runtime.js”, not “runtime.79f17c27b335abc7aaf4.js” }), ], };
// webpack.config.js (for webpack 3) module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ // A name of the chunk that will include the common dependencies name: 'common',
// The plugin will move a module into a common file // only if it’s included into `minChunks` chunks // (Note that the plugin analyzes all chunks, not only entries) minChunks: 2, // 2 is the default value }), ], };
// react/cjs/react.development.js // … warning$3( componentClass.getDefaultProps.isReactClassApproved, 'getDefaultProps is only used on classic React.createClass ' + 'definitions. Use a static property named `defaultProps` instead.' ); // …
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif (process.env.NODE_ENV !== 'production') { warn('props must be strings when using array syntax.'); }
↓
1 2 3 4 5 6 7
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif ("production" !== 'production') { warn('props must be strings when using array syntax.'); }
// vue/dist/vue.runtime.esm.js if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; } elseif ("production" !== 'production') { warn('props must be strings when using array syntax.'); }
↓
1 2 3 4 5
// vue/dist/vue.runtime.esm.js (without minification) if (typeof val === 'string') { name = camelize(val); res[name] = { type: null }; }
// bundle.js (part that corresponds to comments.js) (function(n,e){"use strict";var r=function(){return"Rendered!"};e.b=r})
如果他们都是有 ES module 编写,就是与一些库并存时也是生效的。
Note: 在 webpack 中,tree-shaking 没有 minifier 是无法生效的。 webpack 仅仅移除了没有被用到的 export 变量;UglifyJSPlugin才会移除无用代码。所以如果你编译打包时没有使用 minifier,打包后体积并不会更小。你也可以不一定使用这个插件。其他最小化的插件也支持移除 dead code(例如:Babel Minify plugin or Google Closure Compiler plugin)
Warning: 不要将 ES module 编译到 CommonJS 中。 如果你使用 Babel babel-preset-env or babel-preset-es2015,检查一下当前的配置。默认情况下, ES import and export to CommonJS require and module.exports。通过设置 option 来禁止掉Pass the { modules: false } option。
// index.js import imageUrl from'./image.png'; // → If image.png is smaller than 10 kB, `imageUrl` will include // the encoded image: 'data:image/png;base64,iVBORw0KGg…' // → If image.png is larger than 10 kB, the loader will create a new file, // and `imageUrl` will include its url: `/2fcd56a1920be.png`
Note: 内联图片减少了独立请求的数量,这是很好的方式(even with HTTP/2),但是会增加 bundle下载和转换的时间和内存的消耗。一定要确保不要嵌入超大图片或者较多的图片 - 否则增加的 bundle 的时间将会掩盖做成内联图片的收益。
// webpack.config.js module.exports = { module: { rules: [ { test: /\.(jpe?g|png|gif|svg)$/, loader: 'image-webpack-loader', // This will apply the loader before the other ones enforce: 'pre', }, ], }, };
// bundle.js (part of) (function(module, exports) { // A module that exports `window.React`. Without `externals`, // this module would include the whole React bundle module.exports = React; }), (function(module, exports) { // A module that exports `window.ReactDOM`. Without `externals`, // this module would include the whole ReactDOM bundle module.exports = ReactDOM; })
// webpack.config.js module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ // A name of the chunk that will include the dependencies. // This name is substituted in place of [name] from step 1 name: 'vendor',
// A function that determines which modules to include into this chunk minChunks: module =>module.context && module.context.includes('node_modules'), }), ], };
// This plugin must come after the vendor one (because webpack // includes runtime into the last chunk) new webpack.optimize.CommonsChunkPlugin({ name: 'runtime',
// minChunks: Infinity means that no app modules // will be included into this chunk minChunks: Infinity, }), ], };
// webpack.config.js module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ name: 'runtime', minChunks: Infinity, filename: 'runtime.js', // → Now the runtime file will be called // “runtime.js”, not “runtime.79f17c27b335abc7aaf4.js” }), ], };
// webpack.config.js module.exports = { plugins: [ new webpack.optimize.CommonsChunkPlugin({ // A name of the chunk that will include the common dependencies name: 'common',
// The plugin will move a module into a common file // only if it’s included into `minChunks` chunks // (Note that the plugin analyzes all chunks, not only entries) minChunks: 2, // 2 is the default value }), ], };