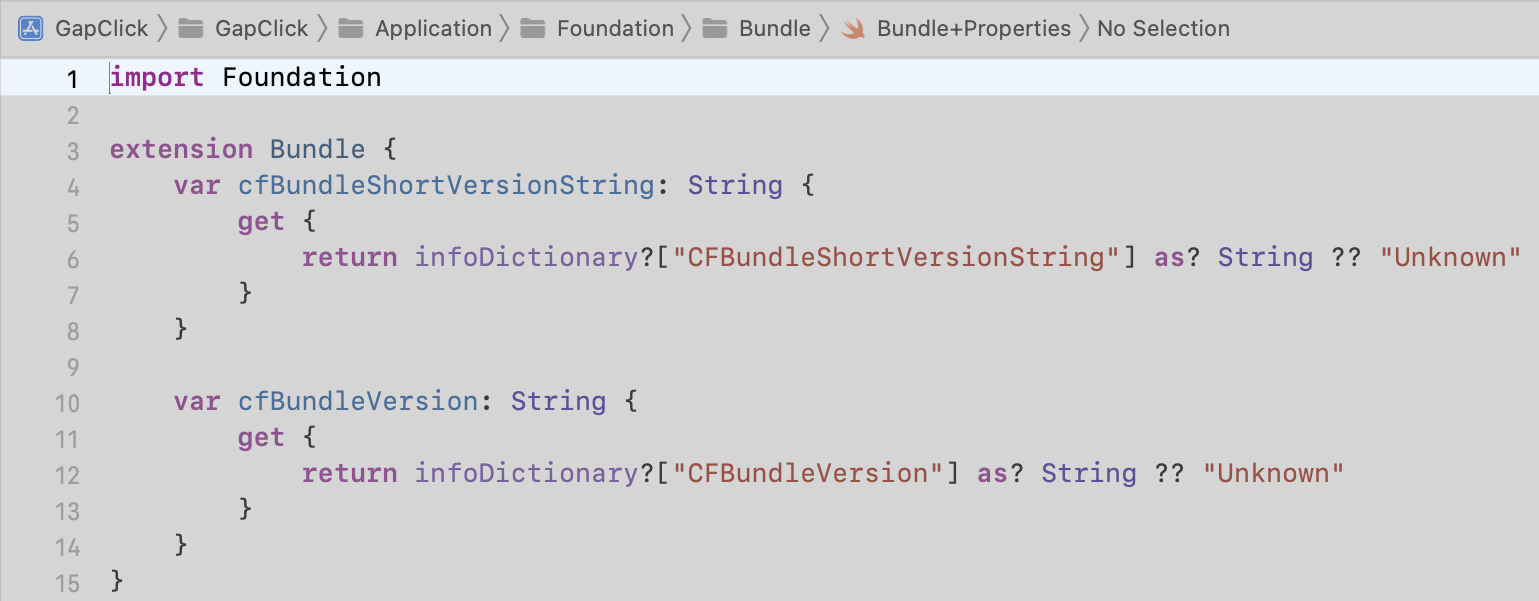
- Writing your platform-dependent code for iOS or Android requires first understanding the platform API dependencies to help you craft a shared platform-independent interface.
- Isolate platform dependencies to the smallest surface area possible to increase maintainability and reusability.
- Leveraging Dependency Injection (DI) and the Dependency Inversion Principle (DIP) is key to effective multiplatform programming.
- We can use UML class diagrams as a tool to illustrate the relationship between the platform-dependent code (the low-level components) and the responsibilities of the shared platform-independent interface (the high-level blueprint).
The Holy Grail of Mobile Development
For as long as mobile development has existed with multiple platforms, the “holy grail” of being able to share code between platforms has been elusive. Additionally, the number of tools already in the graveyard (or on their way there) is steadily increasing, with Kotlin Multiplatform being one of the first to allow sharing code in effectively the same ecosystem while maintaining the ability to access native features as needed. Yet, programmatically one of the biggest challenges is how to accomplish this in a way that is easy to maintain while maximizing the amount of code you can share.
This post will walk you through the steps to identify and isolate platform-dependent code in your app to maximize the amount of code you can share between iOS and Android. Better yet, whether you consider yourself an iOS or Android engineer, you can learn and deploy this technique in your applications today.
This post is part of a series on Kotlin Multiplatform:
- The iOS Engineer’s Guide to Beginning Kotlin Multiplatform Development
- Why iOS Engineers Should Avoid This Glorified KMM Technique
- The Art of Multiplatform Programming: The Secret to Maximizing Shared Code
Isolating Platform-Dependent Code, Step by Step
There are only four simple steps to understand, isolate, and implement a platform dependency in your multiplatform application:
- Understand the platform-dependent APIs that you need to implement.
- Define the interface needed to satisfy your requirements using only platform-independent types.
- Create a concrete class implementing this interface using Swift inside your iOS app.
- Create a concrete class implementing this interface using Kotlin inside your Android app.
Haptic Feedback
Haptic feedback is a fantastic example. It’s simple to understand and practical when dealing with multiple platforms because it requires calling platform-specific APIs.
Use-Case
We want to provide haptic feedback (device vibration) to the user when they perform an action in our application.
Step #1: Understand Platform-Dependent APIs
As the last blog post mentioned, crafting a platform-independent API is a challenging part of multiplatform development. Understanding how the implementation looks on all the platforms you’re aiming to support is an essential first step to deciding on what your shared platform-independent interface will be.
iOS Platform-Dependent APIs
In iOS, we can use any concrete class that implements the UIFeedbackGenerator interface to provide haptic feedback to the user. As Apple’s documentation indicates, we simply initialize and prepare the generator and then trigger the feedback when needed.
NOTE: Haptic APIs vary depending upon what version of iOS you’re supporting, so please dig into this further if you need to implement this functionality. 📚
An example of triggering haptic feedback on iOS might look like this:
1
2
3
let selectionFeedbackGenerator = UISelectionFeedbackGenerator()
selectionFeedbackGenerator.prepare()
selectionFeedbackGenerator.selectionChanged()
From this code, we can discern that besides having to create an instance of UISelectionFeedbackGenerator, there are no other platform-specific dependencies to execute this code.
Android Platform-Dependent APIs
For Android, so far as I understand, one way to access haptic feedback API is from the activity’s Window object. In addition, there are many HapticFeedbackConstants available for you to choose from.
An example of triggering haptic feedback on Android might look like this:
1
2
3
4
window
?.decorView
?.rootView
?.performHapticFeedback(HapticFeedbackConstants.CLOCK_TICK)
Is there a better way to do this on Android? Do you have a recommendation based on the varying API levels? Let me know!
Pro-Tip #1: Encapsulate Platform-Dependent APIs
This example raises a common question regarding multiplatform development: how do I handle platform-dependent APIs?
The answer to this is straightforward but requires a shift in mindset to become proficient with:
Inject platform-dependent objects
into concrete instances
conforming to a platform-independent interface
(No worries if you read that sentence three or four times, and it still doesn’t make sense… it will soon enough!)
Discussing how to accomplish this opens the door for us to explore two topics crucial to becoming comfortable with multiplatform development: dependency injection (DI) and the Dependency Inversion Principle (DIP).
Dependency Injection in Five Sentences or Fewer
DI is simply the act of passing an instance of an object into another object as opposed to creating dependent objects inside an object.
The following Swift example returns a new UserModel object and generates the user id as a new random UUID directly inside the function (line #4).
1
2
3
4
5
6
7
8
class UserRepository {
func createUser(username: String) -> UserModel {
return UserModel(
id: UUID().uuidString,
username: username
)
}
}
With dependency injection, we modify the above code to inject the object responsible for generating the UUID, so neither the createUser() method nor the UserRepository is accountable for this logic:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class UserRepository {
private let uuidProvider: UUIDProvider
init(uuidProvider: UUIDProvider) {
self.uuidProvider = uuidProvider
}
func createUser(username: String) -> UserModel {
return UserModel(
id: uuidProvider.randomUUID,
username: username
)
}
}
The UUIDProvider protocol (interface) is defined separately and implements generating a random UUID in the same way as it originally was, only now it is isolated into its own object:
1
2
3
4
5
6
7
8
9
10
11
protocol UUIDProvider {
var randomUUID: String { get }
}
final class RandomUUIDProvider: UUIDProvider {
var randomUUID: String {
get {
return UUID().uuidString
}
}
}
At its most basic level, dependency injection externalizes the creation of any objects used by an object.
In this case, the UserRepository calls a method on the UUID object. We can also say the UserRepository uses UUID or the UserRepository depends upon UUID.
Identifying what objects a block of code depends upon is crucial to leveraging dependency injection.
When and How to Preform Dependency Injection
Ideally, we want to inject our dependencies during object creation through the constructor, as this forces the consumer to provide the dependencies at the time of object creation. However, if this isn’t possible, you can also inject dependencies directly into functions or by setting properties.
The benefit we reap, in this case, is isolating platform-specific dependencies. Additionally, another advantage is improved testability.
Dependency Inversion Principle (DIP) in Five Sentences or Fewer
Yes!! Now we’re getting into the fun stuff! 🎉
Representing the “D” of the “SOLID” principles, the Dependency Inversion Principle (DIP) essentially states that an interface defines responsibilities that an object has, or the high-level blueprint, and only the concrete classes that satisfy this interface should contain the implementation details. These are details like what kinds of objects, specifically platform-dependent components, are needed to fulfill that behavior.
Typical Applications of the DIP
You have likely already seen many DIP examples where object wrappers are used for third-party code to protect oneself from the details of that API leaking into your application. Yet, when engineers don’t take the appropriate precautions to protect themselves and their teams against third-party code, that code can pollute other parts of your codebase and result in a “leaky abstraction.”
This mistake is often easily made when dealing with third-party code because the compiler won’t inform you when you’ve violated this heuristic.
However, it’s nearly impossible to make this mistake when working with multiple platforms because you can’t even use platform-dependent objects in your shared code. You cannot use these objects because they are inaccessible.
As a result, it can be quite frustrating to integrate with platform-specific dependencies in multiplatform projects if you cannot recognize this limitation. In fact, this challenge is one of the most difficult to overcome with multiplatform programming.
Once you wrap your head around this concept (believe me, if I can do it, then I know you can!), you’re well on your way to mastering multiplatform development.
Overcoming this challenge benefits not only your multiplatform programming skills but also your general programming skills. You’ll also start to see how this can benefit your testing skills.
Step #2: Define the Platform-Independent Interface
Your multiplatform interfaces define the responsibilities of your object and must be platform-independent.
In other words, the interface must only include:
- platform-independent primitive types (strings, integers, floats, etc)
- types supported across all of your supported platforms (such as those defined in libraries with multiplatform support, for example kotlinx.datetime), or
- objects composed only of these types
Sometimes it’s easy to know when a type is platform-dependent, for example, anything in iOS beginning with “UI,” such as UIApplication or UIViewController. Sometimes this is more difficult to discern, like a URL or UUID.
(Note that this requirement also applies when defining expect/actual classes.)
Defining Our (Platform-Independent) Haptics Interface
Let’s say we want two different vibrations depending on the user’s action. Naming is hard, so I’ll leverage musical terminology to devise an appropriately named interface in this case. One haptic will be a shorter, more staccato style feedback, and another will be a slightly longer, more marcato style feedback. The interface might look like this:
1
2
3
4
interface HapticFeedbackGenerator {
fun staccatoFeedback()
fun marcatoFeedback()
}
This interface is the high-level blueprint.
Let’s notice a few important points about this interface:
- The interface only describes the object’s supported behaviors
- Nothing in this interface is dependent upon any platform details
Thus, when working with this object in our code, there’s no need to indicate anything related to a platform. Instead, we invoke a function and expect it is handled appropriately within the platform-dependent code:
1
2
3
4
5
6
class SomePresenter(...) {
fun didTapSomeButton() {
// Handle the user interaction...
hapticFeedbackGenerator.staccatoFeedback()
}
}
This example showcases the beauty of writing code in Kotlin Multiplatform: when writing code common to any platform, you don’t need to be concerned with the implementation details. Once you have written the platform-dependent HapticFeedbackGenerator classes, objects that conform to that interface can be used freely in shared code.
(Of course, this object can be used inside Swift, too, if you have a use case where you need haptics in iOS but not Android.)
Step #3: Concrete Implementation using Swift for iOS
In iOS, we can use two different classes that implement the UIFeedbackGenerator interface to give the user various kinds of haptic feedback.
We can initialize and prepare these generators in the initializer of our object so the feedback can be triggered when needed. Since we can instantiate these objects on their own, there’s no need to inject them into this class.
NOTE: This is just one example of how we could implement this. Haptic APIs differ depending on what version of iOS you are targeting.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class DarwinHapticFeedbackGenerator: HapticFeedbackGenerator {
private let selectionFeedbackGenerator: UISelectionFeedbackGenerator
private let impactFeedbackGenerator: UIImpactFeedbackGenerator
init() {
selectionFeedbackGenerator = UISelectionFeedbackGenerator()
selectionFeedbackGenerator.prepare()
impactFeedbackGenerator = UIImpactFeedbackGenerator()
impactFeedbackGenerator.prepare()
}
func staccatoFeedback() {
selectionFeedbackGenerator.selectionChanged()
}
func marcatoFeedback() {
impactFeedbackGenerator.impactOccurred()
}
}
New-Up and Use/Inject in Your iOS App
Our app likely has an object to manage user interactions. Therefore we can new up an instance of our DarwinHapticFeedbackGenerator and pass it in as needed:
1
2
let hapticFeedbackGenerator = DarwinHapticFeedbackGenerator()
let presenter = SomePresenter(hapticFeedbackGenerator: hapticFeedbackGenerator)
Step #4: Concrete Implementation using Kotlin for Android
As we saw above, the Android implementation depends on the Window object. Therefore, the AndroidHapticsFeedbackGenerator can take this dependency in the object’s constructor.
If you just thought to yourself, “isn’t this constructor dependency injection?” you’d be absolutely right! 👏🏻
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class AndroidHapticsFeedbackGenerator(
private val window: Window?
) : HapticFeedbackGenerator {
override fun staccatoFeedback() {
window
?.decorView
?.rootView
?.performHapticFeedback(HapticFeedbackConstants.CLOCK_TICK)
}
override fun marcatoFeedback() {
window
?.decorView
?.rootView
?.performHapticFeedback(HapticFeedbackConstants.CONTEXT_CLICK)
}
}
New-Up and Use/Inject in Your Android App
As with iOS, you’ll need to instantiate this in Kotlin within your application and inject it. Injecting the Window object we need from the Activity when creating this class allows us to invoke methods on it when needed.
1
2
val hapticFeedbackGenerator = DefaultHapticsFeedbackGenerator(window)
val presenter = SomePresenter(hapticFeedbackGenerator)
You can choose to create and inject your dependencies manually, or there are also DI frameworks, such as Koin and Kodein, that you can consider.
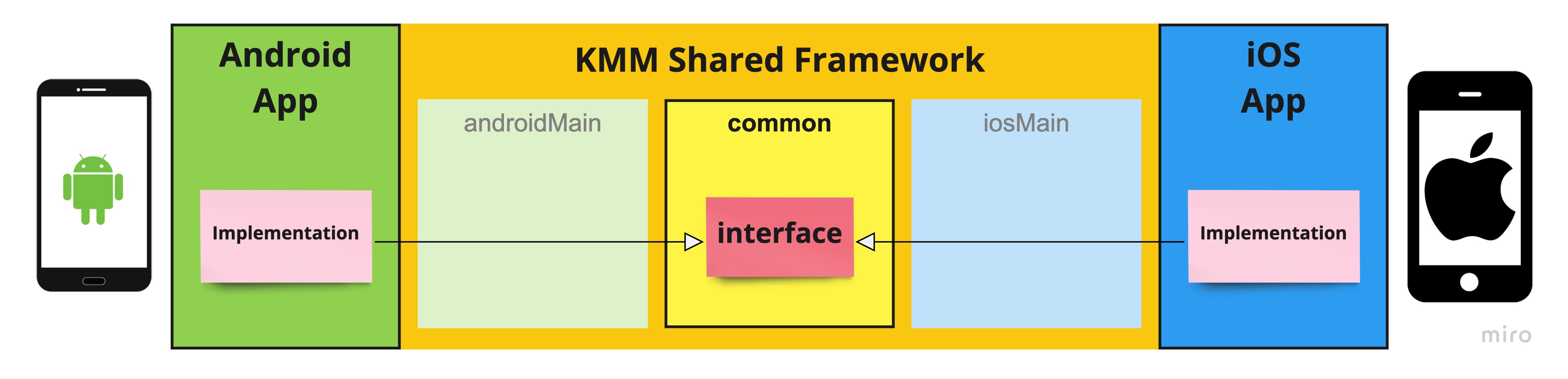
Pro-Tip #2: Visualize Platform-Dependent Objects to Illuminate Relationships
Hopefully, it’s clear from this example that your multiplatform concrete classes are a platform-dependent implementation.
As the Dependency Inversion Principle describes:
- Depend on an interface abstraction (a high-level blueprint)
- The abstracted interface (high-level blueprint) is independent of the implementation details (the low-level components)
- Depend in the direction of stability
Let’s draw a simple class diagram to illustrate this.
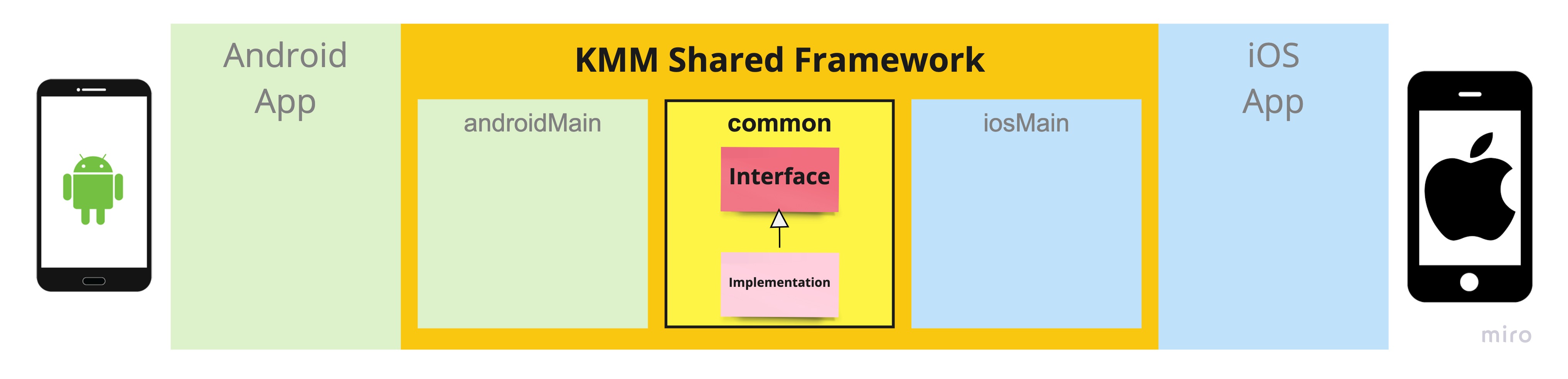
We have a platform-independent interface defined to manage haptics in our shared framework:

We’ll also have two implementations of this class: one for Android and one for Apple (Darwin) platforms:

Need a quick review of reading UML class diagrams?
- The white arrow head points from a concrete class to the interface it implements. You can read this arrow as: “is a.”
- For example:
- “The
AndroidHapticFeedbackGeneratoris aHapticFeedbackGenerator.” - “The
DarwinHapticFeedbackGeneratoris aHapticFeedbackGenerator.”
- “The
The objects needed to implement the concrete classes are dependent upon platform-specific APIs. We want to honor encapsulation, so these will be private for each implementation. These are the low-level components. Let’s add these to the diagram to see how this would look:

Need a quick review of reading UML class diagrams?
- The solid black arrow points from an object to an object it holds an instance of. You can read this arrow as: “has a.”
- For example:
- “The
AndroidHapticFeedbackGeneratorhas aWindow.” - “The
DarwinHapticFeedbackGeneratorhas aUISelectionFeedbackGeneratorand has aUIImpactFeedbackGenerator.”
- “The
Any object can use our HapticFeedbackGenerator in our shared framework, such as SomePresenter, simply by injecting a concrete implementation. And SomePresenter doesn’t need to be concerned about platform-specific APIs.
In the following diagram, SomePresenter has a HapticFeedbackGenerator.

Take note of the direction the arrows are pointing and what is pointing to what. UML class diagrams are a great tool to visualize dependencies between objects.
Comprehending the DIP
Another way I like to think about the DIP is “to depend on that which provides stability.” In our case, the high-level blueprint, which we have created and is entirely within our control, is stable because we have defined it.
To deepen our comprehension, we can also say the opposite: “do not depend on that which does not provide stability.” The low-level components, in our case being platform-specific APIs, are entirely outside our control. If we were to depend upon these platform-specific APIs in our abstract blueprint, any changes to these platform APIs would impact our blueprint.
“But what happens when Google or Apple changes an API we depend on?” you might ask. Naturally, the respective concrete implementation that satisfies the interface will need to change. However, anything outside of that scope is under the protection of the interface.
Revisiting the Solution to Platform-Dependent APIs
Earlier, we asked: “How do I handle platform-dependent APIs?” and answered with the following:
Inject platform-dependent objects
into concrete instances
conforming to a platform-independent interface
In the haptics example, we are:
injecting a
Window(a platform-dependent object)
into anAndroidHapticFeedbackGenerator(a concrete instance)
conforming to theHapticFeedbackGenerator(platform-independent) interface
This example illustrates how we isolate a platform dependency to the smallest possible surface area.
Tradeoffs
The primary benefit of isolating platform-dependent code behind a platform-independent interface is any code that utilizes these components can be oblivious to platform-specific details and thus shared throughout the codebase.
Of course, a natural result is the added indirection when working with these components. This is a reasonable tradeoff, given the benefit of supporting multiple platforms. Additionally, the more limited and isolated the platform-dependent code is, the easier it is to maintain and troubleshoot.
If something were to change within Apple or Google’s haptics APIs, we would only have a single location that would need to be updated. Therefore, the rest of our application code is protected from these changes.
Summarizing
- We created a platform-independent interface, the high-level blueprint, for how we want our application to interact with haptics.
- We defined platform-specific Android and iOS concrete class implementations that utilize platform-specific APIs. These are the low-level components.
- These concrete platform-specific implementations are injected into the object(s) that need to use them and can be called from shared code without concern about which platform uses it.
- Understanding how to employ the Dependency Injection (DI) technique and applying the SOLID Dependency Inversion Principle (DIP) are critical to isolating platform dependencies.
- Drawing UML class diagrams to illustrate relationships between these objects is a valuable tool to deepen our understanding of how these objects relate to each other.
Would you like to see more real-world examples of isolating platform dependencies? Do you have unresolved challenges with Kotlin Multiplatform development? Would more examples of dependency injection or dependency inversion be useful? Let me know how I can help. 👍🏻
]]>