Dans l’optique de faire un jeu style point and click sur navigateur, nous avons du dessiner et animer un personnage, et développer en Javascript son mouvement pour qu’il suive la souris.
Ce sont que des nouvelles méthodes et outils que nous avons découverts. Je vais montrer dans cet article comment nous avons réalisé la première étape de notre jeu, …
TL;DR:
L‘exemple ci-dessus est le rendu de la première étape qui a été d‘animer un personnage dans un navigateur, et de le lui faire suivre le pointeur (souris ou doigt).
Cette première étape qu‘on a pu accomplir après plusieurs recherches et essais, c‘est justement l‘objet de cet article. Je vais parler :
- des librairies Javascript utilisées
- des logiciels d‘animation testé et ceux que j‘ai retenus
- de l‘animation de notre personnage
- de la lecture des animations dans le navigateur.
Mais avant tout, comment animer un personnage ?
La première solution à laquelle j‘ai pensé a été de dessiner plusieurs images d‘un personnage avec à chaque fois un décalage des jambes. En affichant les images à la suite, ca animerait le personnage à la façon d‘un flip book.

En cherchant sur Internet si une librairie le faisait déjà, je suis tombé au hasard sur le site de Spine qui propose une solution totalement différente, ainsi que sur sa page de démo, assez auto-explicative :
http://fr.esotericsoftware.com/spine-demos
Les exemples sont très convainquant, on comprend vite l‘idée, et m‘a directement fait oublier la solution du flip book.
L‘idée est de ne pas dessiner tous les états du personnage, mais de le découper en segments pour chaque parties du corps, de les assembler comme un pantin, et ensuite de le faire marcher, courir, attendre…
Cette solution donne beaucoup d‘avantages :
- Pas besoin de dessiner plusieurs fois le même personnage
- Les segments du corps sont réutilisable pour toutes les marches
- Beaucoup moins d‘images à télécharger donc optimale pour le web
Et encore d‘autres avantages, comme la déformation de maillage qui m‘a complètement séduit, concept illustré par cet exemple précis : http://fr.esotericsoftware.com/spine-demos#Mesh-deformations
La déformation de maillage permet de déformer une même image pour la tordre. On peut la tordre d‘une facon qui donne une impression de 3D, comme montré dans cet exemple. Mais je m‘en suis servi pour faire plier une jambe, ce qui m‘a permi de ne pas la séparer en 3 (fémur, tibia, pied), ou encore de faire plier une écharpe pour la faire pendre et lui donner une impression de flotte-au-vent.
Les logiciels testés et ceux que j‘ai finalement utilisés
En ce qui concerne le moteur de rendu Javascript, j’ai suivi les tutoriaux de Three.js et pixi.js pour au final choisir cette dernière, car l’API me semblait plus simpe de ce côté.
J’ai aussi découvert DragonBones, ainsi que son moteur Javascript en open-source (MIT) et son intégration à pixi.js. C’est tout trouvé, je vais utiliser pixi.js et l’intégration de DragonBonesJS à pixi.js.
Il me reste plus qu’a trouver le logiciel d’animation qui me permettrait d’animer mon personnage et d’exporter les sprites et animations au format attendu par DragonBonesJS.
Logiciels d‘animation pour pixi.js
Je parlais tout à l‘heure de Spine, ca tombe bien, c‘est le logiciel que je n‘ai pas utilisé pour faire marcher notre personnage !
Si je n‘ai pas utilisé Spine, c‘est principalement parce que c‘est un logiciel propriétaire, et que tout ce que j‘apprendrai dessus ou l‘aide que je pourrais éventuellement apporter aux autres sur ce logiciel serait en quelque sorte une contribution qui ne serait pas vraiment ouverte, mais resterait autour de Spine.
Néanmoins je l‘ai testé, et il donne effectivement envie. La version de test téléchargeable sur le site ne permet pas de sauvegarder ou d‘exporter quoique ce soit, la license personnelle coûte 69$, abordable, mais pas pour un projet experimental.
De plus, j‘ai plus tard découvert qu‘une librairie Javascript que j‘ai failli utiliser (pixi-spine) est sous cette même license fermée, nous obligeant à détenir une license payée pour pouvoir l‘utiliser. De ce fait, tout logiciel exportant des animations sous le même format JSON que Spine afin de réutiliser le moteur est donc inutilisable sans license, même si on n’utilise pas le logiciel Spine… Bref une impasse, cherchons ailleur.
Synfig studio est le premier logiciel que j‘ai testé, il semblait une bonne alternative à Spine mais je n‘ai pas trouvé comment exporter les animations pour les réutiliser dans pixi.js.
DragonBones Pro aurait pu être une piste, il est réalisé par les même personnes qui ont fait le moteur Javascript, et j’aurai pu exporter les animations directement au bon format pour pixi.js/DragonBonesJS, mais le logiciel nécessite de se créer un compte, et de toutes facons ne marche pas sous Linux…
Blender + plugin coa_tools (CutOut Animation) m‘a finalement sauvé. J‘ai eu du mal à trouver ce plugin, mais l‘auteur (Andreas Esau, @ndee85) a mis en ligne des vidéos de présentation de ce plugin, et c‘est finalement ce que j‘ai utilisé.
A propos de Blender
Blender permet de faire une vaste quantité de chose, mais cette polyvalence lui coûte d’être plutôt compliqué aux premiers abords. Cependant j‘ai déjà pu m‘y initier dans le passé, et j’ai maintenant une bonne occasion de l’utiliser à nouveau.
Animation du personnage
La partie qui nous a le plus plu, à part qu’il a d’abord fallu passer par une étape qu’on ne maitrisait pas…
Dessin du personnage
Il a fallu d‘abord dessiner le personnage.
J’ai donc utilisé Krita, un logiciel de dessin qui même quand on sait pas dessiner, donne envie de dessiner quelque chose. C’est un logiciel libre qui fonctionne sous Linux.
Cependant on ne savait pas vraiment dessiner, et c‘était plutôt frustant quand t‘as comme source d‘inspiration :

(Image : https://www.davidrevoy.com/article603/rainy-days)
Et que tout ce que tu peux faire, c‘est :

Et finalement, avec une tablette graphique empruntée, je me suis tourné vers un style pas trop engageant et simple, ce qui est à ma portée, afin de laisser la possibilité d‘améliorer plus tard. Je me suis inspiré des illustrations qu’on peut trouver autour des méthodologies agile/scrum :

C’est donc ce personnage que je vais garder. J’ai bien organisé les calques, j’en ai un pour :
- la tête
- les yeux : on voit ici les yeux ouverts et fermés superposés
- l’écharpe
- le corps
- et un pour chaque jambe.
Je devrais séparer les calques pour ensuite réassembler le personnage en pantin, et permettre à chaque segment de bouger librement.
Animation du personnage sous Blender + coa tools
Cette partie ne sera pas un tutoriel pour animer un personnage avec Blender, cependant je vais montrer les étapes qui illustrent bien l’idée.
Pour animer personnage, je vais devoir :
- importer les segments de mon personnage dessiné dans Blender
- tracer un squelette et lier les os aux bon segments du personnage
- créer les animations de marche et d’inactif
- exporter les animations et sprites pour lire les animations avec Javascript
Création de l’armature
Je vais donc importer les sprites de mon personnage avec le plugin, tracer le squelette dessus, et lier chaque os à la ou les sprites qu’il est censé contrôller :
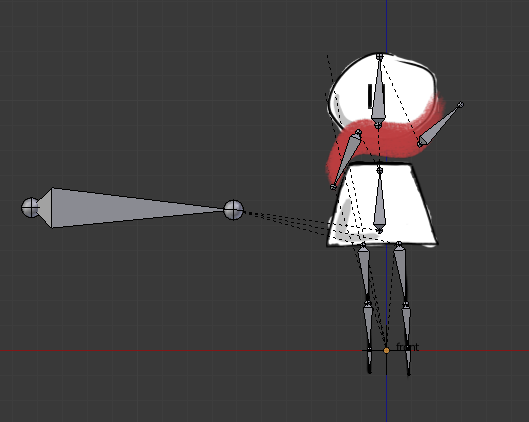
Le plus important ici est que les os sont reliés entre eux avec une relation père/fils, et en faisant pivoter un os, les os fils suivent le mouvement.
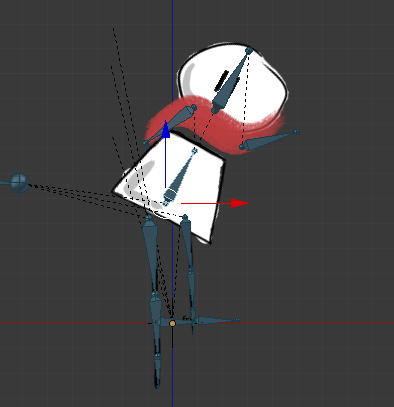
Ce qui va m’aider ensuite à animer un mouvement de tête ou une marche sans devoir contrôller la rotation de tous les os individuellement.
J’ai aussi mis des os sur l’écharpe pour pouvoir la faire bouger.
Animations du personnage
Après avoir affecté tous les os à leurs sprites, je vais pouvoir animer la marche.
Pour cela je dois créer des images clés. Je peux indiquer dans une image clé la position et rotation des os à un moment précis. Ensuite, le plugin va créer les interpolations de mouvement en créant les transitions entre les images clés.
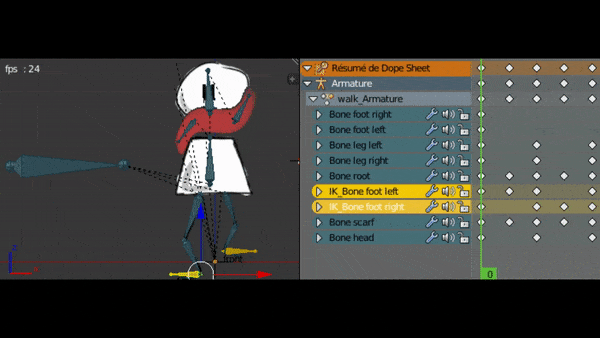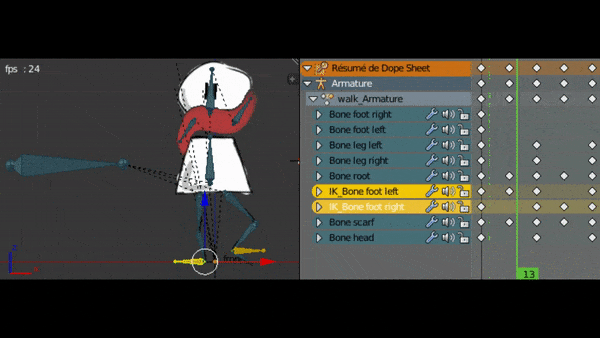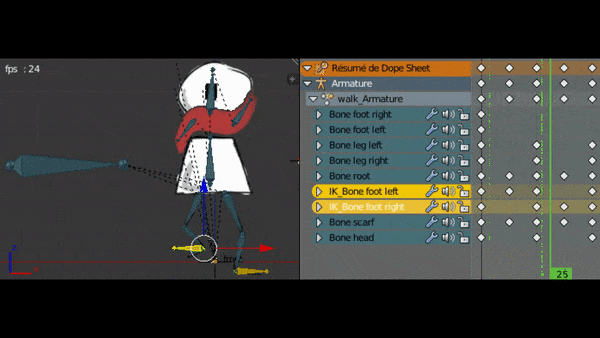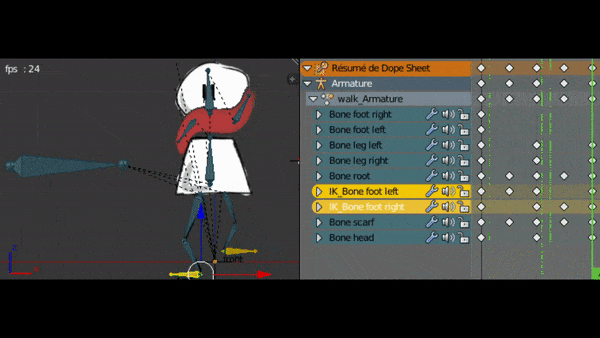
Après avoir ajusté mon animation de marche, je fait aussi l’animation “au repos” qui sera jouée lorsque le personnage ne bouge pas. Ca le rendra plus vivant.
Pour les yeux, j’ai mis les deux sprites (yeux ouverts et yeux fermés) dans un “slot”, un compartiment qui n’affiche qu’une seule sprite à la fois, et permet de choisir la sprite affichée.
Exporter mon animation pour Javascript
Une fois mon animation prête, le plugin coa tools me permet d’exporter toute l’animation au format JSON défini par DragonBones, et donc réutilisable par leur moteur Javascript.
L’export va me génerer :
- une image avec tous les segments dedans,
- un fichier JSON qui indique quel segment est représenté par quel rectangle dans l’unique sprite
- un gros fichier JSON avec l’armature, le placement des os, les animations, les slots…
Ces trois fichiers seront importés par mon application Javascript avec DragonBonesJs.

Un peu plus loin dans Blender + coa tools
Je vais parler de deux détails technique un peu plus avancés par rapport à l’animaion du personnage. Ils ne sont pas nécessaire pour comprendre le reste, mais ils m’ont bien plu.
Kinématique inversée : pour ajouter un comportement naturel aux os
Je disais que les os fils héritent de la position et rotation du parent pour avoir un vrai pantin. Mais pour la marche, je n’ai pas eu à faire plier la jambe et tibia à chaque position.
En configurant une “kinématique inverse”, j’ai pu au contraire placer le pied à la bonne place, et la jambe se plie toute seule, en respectant les contraintes du squelette. Ceci aide encore plus pour animer la marche, tout en donnant un effet très naturel :
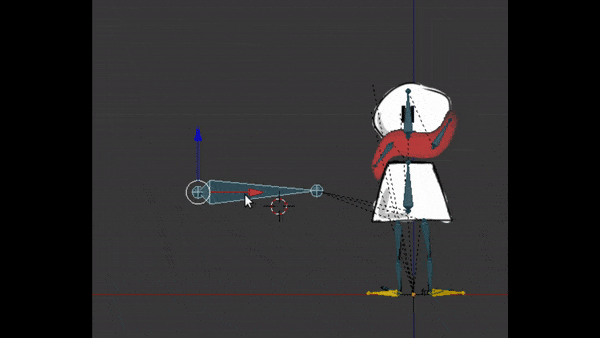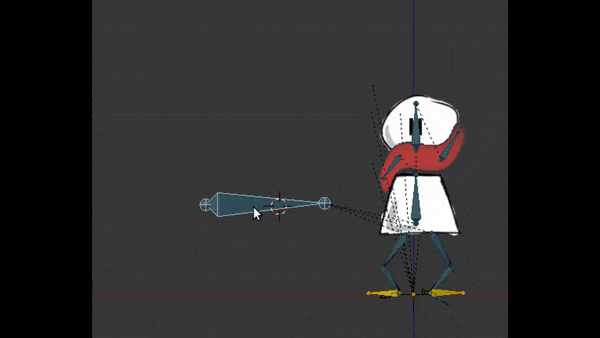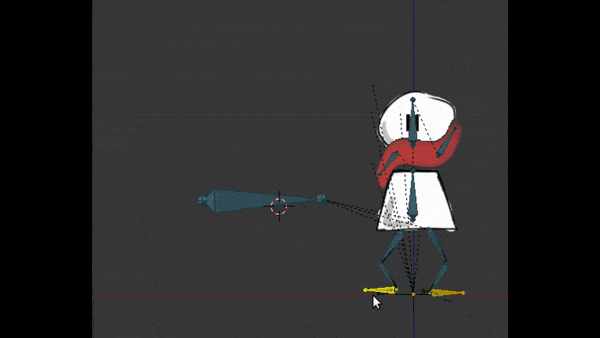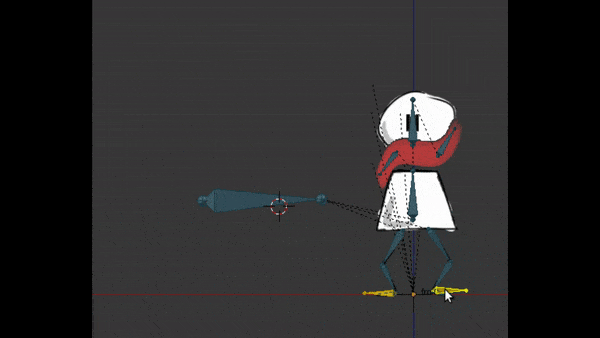
Déformation de maillage : pour faire plier les jambes et faire flotter l’écharpe dans le vent
Lorsque j’ai créé le squelette, vous pouvez remarquer que les trois os d’une jambe contrôllent un même sprite. En effet, la jambe est un unique trait, ca aurait été plus encombrant de séparer les 3 segments de la jambe/pied.
Dans ce cas, je dois assigner plusieurs os à une même sprite, mais alors, comment le logiciel sait comment faire bouger la sprite quand je bouge un des os ?
Par défaut, un os fait pivoter ou déforme pas directement la sprite, mais son “maillage”. Et au début, le maillage d’une sprite contient 4 sommets : les 4 coins de l’image. C’est insuffisant pour déformer l’image avec la précision souhaitée. Par exemple je ne pourrai pas pivoter un bout de l’écharpe, c’est toute l’image qui se redimensionnera.
Il faut donc mailler la sprite, en détourant l’image et en générant un maillage :
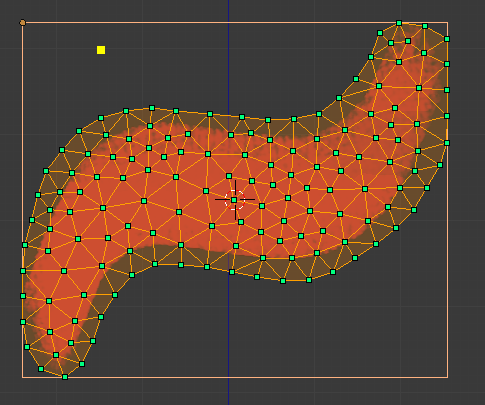
Ensuite, il faut dire quels os contrôlent quelles sommets.
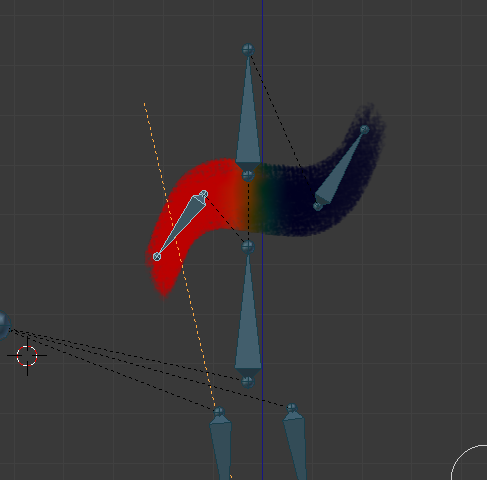
Ici, l’os de gauche contrôle la moitié gauche de l’écharpe, ce qui fait pivoter toute la partie gauche au lieu de bouger simplement le bout. Je dois donc éditer les poids avec un pinceau. J’ai donc réassigné de cette manière :
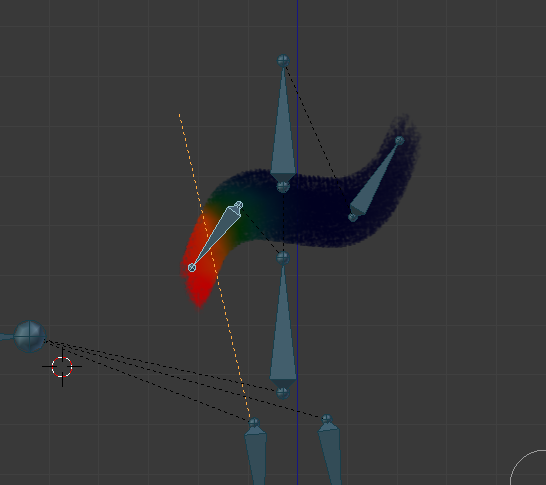
On peut utiliser la déformation de maillage de manière plus précise en redessinant par dessus les traits de la sprite, et affecter des poids de facon à générer de meilleurs rendus avec de simple images 2D. De plus, DragonBonesJs affiche les mêmes déformations dans le navigateur sans aucune lenteur, j’en ai été bluffé. J’en parle d’ailleur dans la prochaine partie.
Lecture des animations dans pixi.js / DragonBonesJS
J’ai donc créé l’animation de mon personnage dans Blender, et l’ai exportée au format DragonBones.
Je vais maintenant l’importer avec le moteur DragonBonesJS, plus précisement avec l’extension PixiJs.
https://github.com/DragonBones/DragonBonesJS/tree/master/Pixi
DragonBonesJs est écrit en TypeScript, et ils ont porté leur moteur pour pouvoir l’utiliser avec plusieurs autres librairies (ThreeJS, Cocos, Egret…). Ca veut dire une chose : je vais devoir me mettre à TypeScript…
Projet DragonBonesJs avec NPM
Pour l’utiliser avec pixi.js, DragonBones propose de cloner leur repository, de copier pixi.min.js dans ce repo, et de partir de cette base. Cela me plaît pas, j’ai plutôt l’habitude de partir d’un repository vide, et d’installer mes dépendances avec NPM. Ca me permet de garder les sources du moteur DragonBonesJs à jour, et de ne pas commiter des sources distantes.
Ca a été compliqué, mais j’ai pu créer mon repository vide avec mon l’environement NPM, TypeScript, et les dépendances pixi.js, DragonBonesJs. J’en ai créé un repo seed, ou skeleton :
https://gitlab.com/Alcalyn/pixi-dragonbones-skeleton
Ce skeleton contient l’environement TypeScript pour développer un projet pixi.js/DragonBonesJS, et le minimum qui permet de faire cette application “Hello World” : https://alcalyn.gitlab.io/pixi-dragonbones-skeleton/.
Importation et lecture de mon animation avec DragonBonesJs
J’ai donc animé mon personnage sous Blender, et ai exporté l’animation vers des fichiers au format DragonBones. J’ai donc mes 3 fichiers que je dois importer, interpreter et m’en servir pour générer l’animation avec Javascript.
Je me sers du Loader de PixiJs qui permet de charger des assets, et du dragonBones.PixiFactory qui permet de générer une animation à partir d’un export DragonBones :
// Add assets path to load
PIXI.loader.add('girl/dragonbones-export/Girl_ske.json');
PIXI.loader.add('girl/dragonbones-export/Girl_tex.json');
PIXI.loader.add('girl/dragonbones-export/Girl_tex.png');
PIXI.loader.once('complete', () => {
const factory = new dragonBones.PixiFactory();
// Parse skeleton and animations
factory.parseDragonBonesData(resources['girl/dragonbones-export/Girl_ske.json'].data);
// Parse sprites images
factory.parseTextureAtlasData(
resources['girl/dragonbones-export/Girl_tex.json'].data,
resources['girl/dragonbones-export/Girl_tex.png'].texture,
);
// Generate armature and prepare animations (walk, idle)
const armature = factory.buildArmatureDisplay('Armature');
// Add armature sprite to the scene
this.addChild(armature);
});
// Load all assets
PIXI.loader.load();
Je peux jouer l’animation walk ou idle que j’avais animé dans Blender :
armature.animation.play('walk');
setTimeout(() => armature.animation.play('idle'), 3000);
Je peux afficher les yeux ouverts ou fermé en récupérant le “slot” que j’avais créé dans Blender :
// Ouverts
armature.armature.getSlot('eyes').displayIndex = 0;
// Fermés
armature.armature.getSlot('eyes').displayIndex = 1;
Et donc j’ai utilisé tous ces outils pour faire marcher la fille jusque là où on clique avec la souris : https://alcalyn.gitlab.io/pixi-dragonbones-skeleton/
Pour faire bouger la fille dans le temps, pixi.js propose un Ticker qui peut appeller une fonction à chaque “tick”. Je m’en suis servir pour déplacer la fille vers la cible (là où l’utilisateur a cliqué), et mettre à jour l’animation (walk si elle était à l’arrêt, idle si elle s’arrête de marcher) :
/**
* Function called at each images per second,
* move girl to target, depending on WALK_SPEED,
* play `walk` or `idle` animation if girl was waiting/walking.
*/
render(deltaTime: number): void {
if (!this.walking) {
return;
}
if (Math.abs(this.x - this.targetX) > this.WALK_SPEED) {
// If target is at right/left
const direction = this.x < this.targetX ? 1 : -1;
this.x += deltaTime * this.WALK_SPEED * direction;
} else if (Math.abs(this.y - this.targetY) > this.WALK_SPEED) {
// If target is just below/above girl
const direction = this.y < this.targetY ? 1 : -1;
this.y += deltaTime * this.WALK_SPEED * direction;
} else {
// If girl is arrived to target
this.x = this.targetX;
this.y = this.targetY;
this.armature.animation.play('idle');
this.walking = false;
}
}
// Register render() in PIXI.ticker
PIXI.ticker.add(deltaTime => render(deltaTime));
L’argument deltaTime correspond au temps depuis le dernier tick par rapport aux images par secondes. Il est en général autour de 1.0, mais si l’animation commence à lagguer, ce dernier sera plus grand car les ticks auront du mal à suivre les images par secondes. Je prend deltaTime en compte ici pour que la fille “rattrape” son retard si l’animation laggue.
Conclusion
Après avoir testé plusieurs outils, j’ai finalement pu trouver une suite d’outils compatibles et libres pour créer une animation avec Javascript :
- Krita pour dessiner
- Blender + coa tools pour animer
- Pixi.js / DragonBonesJS pour développer mon jeu dans un navigateur.
Cet article n’était pas un tutoriel. J’étais finalement content d’avoir pu trouver un angle d’approche vers le monde de l’animation, et voulais faire partager les techniques que j’ai découvertes de mon point de vue de développeur.
Mais si cela vous interesse et souhaitez vous y mettre, voilà les tutoriels/documentations qui m’ont le plus aidé :
- [en] Vidéos de présentation de Blender + coa tools (les premières vidéos sont faites avec une version ancienne du plugin, mais ca aide quand même)
- [fr] Tuto pour créer le squelette et les os de kinématique inverse Ce tuto nous a bien aidé, mais seulement la deuxième moitié, la partie “Préparation de l’Armature et rigging” et après. La première moitié n’est plus à jour, le plugin ayant évolué.
- Exemples de démonstration développés avec DragonBonesJS On peut cloner et installer ce projet, et jouer avec les exemples. Ca m’a servi pour voir des exemples de code DragonBonesJS.

Julien Maulny
]]>